Natural Language Processing
Language Model은 k개의 단어 배열이 나왔을 때 실제로 그런 배열이 나올 확률을 의미한다. 즉, 단어 시퀀스에 대한 확률 분포이다. 예를 들어, P(I am a boy) = 0.001, P(I a boy am) = 0.000000000001 과 같이 나타낼 수 있다. Language Model은 모델을 만들 때 사용한 문서들에 따라 크게 달라진다. IT 블로그의 글을 중심으로 학습을 했다면 IT 용어들이 많이 쓰인 시퀀스의 확률이 높게 나올 것이다.
Language Model에는 unigram model과 n-gram model이 있다. unigram model은 단어 시퀀스의 확률을 계산할 때 단순히 각각의 단어가 나올 확률을 곱해서 계산한다. n-gram model은 단어 시퀀스 확률을 계산할 때, 앞에 n-1개의 단어 시퀀스가 나올 때 그 다음에 나온 단어가 나올 확률의 곱으로 계산한다. 자세한 내용은 아래 블로그에 설명이 되어 있다.
모델을 만들 때 사용한 문서에 따라 확률값이 크게 달라지는 점을 이용하여, 문서 분류에도 사용할 수 있다. IT 문서로 만든 language model, 연예 문서로 만든 language model 등 문서 주제별로 각각 language model을 만든다. 주제별 language model로 각각 단어 시퀀스가 나올 확률을 계산하면, 가장 큰 값을 반환한 language model의 주제가 글의 주제라고 볼 수 있을 것이다.
현실적으로 unigram model이나 2-gram model을 사용하는 것이 한계이다. 데이터의 크기가 지수적으로 증가하기 때문이다. 그래서 n 값이 너무 크면 모델을 저장하는 것도 문제이고, 경우의 수가 너무 많아서 model이 학습하지 못한 단어의 쌍도 많이 나오게 된다. 데이터의 양이 아주 많지 않다면 2-gram model도 잘 동작하지 않아서 unigram model을 사용해야 한다.
TF-IDF(Term Frequency-Inverse Document Frequency)는 문서 내에서 가장 비중있게 다루는 단어가 무엇인지 나타내는 지표이다. 특정 단어가 문서에서 나오는 빈도가 높으면서, 나오는 문서 수가 적을수록 값이 크다. 여러 문서에서 골고루 나오는 단어(있습니다, 입니다 등)는 별 의미가 없다고 간주하고, 한 문서에서만 자주 나오는 단어(키워드, 전문 용어, 고유 명사 등)는 많은 의미가 있다고 간주한다.
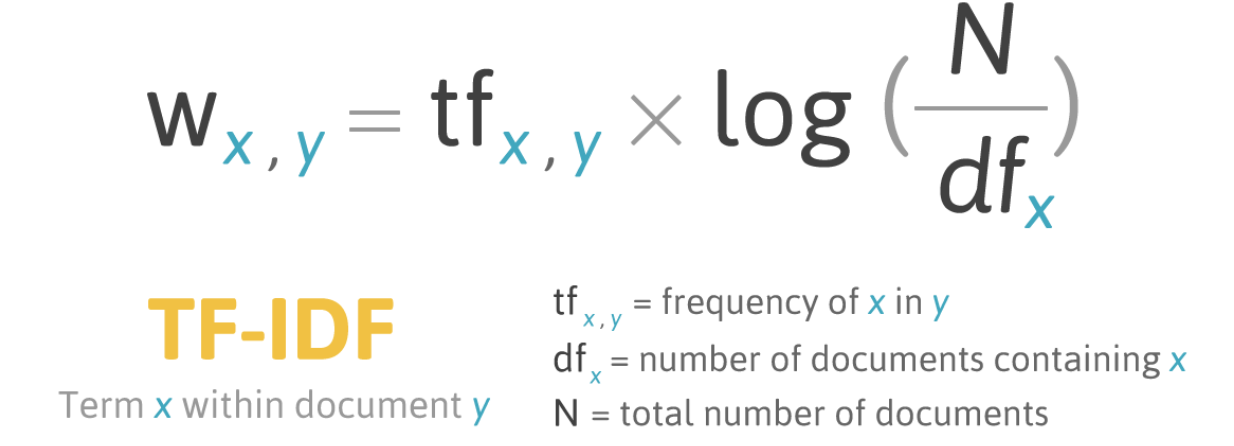
TF-IDF는 TF(Term Frequency)와 IDF(Inverse Frequency)의 곱으로 나타낸다. TF는 단어가 많이 나올수록 값이 커지고 IDF는 단어가 나온 문서가 적을수록 값이 커진다. 두 문서 간의 유사도를 계산할 때 TF-IDF 값이 큰 단어를 중심으로 비교할 수도 있다. 자세한 내용은 아래 참고 링크에서 확인할 수 있다.
- 언론사가 알아야 할 알고리즘③ TF-IDF
- TFIDF – Term Frequency Inverse Document Frequency: tf-idf 개념을 설명하는 한글 문서.
- TF-IDF에 대한 이해 - TFIDF 유사도 구하기
Bayes Theorem은 아래와 같이 사전 확률과 사후 확률을 서로 바꿨을 때 확률을 계산하는 공식이다.
P(A|B) = P(B|A)P(A)/P(B)
이 공식은 스팸 필터를 만들 때 많이 사용된다. 우리가 관찰할 수 있는 값인 "스팸 문서에서 어느 단어가 나올 확률"을 통해 "어느 단어가 나왔을 때 스팸 문서일 확률"을 유도할 수 있기 때문이다.
텍스트는 Sequence가 있는 데이터라서 분석할 때 RNN이나 CNN이 많이 쓰인다.
논문 링크: http://www.aclweb.org/anthology/D14-1181
이미지의 한 픽셀과 그 주변에 있는 픽셀을 보고 feature를 뽑아 내는 것에 착안하여, 벡터로 된 연속된 n개의 단어를 보아 feature를 뽑아 내는 방식. 문장 분류 등에 사용 가능하다. 기존 텍스트 분석은 RNN만을 사용했으나 RNN 대신 CNN도 텍스트 처리에 사용할 수 있음을 보여 주는 논문이다. 벡터는 Word2Vec을 이용할 수도 있지만 one-hot encoding을 활용할 수도 있다. 그러나 잘 만들어진 Word2Vec을 이용하는 편이 더 좋다.
한국어 자연어 처리를 할 때 CNN에서 Word2Vec만 쓰면 성능이 좋지 않고, Doc2Vec도 같이 써야 성능이 좋아진다는 연구 결과가 존재한다. (논문 링크)
논문 링크: https://arxiv.org/abs/1603.06042
자연어를 컴퓨터가 이해할 수 있게 하는 것을 목표로, 문장을 파싱하여 단어 간의 관계를 트리 형태로 내놓는 모델이다. 2016년에 Google이 만들었다.
문장을 특정한 카테고리로 분류할 수 있다. 예를 들면 스팸 문서 분류라던가, 리뷰의 긍부정 분류, 글의 주제 분류 등을 할 수 있다. 문장을 분류할 수 있으면 같은 원리로 문단이나 글도 분류할 수 있다.
-
네이버 영화 리뷰 감정 분석: gensim 라이브러리를 이용해서 Doc2Vec + CNN으로 영화 리뷰가 긍정적인지 부정적인지 판단하는 예제
-
hoho0443/classify_comment_emotion: Naive Bayes Classifier나 Doc2Vec을 이용하여 리뷰를 긍정, 부정으로 분류하는 예제 (한국어)
-
한국어와 NLTK, Gensim의 만남 - PyCon KR 2015: nltk, gensim 라이브러리로 단어를 vector화하고 문장을 분류/군집화 하는 예제
-
추천시스템이 word2vec을 만났을때 - PyCon KR 2015: word2vec 등으로 영화 추천 시스템을 만드는 예제
seq2seq를 활용해 기계 학습 시스템을 tensorflow를 이용해 만들 수 있다. 자세한 방법은 아래 링크에 나와 있다.
- tensorflow/nmt:TensorFlow Neural Machine Translation Tutorial
이 것을 이용해서 챗봇(Chatbot)도 만들 수 있다. 기계 번역에서 원본 언어를 "입력 문장"으로, 번역된 언어를 "대답 문장"으로 대응하여 학습을 시키면 간단한 챗봇이 완성된다.
*[Deep Learning] seq2seq 를 이용한 챗봇 (Neural Machine Chatbot): tensorflow/nmt를 기반으로 챗봇을 만든 예제
형태소 분석이 필수이다. 영어와 달리 한국어는 단어의 활용이 다양해서 같은 단어라도 여러 형태로 표현할 수 있다. (예: 바꾸다, 바꾸니, 바꿔, 바꿉니다, ...) 또한, 별도의 단어인 조사는 앞 단어와 붙여 쓰기 때문에 띄워쓰기만으로 단어를 구분하는 것도 불가능하다. 그나마 형태소 분석기를 통해 형태소 단위로 분석하거나, 아니면 조사를 떼어 낸 단어 단위로 분석하는 것이 바람직하다. 같은 단어라면 같은 단어로 인식하고 학습을 해야 텍스트 분석 성능이 잘 나온다.
형태소 분석기 중 가장 유명한 것은 KoNLPy (Python)이나 꼬꼬마 한글 형태소 분석기 (Java)가 있다. 형태소 분석은 사전에 미리 정의된 규칙에 따라 단어를 나누고 품사를 태깅하는 방식으로 동작한다. 그래서 사전에 없는 단어는 정상적으로 형태소 분석을 하지 못할 수도 있다.
다만 데이터가 매우 많으면 형태소 분석 없이 조사 제거만 해도 잘 동작할 것이다.
한국어 말뭉치란 한국어로 된 말이나 글을 모아, 문장, 어절, 형태소 별로 분석한 데이터를 의미한다. 자연어 처리의 기본이 되는 데이터이다. 당장 Word2Vec을 만들려고 해도 상당한 양의 텍스트가 필요할텐데, 이럴 때 말뭉치를 사용할 수 있다.
주요 말뭉치로는 아래와 같은 것이 있다.
- 국립국어원 말뭉치: 국립국어원에서 제공하는 한국어 말뭉치. 다운로드(내려받기)를 하려면 로그인(들어가기)이 필요하다.
- 인공지능 씨앗 한글 말뭉치, 2007년 멈춰선 까닭: 말뭉치 개념 소개