+This choice is not an arbitrary one. It can be mathematically shown that a binary tree of `n` nodes has height of at least `log(n)` (in the case of a complete binary tree). So, it makes intuitive sense to give trees whose heights are roughly in the order of `log(n)` the desirable 'balanced' label.
 @@ -51,8 +46,7 @@ What is important is that this **'good' property holds even after every change**
The 'good' property in AVL Trees is the **height-balanced** property. Height-balanced on a node is defined as
**difference in height between the left and right child node being not more than 1**.
@@ -51,8 +46,7 @@ What is important is that this **'good' property holds even after every change**
The 'good' property in AVL Trees is the **height-balanced** property. Height-balanced on a node is defined as
**difference in height between the left and right child node being not more than 1**. We say the tree is height-balanced if every node in the tree is height-balanced. Be careful not to conflate -the concept of "balanced tree" and "height-balanced" property. They are not the same; the latter is used to achieve the -former. +the concept of "balanced tree" and "height-balanced" property. They are not the same; the latter is used to achieve the former.
Ponder..
@@ -63,8 +57,8 @@ Yes! In fact, you can always construct a large enough AVL tree where their diffe
@@ -73,19 +67,35 @@ Therefore, following the definition of a balanced tree, AVL trees are balanced.
Credits: CS2040s Lecture 9
+### Balance Factor
+To detect imbalance, each node tracks a **balance factor**:
+
+```
+balance factor = height(left subtree) - height(right subtree)
+```
+
+A node is height-balanced if its balance factor is in `{-1, 0, 1}`. When `|balance factor| > 1`, rebalancing is required.
+
+- **Positive** balance factor → left-heavy
+- **Negative** balance factor → right-heavy
+
## Complexity Analysis
-**Search, Insertion, Deletion, Predecessor & Successor queries Time**: O(height) = O(logn)
+**Time:**
+| Operation | Complexity |
+|-----------|------------|
+| Search | `O(log n)` |
+| Insert | `O(log n)` |
+| Delete | `O(log n)` |
+| Predecessor/Successor | `O(log n)` |
+| Single Rotation | `O(1)` |
-**Space**: O(n) -where n is the number of elements (whatever the structure, it must store at least n nodes) +**Space**: `O(n)` where `n` is the number of elements ## Operations -Minimally, an implementation of AVL tree must support the standard **insert**, **delete**, and **search** operations. -**Update** can be simulated by searching for the old key, deleting it, and then inserting a node with the new key. +An AVL tree supports the standard **insert**, **delete**, and **search** operations. +**Update** can be simulated by deleting the old key and inserting the new one. -Naturally, with insertions and deletions, the structure of the tree will change, and it may not satisfy the -"height-balance" property of the AVL tree. Without this property, we may lose our O(log(n)) run-time guarantee. -Hence, we need some re-balancing operations. To do so, tree rotation operations are introduced. Below is one example. +Insertions and deletions can violate the height-balanced property. To restore it, we use **rotations**.
 @@ -93,19 +103,56 @@ Hence, we need some re-balancing operations. To do so, tree rotation operations
Credits: CS2040s Lecture 10
@@ -93,19 +103,56 @@ Hence, we need some re-balancing operations. To do so, tree rotation operations
Credits: CS2040s Lecture 10
-Here is a [link](https://www.youtube.com/watch?v=dS02_IuZPes&list=PLgpwqdiEMkHA0pU_uspC6N88RwMpt9rC8&index=9) -to prof's lecture on trees.
-_We may add a summary in the near future._ - -## Application -While AVL trees offer excellent lookup, insertion, and deletion times due to their strict balancing, -the overhead of maintaining this balance can make them less preferred for applications -where insertions and deletions are significantly more frequent than lookups. As a result, AVL trees often find itself -over-shadowed in practical use by other counterparts like RB-trees, -which boast a relatively simple implementation and lower overhead, or B-trees which are ideal for optimizing disk -accesses in databases. - -That said, AVL tree is conceptually simple and often used as the base template for further augmentation to tackle -niche problems. Orthogonal Range Searching and Interval Trees can be implemented with some minor augmentation to -an existing AVL tree. +### The 4 Rotation Cases +After an insert or delete, we walk back up to the root, checking balance factors. When a node has `|balance factor| > 1`, one of four cases applies: + +| Case | Condition | Fix | +|------|-----------|-----| +| **Left-Left (LL)** | Left-heavy, left child is left-heavy or balanced | Single right rotation | +| **Right-Right (RR)** | Right-heavy, right child is right-heavy or balanced | Single left rotation | +| **Left-Right (LR)** | Left-heavy, left child is right-heavy | Left rotate left child, then right rotate node | +| **Right-Left (RL)** | Right-heavy, right child is left-heavy | Right rotate right child, then left rotate node | + +
+
+
+**Interview tip:** Rotations are `O(1)` - just pointer updates. The `O(log n)` cost of insert/delete comes from traversing the height of the tree, not from rotations.
+
+Prof Seth explains it best! For visual demonstrations, see [Prof Seth's lecture 10](https://www.youtube.com/watch?v=dS02_IuZPes&list=PLgpwqdiEMkHA0pU_uspC6N88RwMpt9rC8&index=9) on trees.
+
+## Notes
+1. **Height guarantee**: AVL trees have height at most `~1.44 log(n)`, tighter than Red-Black trees' `2 log(n)`. This makes AVL faster for lookup-heavy workloads.
+
+2. **Rebalancing frequency**: AVL may rotate more often than RB-trees on insert/delete since it enforces stricter balance. This is the trade-off for faster lookups.
+
+3. **Duplicate keys**: The implementation here does not support duplicate keys. To handle duplicates, you could store a count in each node or use a list as the value.
+
+4. **Augmentation**: AVL trees are a great base for augmented structures. Store additional info (e.g., subtree size for order statistics) and update it during rotations.
+
+## Applications
+AVL trees offer excellent lookup times due to strict balancing, but the overhead of maintaining balance
+can make them less preferred when insertions/deletions vastly outnumber lookups.
+
+| Use Case | Best Choice | Why |
+|----------|-------------|-----|
+| Lookup-heavy workloads | AVL | Stricter balance → faster search |
+| Insert/delete-heavy | Red-Black | Fewer rotations on average |
+| Disk-based storage | B-tree | Optimized for block I/O |
+| In-memory databases | AVL or RB | Both work well |
+
+**Interview tip:** "When would you choose AVL over Red-Black?" → When reads dominate writes, AVL's tighter height bound (`1.44 log n` vs `2 log n`) gives faster lookups.
+
+AVL trees are also commonly used as a base for augmented structures:
+- **Order Statistics Tree** - find k-th smallest element in `O(log n)`
+- **Interval Tree** - find all intervals overlapping a point
+- **Orthogonal Range Tree** - 2D range queries
diff --git a/src/main/java/dataStructures/binarySearchTree/BinarySearchTree.java b/src/main/java/dataStructures/binarySearchTree/BinarySearchTree.java
index 5466d0f0..7af11e25 100644
--- a/src/main/java/dataStructures/binarySearchTree/BinarySearchTree.java
+++ b/src/main/java/dataStructures/binarySearchTree/BinarySearchTree.java
@@ -38,13 +38,17 @@ public class BinarySearchTreeHow to identify the case
+ +1. Node has balance factor `> 1` (left-heavy): + - If left child's balance factor `>= 0` → **LL case** + - If left child's balance factor `< 0` → **LR case** + +2. Node has balance factor `< -1` (right-heavy): + - If right child's balance factor `<= 0` → **RR case** + - If right child's balance factor `> 0` → **RL case** + +Why does the 2-children case work?
-#### Delete Implementation Details +The successor (smallest node in right subtree) maintains the BST invariant because: +1. It's larger than everything in the left subtree (since it's larger than the deleted node) +2. It's smaller than everything else in the right subtree (since it's the minimum there) -The delete operation is split into three different cases - when the node to be deleted has no children, one child or -two children. +Using the predecessor (largest in left subtree) works equally well. -**No children:** Simply delete the node. +
-
-This is an upper-bound. Specifically, we have `n` insertions, and since we can have up to `n` elements in the heap, -the insertion operation would at most take `log(n)`. Hence, `O(nlogn)`. +The key insight is the **distribution of nodes by level** in a complete binary tree: +- ~`n/2` nodes are at the bottom level (leaves) +- ~`n/4` nodes are one level up +- ~`n/8` nodes are two levels up +- ... and so on +- 1 node at the root -
+**BubbleUp from front** (like repeated insertions):
+- Level 0: 1 node, travels 0 levels
+- Level 1: 2 nodes, each travels up to 1 level
+- Level 2: 4 nodes, each travels up to 2 levels
+- ...
+- Level `log(n)`: **`n/2` nodes, each travels up to `log(n)` levels**
-Heapify deals with bubbling down (for max heap) all elements starting from the back. Loose Bound..?
+Why bubbleDown gives O(n) but bubbleUp gives O(n log n)
-The above mentioned that creating a heap through insertion of n elements would take O(nlogn).-This is an upper-bound. Specifically, we have `n` insertions, and since we can have up to `n` elements in the heap, -the insertion operation would at most take `log(n)`. Hence, `O(nlogn)`. +The key insight is the **distribution of nodes by level** in a complete binary tree: +- ~`n/2` nodes are at the bottom level (leaves) +- ~`n/4` nodes are one level up +- ~`n/8` nodes are two levels up +- ... and so on +- 1 node at the root -
-What about bubbling-up all elements starting from the front instead?
-**No issue with correctness, problem lies with efficiency of operation.** +The bottom half alone contributes `(n/2) * log(n)` = **O(n log n)** -The number of operations required for bubbleUp and bubbleDown (to maintain heap property), is proportional to the -distance the node have to move. bubbleDown starts from the bottom level whereas bubbleUp starts from the top level. -Only 1 node is at the top whereas (approx) half the nodes is at the bottom level. It therefore makes sense to use -bubbleDown. +**BubbleDown from back**: +- Level `log(n)` (leaves): **`n/2` nodes, travel 0 levels** (already valid) +- Level `log(n)-1`: `n/4` nodes, each travels at most 1 level +- ... +- Level 0 (root): 1 node, travels at most `log(n)` levels -## Complexity Analysis +Total: `Σ (n/2^(k+1)) * k` for k from 0 to log(n) → converges to **O(n)** + +The difference: bubbleDown makes the **many** leaf nodes do **zero** work, while bubbleUp makes them do the **most** work. -**Time**: O(log(n)) in general for most native operations, -except heapify (building a heap from a sequence of elements) that takes O(n) + + +**Interview tip:** "Why is heapify O(n)?" → Most nodes are near the bottom and do little or no work with bubbleDown. The sum converges to O(n), not O(n log n). + +## Complexity Analysis -**Space**: O(n) +**Time:** +| Operation | Complexity | Notes | +|-----------|------------|-------| +| `peek()` | `O(1)` | Access root | +| `offer()` | `O(log n)` | Insert + bubbleUp | +| `poll()` | `O(log n)` | Remove root + bubbleDown | +| `remove(obj)` | `O(log n)` | With Map augmentation (otherwise `O(n)`) | +| `updateKey()` | `O(log n)` | With Map augmentation | +| `heapify()` (bubbleDown) | `O(n)` | Efficient approach | +| `heapify()` (bubbleUp) | `O(n log n)` | Naive approach | -where n is the number of elements (whatever the structure, it must store at least n nodes) +**Space**: `O(n)` where n is the number of elements (whatever the structure, it must store at least `n` nodes) ## Notes -1. Heaps are often presented as max-heaps (eg. in textbooks), hence the implementation follows a max-heap structure - - Still, it is not too difficult to convert a max heap to a min heap, simply negate the key value -2. The heap implemented here is actually augmented with a Map data type. This allows identification of nodes by key. - - Java's PriorityQueue and Python's heap actually support the removal of a node identified by its value / key. - Note that this is not a typical operation introduced alongside the concept heap simply because the time complexity - would now be O(n), no longer log(n). And indeed, both Java's and Python's version have time complexities - of O(n) for this remove operation since their underlying implementation is not augmented. - - The trade-off would be that the heap does not support insertion of duplicate objects else the Map would not work - as intended. -3. Rather than using Java arrays, where size must be declared upon initializing, we use list here in the implementation. -4. [Good read](https://stackoverflow.com/questions/9755721/how-can-building-a-heap-be-on-time-complexity?) on the - time complexity of heapify and making the correct choice between bubbleUp and bubbleDown. +1. **Max vs Min heap**: This implementation is a max-heap. To convert to min-heap, simply negate the key values or reverse the comparator. + +2. **Map augmentation**: The implementation uses a `Map
-
-
- Operating systems: Operating systems use LRU cache for memory management in page replacement algorithms. When a program requires more memory pages than are available in physical memory, the operating system decides which pages to evict to disc based on LRU caching, ensuring that the most recently accessed pages remain in memory. -
- Web browsers: Web browsers use LRU cache to store frequently accessed web pages. This allows users to quickly revisit pages without the need to fetch the entire content from the server. -
- Databases: Databases use LRU cache to store frequent query results. This reduces the need to access the underlying storage system for repeated queries. -
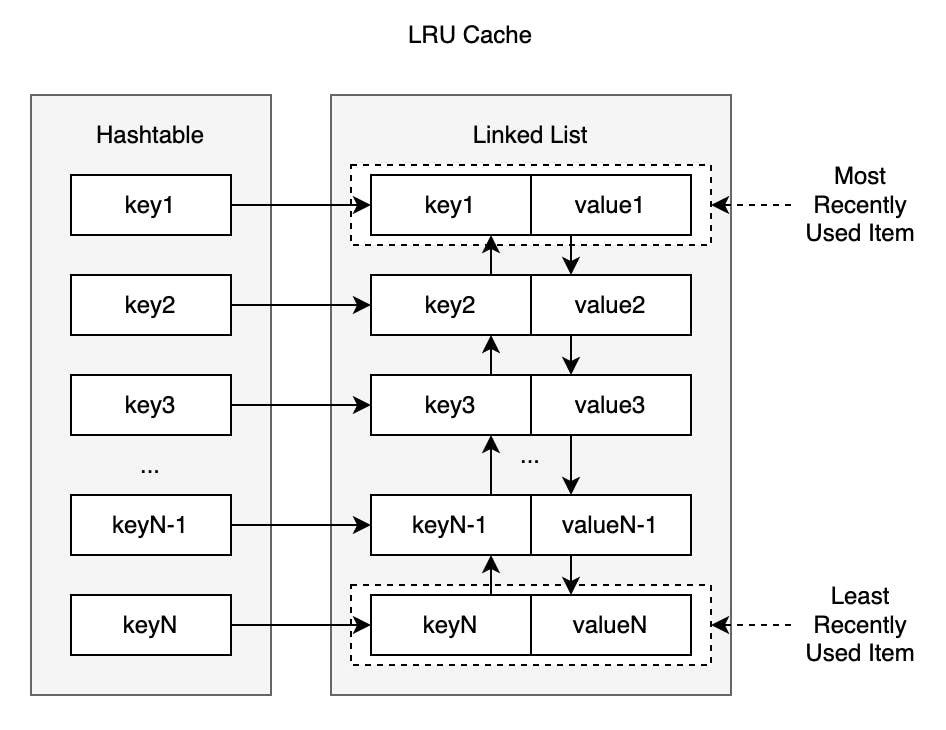 +The HashMap stores `key → node` mappings, allowing direct access to any node. The doubly-linked list allows `O(1)` move-to-front and removal without traversal.
-### Cache Key
+**Implementation detail**: Our implementation uses **sentinel nodes** (dummy head and tail), which eliminates null checks when inserting/removing at boundaries.
-The hash map values are accessed through cache keys, which are unique references to the cached items in a LRU cache. Moreover, storing key-value pairs of hash keys and their corresponding nodes, which encapsulate cached items in a hash map and allows us to avoid O(n) sequential access of cached items.
+## Complexity Analysis
-### Eviction
+| Operation | Time | Notes |
+|-----------|------|-------|
+| `get(key)` | `O(1)` expected | HashMap lookup + move to front |
+| `put(key, value)` | `O(1)` expected | HashMap insert + list manipulation |
-When the cache is full and a new item needs to be added, the eviction process is triggered. The item at the back of the list, which represents the least recently used data, is removed from both the list and the hash map. The new item is then added to the front of the list, and the cache key is stored in the hash map along with its corresponding cache value.
+**Space**: `O(capacity)` - stores at most `capacity` items
-However, if a cached item is accessed through a read-only operation, we still move the cached item to the front of the list without any eviction. Therefore, any form of interaction with a key will move its corresponding node to the front of the doubly-linked list without evection being triggered. Eviction is only applicable to write operations when a cache is considered full.
+**Interview tip:** LRU Cache (LeetCode 146) is a classic design question. The key insight is combining HashMap + doubly-linked list. Know how to implement the move-to-front operation cleanly.
-## Complexity Analysis
+## Notes
-**Time**: **expected** O(1) complexity
+1. **Why doubly-linked?** When removing a node, we need to update its predecessor's `next` pointer. With a singly-linked list, finding the predecessor requires `O(n)` traversal.
-As we rely on basic hash map operations to insert, access, and delete cache nodes, the get and put operations supported by LRU cache are influenced by the time complexity of these hash map operations. Insertion, lookup, and deletion operations in a well-designed hash map take O(1) time on average. Therefore, the hash map provides expected O(1) time on operations, and the doubly-linked list provides insertion and removal of nodes in O(1) time.
+2. **Cache hit ratio**: A good cache achieves 95-99% hit ratio. If hits are rare, caching overhead may not be worthwhile.
-**Space**: O(cache capacity)
+3. **Stale data**: Frequently accessed items may stay cached indefinitely, becoming outdated. Consider TTL (time-to-live) for data that changes.
-## Notes
+4. **Thread safety**: For concurrent access, synchronization is needed (e.g., locks, concurrent data structures). Our implementation is not thread-safe.
+
+## Applications
+
+| Use Case | Example |
+|----------|---------|
+| OS page replacement | Keep recently used memory pages in RAM |
+| Web browsers | Cache recently visited pages |
+| Database query cache | Cache frequent query results |
+| CDN edge caching | Cache popular content at edge servers |
+
+## Other Caching Strategies
+
+| Strategy | Eviction Rule | Best For |
+|----------|---------------|----------|
+| **LRU** | Least recently used | General purpose, temporal locality |
+| **LFU** | Least frequently used | Popularity-based access patterns |
+| **FIFO** | First in, first out | Simple, predictable eviction |
+| **MRU** | Most recently used | Stack-like access (e.g., file scans) |
+| **Random** | Random eviction | Low overhead, unpredictable access |
-
+The HashMap stores `key → node` mappings, allowing direct access to any node. The doubly-linked list allows `O(1)` move-to-front and removal without traversal.
-### Cache Key
+**Implementation detail**: Our implementation uses **sentinel nodes** (dummy head and tail), which eliminates null checks when inserting/removing at boundaries.
-The hash map values are accessed through cache keys, which are unique references to the cached items in a LRU cache. Moreover, storing key-value pairs of hash keys and their corresponding nodes, which encapsulate cached items in a hash map and allows us to avoid O(n) sequential access of cached items.
+## Complexity Analysis
-### Eviction
+| Operation | Time | Notes |
+|-----------|------|-------|
+| `get(key)` | `O(1)` expected | HashMap lookup + move to front |
+| `put(key, value)` | `O(1)` expected | HashMap insert + list manipulation |
-When the cache is full and a new item needs to be added, the eviction process is triggered. The item at the back of the list, which represents the least recently used data, is removed from both the list and the hash map. The new item is then added to the front of the list, and the cache key is stored in the hash map along with its corresponding cache value.
+**Space**: `O(capacity)` - stores at most `capacity` items
-However, if a cached item is accessed through a read-only operation, we still move the cached item to the front of the list without any eviction. Therefore, any form of interaction with a key will move its corresponding node to the front of the doubly-linked list without evection being triggered. Eviction is only applicable to write operations when a cache is considered full.
+**Interview tip:** LRU Cache (LeetCode 146) is a classic design question. The key insight is combining HashMap + doubly-linked list. Know how to implement the move-to-front operation cleanly.
-## Complexity Analysis
+## Notes
-**Time**: **expected** O(1) complexity
+1. **Why doubly-linked?** When removing a node, we need to update its predecessor's `next` pointer. With a singly-linked list, finding the predecessor requires `O(n)` traversal.
-As we rely on basic hash map operations to insert, access, and delete cache nodes, the get and put operations supported by LRU cache are influenced by the time complexity of these hash map operations. Insertion, lookup, and deletion operations in a well-designed hash map take O(1) time on average. Therefore, the hash map provides expected O(1) time on operations, and the doubly-linked list provides insertion and removal of nodes in O(1) time.
+2. **Cache hit ratio**: A good cache achieves 95-99% hit ratio. If hits are rare, caching overhead may not be worthwhile.
-**Space**: O(cache capacity)
+3. **Stale data**: Frequently accessed items may stay cached indefinitely, becoming outdated. Consider TTL (time-to-live) for data that changes.
-## Notes
+4. **Thread safety**: For concurrent access, synchronization is needed (e.g., locks, concurrent data structures). Our implementation is not thread-safe.
+
+## Applications
+
+| Use Case | Example |
+|----------|---------|
+| OS page replacement | Keep recently used memory pages in RAM |
+| Web browsers | Cache recently visited pages |
+| Database query cache | Cache frequent query results |
+| CDN edge caching | Cache popular content at edge servers |
+
+## Other Caching Strategies
+
+| Strategy | Eviction Rule | Best For |
+|----------|---------------|----------|
+| **LRU** | Least recently used | General purpose, temporal locality |
+| **LFU** | Least frequently used | Popularity-based access patterns |
+| **FIFO** | First in, first out | Simple, predictable eviction |
+| **MRU** | Most recently used | Stack-like access (e.g., file scans) |
+| **Random** | Random eviction | Low overhead, unpredictable access |
--
-
- Cache hit/miss ratio: A simple metric for measuring the effectiveness of the cache is the cache hit ratio. It is represented by the percentage of requests that are served from the cache without needing to access the original data store. Generally speaking, for most applications, a hit ratio of 95 - 99% is ideal. -
- Outdated cached data: A cached item that is constantly accessed and remains in cache for too long may become outdated. -
- Thread safety: When working with parallel computation, careful considerations have to be made when multiple threads try to access the cache at the same time. Thread-safe caching mechanisms may involve the proper use of mutex locks. -
- Other caching algorithms: First-In-First-Out (FIFO) cache, Least Frequently Used (LFU) cache, Most Recently Used (MRU) cache, and Random Replacement (RR) cache. The performance of different caching algorithms depends entirely on the application. LRU caching provides a good balance between performance and memory usage, making it suitable for a wide range of applications as most applications obey recency of data access (we often do reuse the same data in many applications). However, in the event that access patterns are random or even anti-recent, random replacement may perform better as it has less overhead when compared to LRU due to lack of bookkeeping. -
+  +
+
+ Source: GeeksForGeeks +
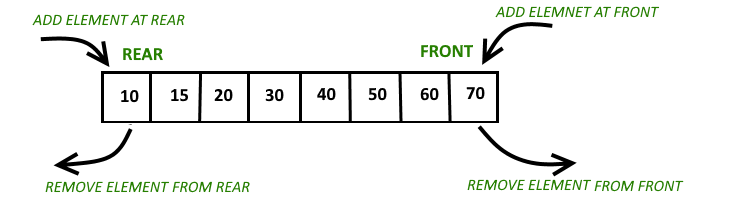
-A deque can be implemented in multiple ways, using doubly linked lists, arrays or two stacks.
+### Core Operations
+| Front | Back |
+|-------|------|
+| `addFirst()` | `addElement()` (addLast) |
+| `pollFirst()` | `pollLast()` |
+| `peekFirst()` | `peekLast()` |
-## Analysis
+## Complexity Analysis
-Much like a queue, deque operations involves the head / tail, resulting in *O(1)* complexity for most operations.
+| Operation | Time | Notes |
+|-----------|------|-------|
+| `addFirst()` / `addElement()` | `O(1)` | Insert at either end |
+| `pollFirst()` / `pollLast()` | `O(1)` | Remove from either end |
+| `peekFirst()` / `peekLast()` | `O(1)` | Access either end |
+
+**Space**: `O(n)` for n elements
## Notes
-Just like a queue, a monotonic deque could also be created to solve more specific sliding window problems.
+1. **Implementation**: Our implementation uses a doubly-linked list. Alternatives include circular arrays (Java's `ArrayDeque`) or two stacks.
+
+2. **Versatility**: A deque can simulate:
+ - **Queue**: `addElement()` + `pollFirst()` (FIFO)
+ - **Stack**: `addFirst()` + `pollFirst()` (LIFO)
+
+3. **Java's ArrayDeque**: Preferred over `LinkedList` for most use cases - faster due to cache locality and no node allocation overhead.
+
+**Interview tip:** When asked to implement a queue using stacks (or vice versa), a deque provides both interfaces naturally. Understanding deque operations helps with these classic interview questions.
+
+## Applications
+
+| Use Case | Why Deque? |
+|----------|-----------|
+| Sliding window maximum/minimum | Remove expired elements from front, maintain order from back |
+| Palindrome checking | Compare characters from both ends simultaneously |
+| Work stealing (parallel computing) | Threads steal from opposite end to reduce contention |
+| Undo/Redo with bounded history | Remove oldest when limit reached, add new at one end |
+| Browser history | Back/forward navigation from current position |
+
+### Sliding Window Pattern
+
+Deques are essential for the **sliding window maximum/minimum** pattern:
+
+```
+Window slides right →
+[1, 3, -1, -3, 5, 3, 6, 7], k=3
+
+Window [1,3,-1] → max = 3
+Window [3,-1,-3] → max = 3
+Window [-1,-3,5] → max = 5
+...
+```
+A [Monotonic Queue](../monotonicQueue) (built on a deque) solves this in `O(n)` instead of `O(n*k)`.
+**Interview tip:** When you see "sliding window" + "maximum/minimum", think deque. The key insight: elements that can never be the answer can be discarded early.
diff --git a/src/main/java/dataStructures/queue/README.md b/src/main/java/dataStructures/queue/README.md
index 9d2477bf..0b55be69 100644
--- a/src/main/java/dataStructures/queue/README.md
+++ b/src/main/java/dataStructures/queue/README.md
@@ -1,42 +1,53 @@
# Queue
## Background
-A queue is a linear data structure that restricts the order in which operations can be performed on its elements.
-### Operation Orders
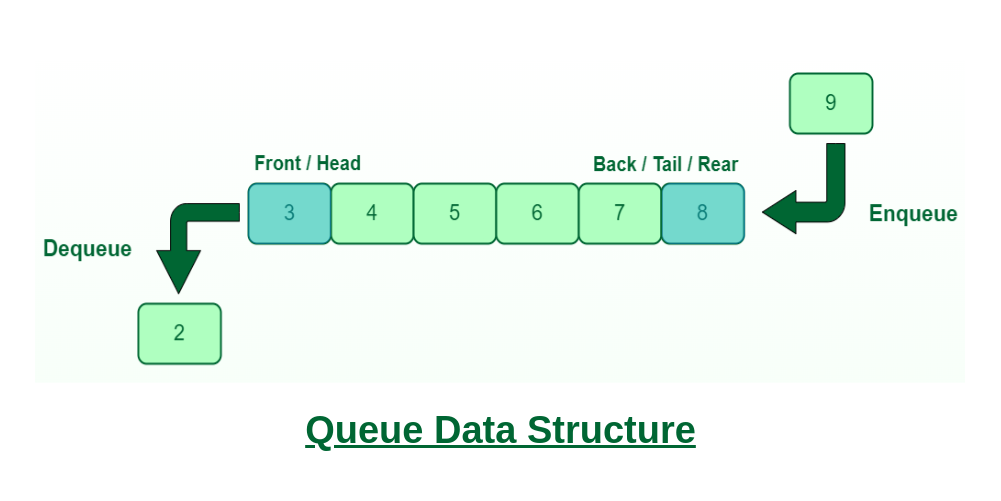
+A queue is a linear data structure that follows **FIFO** (First In, First Out) order - the earliest element added is the first one removed.
-
+
+ + Source: GeeksForGeeks +
+  +
+
+ Source: GeeksForGeeks +
-*Source: GeeksForGeeks*
+### Core Operations
+- **enqueue** (offer/add): Add element to the back
+- **dequeue** (poll/remove): Remove element from the front
+- **peek**: View front element without removing
-Queue follows a FIFO, first in first out order.
-This means the earliest element
-added to the stack is the one operations are conducted on first.
+## Complexity Analysis
-A [stack](../stack/README.md) is a queue with operations conducted in an opposite manner.
+| Operation | Time | Notes |
+|-----------|------|-------|
+| `enqueue()` | `O(1)` | Add to back |
+| `dequeue()` | `O(1)` | Remove from front |
+| `peek()` | `O(1)` | Access front |
+| `isEmpty()` | `O(1)` | Check size |
-## Analysis
-
-As a queue only interacts with either the first or last element regardless during its operations,
-it only needs to keep the pointers of the two element at hand, which is constantly updated as more
-elements are removed / added. This allows queue operations to only incur a *O(1)* time complexity.
+**Space**: `O(n)` for n elements
## Notes
-### Stack vs Queues
+1. **Array vs Linked List**: Our implementation uses a linked list, allowing unbounded growth. Array-based queues are faster (cache-friendly) but need resizing or circular buffer logic.
+
+2. **Java equivalents**: `enqueue()` → `offer()`/`add()`, `dequeue()` → `poll()`/`remove()`
-Stack and queues only differ in terms of operation order, you should aim to use a stack when
-you want the most recent elements to be operated on.
-Some situations where a stack would work well include build redo / undo systems and backtracking problems.
+3. **Queue vs Stack**:
+ - Queue (FIFO): Process in arrival order → BFS, task scheduling, buffering
+ - [Stack](../stack) (LIFO): Process most recent first → DFS, undo/redo, parsing
-On the other hand, a queue allows you to operate on elements that enter first. Some situations where
-this would be useful include Breadth First Search algorithms and task / resource allocation systems.
+## Applications
-### Arrays vs Linked List
+| Use Case | Why Queue? |
+|----------|-----------|
+| BFS traversal | Process nodes level by level |
+| Task scheduling | First-come-first-served processing |
+| Buffering | Handle producer-consumer speed mismatch |
+| Print spooling | Documents printed in submission order |
-It is worth noting that queues can be implemented with either a array or with a [linked list](../linkedList/README.md).
-In the context of ordered operations, the lookup is only restricted to the first element.
+## Variants
-Hence, there is not much advantage in using a array, which only has a better lookup speed (*O(1)* time complexity)
-to implement a queue. Especially when using a linked list to construct your queue
-would allow you to grow or shrink the queue as you wish.
+- [**Deque**](./Deque) - Double-ended queue, add/remove from both ends
+- [**Monotonic Queue**](./monotonicQueue) - Maintains sorted order, useful for sliding window problems
+- **Priority Queue** - Elements ordered by priority, not arrival time (see [Heap](../heap))
+- **Circular Queue** - Fixed-size array with wrap-around, efficient for bounded buffers
diff --git a/src/main/java/dataStructures/queue/monotonicQueue/MonotonicQueue.java b/src/main/java/dataStructures/queue/monotonicQueue/MonotonicQueue.java
index 790c3896..e7fd03bd 100644
--- a/src/main/java/dataStructures/queue/monotonicQueue/MonotonicQueue.java
+++ b/src/main/java/dataStructures/queue/monotonicQueue/MonotonicQueue.java
@@ -1,4 +1,4 @@
-package dataStructures.queue;
+package dataStructures.queue.monotonicQueue;
import java.util.ArrayDeque;
@@ -44,7 +44,6 @@ public boolean isEmpty() {
* @param obj to be inserted.
*/
public void push(T obj) {
- Integer count = 0;
while (!dq.isEmpty() && obj.compareTo(dq.peekLast()) > 0) {
dq.pollLast(); // Removes elements that do not conform the non-increasing sequence.
}
diff --git a/src/main/java/dataStructures/queue/monotonicQueue/README.md b/src/main/java/dataStructures/queue/monotonicQueue/README.md
index c3e114f3..d2d57016 100644
--- a/src/main/java/dataStructures/queue/monotonicQueue/README.md
+++ b/src/main/java/dataStructures/queue/monotonicQueue/README.md
@@ -1,16 +1,141 @@
-# Monotonic Queue
+# Monotonic Queue / Monotonic Stack
-This is a variant of queue where elements within the queue are either strictly increasing or decreasing.
-Monotonic queues are often implemented with a deque.
+## Background
-Within a increasing monotonic queue, any element that is smaller than the current minimum is removed.
-Within a decreasing monotonic queue, any element that is larger than the current maximum is removed.
+A **monotonic queue** (or **monotonic stack**) maintains elements in sorted order (increasing or decreasing) by removing elements that violate the monotonic property when new elements are added.
-It is worth mentioning that the most elements added to the monotonic queue would always be in a
-increasing / decreasing order,
-hence, we only need to compare down the monotonic queue from the back when adding new elements.
+The key insight: **elements that can never be useful are discarded immediately**.
-## Operation Orders
+### Monotonic Queue vs Monotonic Stack
-Just like a queue, a monotonic queue mainly has *O(1)* operations,
-which is unique given that it ensures a certain order, which usually incurs operations of a higher complexity.
+| Structure | Remove from | Use case |
+|-----------|-------------|----------|
+| **Monotonic Stack** | Same end as insert (LIFO) | "Next greater/smaller element" |
+| **Monotonic Queue** | Both ends (deque-based) | "Sliding window max/min" |
+
+Both maintain monotonic order; the difference is whether you need to expire old elements (queue) or just find relationships (stack).
+
+## How It Works
+
+### Decreasing Monotonic Queue (for sliding window maximum)
+
+A monotonic **queue** is needed when elements must **expire** - i.e., sliding window problems. You remove from **both ends**:
+- **Back**: Remove smaller elements (they can't be max while larger element exists)
+- **Front**: Remove expired elements (outside the window)
+
+```
+Array: [5, 3, 4, 1, 2], k=3
+Queue stores indices. Front is always the window maximum.
+
+i=0 (5): push 0 queue=[0]
+i=1 (3): 3 < 5, push 1 queue=[0,1]
+i=2 (4): 4 > 3, pop 1; 4 < 5, push 2 queue=[0,2] → window[0-2], max=arr[0]=5
+i=3 (1): 1 < 4, push 3 queue=[0,2,3]
+ window is [1-3], idx 0 < 1 → EXPIRED, pop front!
+ queue=[2,3] → max=arr[2]=4
+i=4 (2): 2 > 1, pop 3; 2 < 4, push 4 queue=[2,4]
+ window is [2-4], idx 2 >= 2 → valid → max=arr[2]=4
+
+Output: [5, 4, 4] – Length of final result is `n - k + 1`.
+```
+
+**Why queue, not stack?** The front removal for expiration (see i=3). A stack can't efficiently remove from the front.
+
+### Decreasing (non-increasing) Monotonic Stack (for "next greater element")
+
+Stack holds indices of elements **waiting** for their next greater. When a new element is greater than the stack top, we've found the answer for that top.
+
+```
+Array: [2, 1, 2, 4, 3]
+Find: next greater element for each
+
+Process left to right, maintain decreasing stack (of indices):
+
+i=0 (2): stack empty, push 0 stack=[0]
+i=1 (1): 1 < arr[0]=2, push 1 stack=[0,1]
+i=2 (2): 2 > arr[1]=1 → pop 1, ans[1]=2; push 2 stack=[0,2]
+i=3 (4): 4 > arr[2]=2 → pop 2, ans[2]=4
+ 4 > arr[0]=2 → pop 0, ans[0]=4; push 3 stack=[3]
+i=4 (3): 3 < arr[3]=4, push 4 stack=[3,4]
+End: remaining indices have no next greater ans[3]=-1, ans[4]=-1
+
+Result: [4, 2, 4, -1, -1]
+```
+
+**Why decreasing?** Elements in the stack are waiting for something bigger. If a new element is smaller, it also needs to wait → push it. If bigger, it's the answer → pop and record.
+
+## Complexity Analysis
+
+| Operation | Amortized Time | Notes |
+|-----------|----------------|-------|
+| `push()` | `O(1)` | Each element pushed/popped at most once |
+| `pop()` | `O(1)` | Remove from front |
+| `max()` / `min()` | `O(1)` | Front of queue |
+
+**Overall**: Processing n elements takes `O(n)` total, not `O(n²)`.
+
+**Space**: `O(n)` worst case (when input is already sorted in desired order)
+
+## When to Use: Pattern Recognition
+
+### Use Monotonic STACK when:
+
+| Pattern | Example Problem |
+|---------|-----------------|
+| "Next greater element" | Next Greater Element I, II (LC 496, 503) |
+| "Next smaller element" | Daily Temperatures (LC 739) |
+| "Previous greater/smaller" | Process left-to-right instead |
+| Histogram problems | Largest Rectangle in Histogram (LC 84) |
+| Stock span problems | Online Stock Span (LC 901) |
+
+**Trigger phrases**: "next greater", "next smaller", "how many days until", "span of consecutive"
+
+### Use Monotonic QUEUE when:
+
+| Pattern | Example Problem |
+|---------|-----------------|
+| "Sliding window maximum" | Sliding Window Maximum (LC 239) |
+| "Sliding window minimum" | Shortest Subarray with Sum ≥ K (LC 862) |
+| Fixed-size window + max/min | Maximum of all subarrays of size k |
+| Constrained optimization | Jump Game VI (LC 1696) |
+
+**Trigger phrases**: "sliding window", "subarray of size k", "maximum/minimum in window"
+
+## Classic Problems
+
+### 1. Sliding Window Maximum (LC 239)
+```
+Input: nums = [1,3,-1,-3,5,3,6,7], k = 3
+Output: [3,3,5,5,6,7]
+
+Use decreasing monotonic queue:
+- Push new element (remove smaller elements from back)
+- Pop expired elements from front (index out of window)
+- Front is always the window maximum
+```
+
+### 2. Largest Rectangle in Histogram (LC 84)
+```
+For each bar, find: how far left/right can it extend?
+= find previous smaller & next smaller elements
+
+Use increasing monotonic stack for both passes.
+```
+
+## Notes
+
+1. **Increasing vs Decreasing**:
+ - Decreasing queue/stack → finding **maximums** or **next greater**
+ - Increasing queue/stack → finding **minimums** or **next smaller**
+
+2. **Both directions work**: Left-to-right treats the stack as elements "waiting" for their answer. Right-to-left treats the stack as "candidates" to the right. Choose whichever mental model clicks for you.
+
+3. **Queue vs Stack choice**:
+ - Need to expire old elements? → Queue (sliding window)
+ - Just need relationships? → Stack (next/previous element)
+
+**Interview tip:** When you see `O(n²)` brute force for finding max/min or next greater/smaller, monotonic structures often give `O(n)`. The insight is that dominated elements can be discarded—if a newer element is better, older worse elements will never be chosen.
+
+## Implementation Note
+
+Our implementation is a **decreasing monotonic queue** (maintains maximum at front). For a monotonic stack, simply use a regular stack and apply the same comparison logic—no special data structure needed.
diff --git a/src/main/java/dataStructures/trie/README.md b/src/main/java/dataStructures/trie/README.md
index 76193ddf..f67877bb 100644
--- a/src/main/java/dataStructures/trie/README.md
+++ b/src/main/java/dataStructures/trie/README.md
@@ -54,19 +54,27 @@ traversing an edge labeled 'b' from one node to another means you're adding the
## Complexity Analysis
-Let the length of the longest word be `L` and the number of words be `N`.
+Let `L` be the length of the word (or longest word), and `N` be the number of words.
-**Time**: O(`L`)
-An upper-bound. For typical trie operations like insert, delete, and search,
-since it is likely that every char is iterated over.
+| Operation | Time | Notes |
+|-----------|------|-------|
+| `insert()` | `O(L)` | Traverse/create nodes for each character |
+| `search()` | `O(L)` | Traverse nodes for each character |
+| `delete()` | `O(L)` | Traverse and unmark end flag |
+| `deleteAndPrune()` | `O(L)` | Traverse twice (down then up for pruning) |
+| `wordsWithPrefix()` | `O(L + M)` | `L` to reach prefix, `M` = total chars in matching words |
-**Space**: O(`N*L`)
-In the worst case, we can have minimal overlap between words and every character of every word needs to be captured
-with a node.
+**Space**: `O(N * L)` in the worst case, when words have minimal overlap and every character needs its own node.
-A trie can be space-intensive. For a very large corpus of words, with the naive assumption of characters being
-likely to occur in any position, another naive estimation on the size of the tree is O(_26^l_) where _l_ here is
-the average length of a word. Note, 26 is used since are only 26 alphabets.
+
+ + Source: GeeksForGeeks +