- Maximum Depth of Binary Tree
- Symmetric Tree
- Same Tree
- Path Sum
- Subtree of Another Tree
- Binary Tree Inorder Traversal
- Validate Binary Search Tree
- Binary Tree Level Order Traversal
- Invert Binary Tree
- Kth Smallest Element in a BST
- Lowest Common Ancestor of a Binary Search Tree
- Lowest Common Ancestor of a Binary Tree
- Binary Search Tree Iterator
- Construct Binary Tree from Preorder and Inorder Traversal
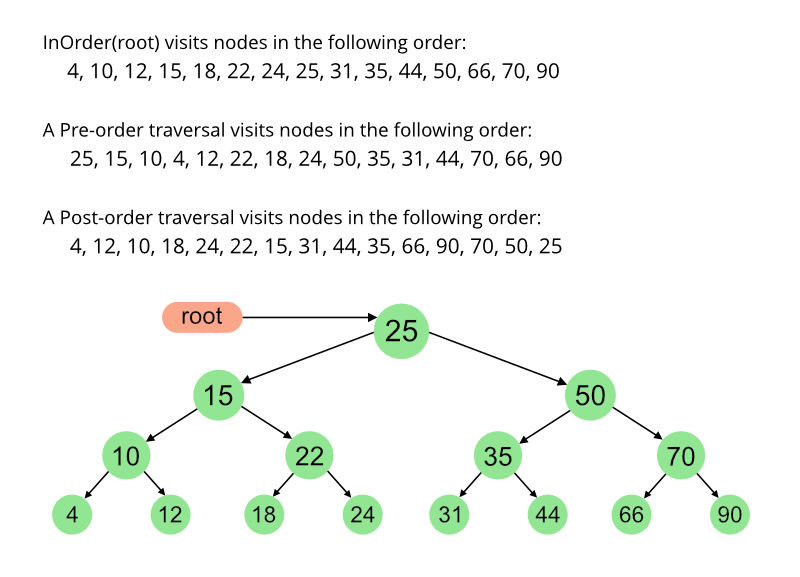
Algorithm Inorder(tree)
- Traverse the left subtree, i.e., call Inorder(left-subtree)
- Visit the root.
- Traverse the right subtree, i.e., call Inorder(right-subtree)
Algorithm Preorder(tree)
- Visit the root.
- Traverse the left subtree, i.e., call Preorder(left-subtree)
- Traverse the right subtree, i.e., call Preorder(right-subtree)
Algorithm Postorder(tree)
- Traverse the left subtree, i.e., call Postorder(left-subtree)
- Traverse the right subtree, i.e., call Postorder(right-subtree)
- Visit the root.
https://leetcode.com/problems/maximum-depth-of-binary-tree/
public int maxDepth(TreeNode root) {
if (root == null)
return 0;
return 1 + Math.max(maxDepth(root.left), maxDepth(root.right));
}https://leetcode.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/
For example, given
preorder = [3,9,20,15,7]
inorder = [9,3,15,20,7]
Return the following binary tree:
3
/ \
9 20
/ \
15 7
Идея: взять корень дерева (preorder[0]) и запустить для него рекурсивную процедуру построения дерева.
Суть её в том, что по индексу текущего корня дерева можно разбить массив inorder на левое и правое поддерево.
Далее рекурсивно вызываем эту процедуру для двух поддеревьев.
Все локальные корни дерева берутся из preorder, по inorder дерево разветвляется на левое и правое.
currRoot + 1 - индекс левого ребенка в массиве preorder.
То есть в preorder всегда левый ребенок находится справа от родителя на 1 позицию (при условии наличия левого ребенка, а он есть тогда,
когда левый интервал непустой, т.е. есть левое поддерево)
currRoot + inIndex - inStart + 1 - индекс правого ребенка в массиве preorder. Такая формула объясняется тем, что все индексы currRoot < i <= currRoot + inIndex - inStart
принадлежат левому поддереву, а нам нужен первый элемент правого, так что добавим еще 1.
public int searchElemIdxInArray(int[] array, int elem) {
int N = array.length;
for (int i = 0; i < N; i++) {
if (array[i] == elem)
return i;
}
return -1;
}
public TreeNode buildTree(int[] preorder, int[] inorder) {
return helper(0, 0, inorder.length - 1, preorder, inorder);
}
public TreeNode helper(int currRoot, int inStart, int inEnd, int[] preorder, int[] inorder) {
if (currRoot > preorder.length - 1 || inStart > inEnd)
return null;
TreeNode root = new TreeNode(preorder[currRoot]);
int inIndex = searchElemIdxInArray(inorder, root.val);
root.left = helper(currRoot + 1, inStart, inIndex - 1, preorder, inorder);
root.right = helper(currRoot + inIndex - inStart + 1, inIndex + 1, inEnd, preorder, inorder);
return root;
}https://leetcode.com/problems/symmetric-tree
class Solution {
public boolean compare(TreeNode a, TreeNode b) {
if (a == null && b == null) return true;
if (a == null || b == null) return false;
return (a.val == b.val)
&& compare(a.left, b.right)
&& compare(a.right, b.left);
}
public boolean isSymmetric(TreeNode root) {
if (root == null)
return true;
return compare(root.left, root.right);
}
}В очередь добавляем элементы дерева, которые будем обходить. В цикле извлекаем 2 элемента очереди - это симметричные узлы дерева. Чтобы очередь имела такую структуру, кладем на каждой итерации новые 4 элемента: a.left, b.right, a.right, b.left
class Solution {
public boolean isSymmetric(TreeNode root) {
if (root == null)
return true;
Queue<TreeNode> q = new LinkedList<>();
q.add(root);
q.add(root);
while (!q.isEmpty()) {
TreeNode a = q.poll();
TreeNode b = q.poll();
if (a == null && b == null)
continue;
if (a == null || b == null)
return false;
if (a.val != b.val)
return false;
q.add(a.left);
q.add(b.right);
q.add(a.right);
q.add(b.left);
}
return true;
}
}https://leetcode.com/problems/same-tree/
Проверить, равны ли 2 дерева.
Используем 2 очереди - для каждого дерева. Достаем из каждой очереди по одному элементу и сверяем их. Кладём в каждую очередь еще по 2 узла дерева (левый и правый ребенок узла дерева, который достали). Когда одна из очередей стала пуста, в одном из деревьев больше нет элементов, нет смысла сравнивать дальше. Если пусты обе очереди, то значит, что деревья равны. Если нет, то одно дерево было поддеревом другого и деревья не равны.
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
Queue<TreeNode> q1 = new LinkedList<>();
Queue<TreeNode> q2 = new LinkedList<>();
q1.add(p);
q2.add(q);
while (!q1.isEmpty() && !q2.isEmpty()) {
TreeNode a = q1.poll();
TreeNode b = q2.poll();
if (a == null && b == null)
continue;
if (a == null || b == null)
return false;
if (a.val != b.val)
return false;
q1.add(a.left);
q1.add(a.right);
q2.add(b.left);
q2.add(b.right);
}
if (!q1.isEmpty() || !q2.isEmpty())
return false;
return true;
}
}https://leetcode.com/problems/path-sum
Проверить, есть ли в дереве root пусть от корня до листа, такой, что сумма всех элементов пути равна sum.
Обходим в дерево с помощью очереди. Каждый элемент очереди содержит пару <TreeNode, Integer>, где ключом является элемент дерева, а
значением - сумма пути до этого элемента. Вытаскиваем элемент из очереди. Если он листовой (то есть оба ребенка null) и его сумма равна искомой, то тогда путь найден, вернём true. Если обошли всё дерево, а пути не нашли, то возвращаем false.
import javafx.util.Pair;
class Solution {
public boolean hasPathSum(TreeNode root, int sum) {
if (root == null)
return false;
Queue<Pair<TreeNode, Integer>> q = new LinkedList<>();
q.add(new Pair<>(root, root.val));
while (!q.isEmpty()) {
Pair<TreeNode, Integer> p = q.poll();
TreeNode node = p.getKey();
Integer s = p.getValue();
if (node.left == null && node.right == null && s == sum)
return true;
if (node.left != null)
q.add(new Pair<TreeNode, Integer>(node.left, s + node.left.val));
if (node.right != null)
q.add(new Pair<TreeNode, Integer>(node.right, s + node.right.val));
}
return false;
}
}class Solution {
public boolean hasPathSum(TreeNode root, int sum) {
if (root == null)
return false;
return (sum - root.val == 0 && root.left == null && root.right == null)
|| hasPathSum(root.left, sum - root.val)
|| hasPathSum(root.right, sum - root.val);
}
}https://leetcode.com/problems/subtree-of-another-tree
Узнать, является ли дерево t поддеревом дерева s.
Оба дерева можно пройти с помощью preorder traversal, записать результат прохода в строку. Очевидно, что если строка второго дерева является подстрокой первого дерева, то и второе дерево есть поддерево первого. Вхождение можно проверить с помощью функции indexOf.

class Solution {
HashSet <String> trees = new HashSet<>();
public String preorder(TreeNode t, boolean left) {
if (t == null) {
if (left)
return "null";
else
return "null";
}
return "#" + t.val + " " + preorder(t.left, true) + " " + preorder(t.right, false);
}
public boolean isSubtree(TreeNode s, TreeNode t) {
String tree1 = preorder(s, true);
String tree2 = preorder(t, true);
return tree1.indexOf(tree2) >= 0;
}
}Рекурсивно для каждого узла проверяем, совпадает ли его поддерево с искомым. Заметим, что рекурсия развернется в выражение вида equals(s,t) || equals(s.left,t) || ... || equals(s.right,t). Так что если хотя бы одно совпадение найдено, то вернется true.
public class Solution {
public boolean equals(TreeNode x, TreeNode y) {
if (x == null && y == null) return true;
if (x == null || y == null) return false;
return x.val == y.val && equals(x.left, y.left) && equals(x.right, y.right);
}
public boolean traverse(TreeNode s, TreeNode t) {
return s != null && (equals(s,t) || traverse(s.left, t) || traverse(s.right, t));
}
public boolean isSubtree(TreeNode s, TreeNode t) {
return traverse(s,t);
}
}https://leetcode.com/problems/binary-tree-inorder-traversal
Рекурсивная процедура идёт сначала рекурсивно влево, потом добавляет в список узел, потом идёт рекурсивно вправо. Это и есть inorder обход.
class Solution {
public void helper(TreeNode root, List<Integer> list) {
if (root.left != null) {
helper(root.left, list);
}
list.add(root.val);
if (root.right != null) {
helper(root.right, list);
}
}
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if (root == null)
return list;
helper(root, list);
return list;
}
}Для обхода дерева используется стек и узел дерева curr. Рассматриваем текущий узел (curr). Для этого узла добавим в стек все узлы по левому пути от него. Каждый из этих узлов нужно будет посетить в порядке снизу вверх, при этом не забыв посетить правые поддеревья этих узлов.
Добавленный узел снимается со стека, его значение добавляется в список обхода, затем текущим узлом становится узел, правый от него. Для этого правого узла на следующей итерации цикла добавим в стек снова все узлы по левому пути. Так делаем до тех пор, пока не выполнится условие выхода.
Усховие выхода: стек пуст и текущий узел равен null (то есть стек больше нечем пополнить). Стек может пусть пустым по мере обхода, однако если узел curr не null, то стек можно снова пополнить.
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if (root == null)
return list;
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (curr != null || !stack.isEmpty()) {
while (curr != null) {
stack.push(curr);
curr = curr.left;
}
curr = stack.pop();
list.add(curr.val);
curr = curr.right;
}
return list;
}
}https://leetcode.com/problems/validate-binary-search-tree
Используем вспомогательную функцию, в которую передаем текущий узел дерева, а также допустимые границы значения этого узла. Для корня границы (null, null), поскольку он может быть любым. Далее идем налево/направо и меняем соответственно правую/левую допустимую границу. Если значение узла вне допустимой границы, то вернем false. Если все узлы проверены и false не вернули, то вернем true.
class Solution {
public boolean helper(TreeNode node, Integer lower, Integer upper) {
if (node == null) return true;
if (lower != null && node.val <= lower) return false;
if (upper != null && node.val >= upper) return false;
if (!helper(node.right, node.val, upper)) return false;
if (!helper(node.left, lower, node.val)) return false;
return true;
}
public boolean isValidBST(TreeNode root) {
return helper(root, null, null);
}
}Используем inorder обход. Заметим, что для валидного дерева все элементы в обходе будут расположены в порядке возрастания. Остаётся только проверить условие (prev >= curr.val), где prev - последний элемент обхода, а curr.val - новый элемент. Если оно выполняется, то дерево невалидное.
class Solution {
public boolean isValidBST(TreeNode root) {
List<Integer> list = new ArrayList<>();
if (root == null)
return true;
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (curr != null || !stack.isEmpty()) {
while (curr != null) {
stack.push(curr);
curr = curr.left;
}
curr = stack.pop();
if (list.size() != 0) {
int prev = list.get(list.size() - 1);
if (prev >= curr.val)
return false;
}
list.add(curr.val);
curr = curr.right;
}
return true;
}
}https://leetcode.com/problems/binary-tree-level-order-traversal/
Обход дерева с помощью очереди. Как доставать из очереди элементы конкретного уровня?
Добавим в очередь корень. Размер первого уровня - 1 элемент (сам корень). Теперь 1 раз берем элемент из очереди, добавляем в очередь детей. Таким образом, в очереди уже лежат все элементы второго уровня. Значит размер очереди - это размер второго уровня (пусть это 2). Теперь 2 раза извлекаем элементы из очереди, а их детей добавляем в эту очередь. В очереди лежат все элементы 3 уровня... И так далее, пока очередь не окажется пуста.
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null) {
return result;
}
Queue <TreeNode> q = new LinkedList<>();
q.add(root);
while (!q.isEmpty()) {
int levelSize = q.size();
List<Integer> currLevel = new ArrayList<>();
for (int i = 0; i < levelSize; i++) {
TreeNode curr = q.remove();
currLevel.add(curr.val);
if (curr.left != null) {
q.add(curr.left);
}
if (curr.right != null) {
q.add(curr.right);
}
}
result.add(currLevel);
}
return result;
}
}https://leetcode.com/problems/invert-binary-tree/
Обычный обход дерева с помощью очереди: сначала добавляем в очередь корень, а затем в цикле извлекаем узлы из очереди, а детей узлов добавляем. Здесь нужно лишь поменять детей местами, прежде чем добавить их в очередь.
class Solution {
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
Queue <TreeNode> q = new LinkedList<>();
q.add(root);
while (!q.isEmpty()) {
TreeNode curr = q.remove();
TreeNode t = curr.left;
curr.left = curr.right;
curr.right = t;
if (curr.left != null) {
q.add(curr.left);
}
if (curr.right != null) {
q.add(curr.right);
}
}
return root;
}
}class Solution {
public TreeNode invert(TreeNode node) {
TreeNode t = node.left;
node.left = node.right;
node.right = t;
if (node.left != null) {
invert(node.left);
}
if (node.right != null) {
invert(node.right);
}
return node;
}
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
return invert(root);
}
}https://leetcode.com/problems/kth-smallest-element-in-a-bst/
В основе решения inorder обход: элементы дерева обрабатываются в порядке возрастания, так что нужно вернуть k-ый элемент списка, полученный при обходе.
class Solution {
public void inOrder(TreeNode root, List<Integer> list) {
if (root == null)
return;
inOrder(root.left, list);
list.add(root.val);
inOrder(root.right, list);
}
public int kthSmallest(TreeNode root, int k) {
List<Integer> sorted = new ArrayList<Integer>();
inOrder(root, sorted);
return sorted.get(k - 1);
}
}Идея та же, что и в рекурсивном подходе: inorder обход. Реализован он с помощью стека. Кладем на стек все элементы по левой ветке, затем снимаем со стека один элемент (и обрабатываем его так, как нам нужно!) и идём направо. Так и работает inorder обход в случае рекурсии. Обработка: уменьшить счетчик уже обработанных элементов на 1. Когда он станет равным 0, текущий обрабатываемый элемент и будет k-ым по счёту.
class Solution {
public int kthSmallest(TreeNode root, int k) {
Deque<TreeNode> stack = new ArrayDeque<>();
while (true) {
while (root != null) {
stack.push(root);
root = root.left;
}
root = stack.pop();
if (--k == 0) return root.val;
root = root.right;
}
}
}https://leetcode.com/problems/lowest-common-ancestor-of-a-binary-tree/
Даны 2 узла дерева: p и q. Нужно найти у них ближайшего общего предка.
Обойдём дерево рекурсивно. Идея проста: найти в поддереве один из узлов p, q. Если один из узлов встретился и в левом поддереве, и вправом, то это значит, что текущий элемент является искомым. Почему этот предок ближайший? Потому что у предков этого предка оба узла p, q будут находиться либо в левом, либо в правом поддереве, но никак не в двух сразу.
Бывает так, что ближайшим предком может быть p или q. Поэтому проверим также, является ли текущий элемент узлом p или q. Критерий того, что найден ближайший предок: выполнены хотя бы 2 условия из 3:
- Узел является
pилиq - В левом поддереве есть
pилиq - В правом поддереве есть
pилиq
class Solution {
private TreeNode result;
public Solution() {
result = null;
}
private boolean recurseTree(TreeNode currentNode, TreeNode p, TreeNode q) {
if (currentNode == null) {
return false;
}
int left = recurseTree(currentNode.left, p, q) ? 1 : 0;
int right = recurseTree(currentNode.right, p, q) ? 1 : 0;
// If the current node is one of p or q
int mid = (currentNode == p || currentNode == q) ? 1 : 0;
// If any two of the flags left, right or mid become True
if (mid + left + right >= 2) {
result = currentNode;
}
// Return true if any one of the three bool values is True.
return (mid + left + right > 0);
}
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
recurseTree(root, p, q);
return result;
}
}Можно сделать так: найти в дереве узлы p и q, при этом сохранив путь из корня до них. Потом двигаться по этим 2 путям в обратную сторону. Первый общий элемент при сравнении путей - ближайший общий предок.
В map добавляем пары "узел-предок", до тех пор, пока оба узла p, q не окажутся ключами map. Далее от узла p пройдем до корня, собирая информацию о предках в Set ancestors. От узла q пройдем наверх до тех пор, пока не получим элемент множества ancestors. Это и будет ближайший общий предок.
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
Deque<TreeNode> stack = new ArrayDeque<>();
Map<TreeNode, TreeNode> map = new HashMap<>();
map.put(root, null);
stack.push(root);
while (!map.containsKey(p) || !map.containsKey(q)) {
TreeNode node = stack.pop();
if (node.left != null) {
map.put(node.left, node);
stack.push(node.left);
}
if (node.right != null) {
map.put(node.right, node);
stack.push(node.right);
}
}
Set<TreeNode> ancestors = new HashSet<>();
while (p != null) {
ancestors.add(p);
p = map.get(p);
}
while (!ancestors.contains(q))
q = map.get(q);
return q;
}
}https://leetcode.com/problems/lowest-common-ancestor-of-a-binary-search-tree/
Так как у нас дерево поиска, этим нужно пользоваться. Ближайший общий предок - такой узел, значение которого находится между значениями узлов p и q. При этом это первый попавшийся такой узел при пути от корня, то есть сверху вниз.
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (p.val > root.val && q.val > root.val) {
return lowestCommonAncestor(root.right, p, q);
}
else if (p.val < root.val && q.val < root.val) {
return lowestCommonAncestor(root.left, p, q);
}
else {
return root; // We have found the split point, i.e. the LCA node.
}
}
}Предыдущее решение в итеративной форме.
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
TreeNode node = root;
while (node != null) {
if (p.val > node.val && q.val > node.val) {
node = node.right;
}
else if (p.val < node.val && q.val < node.val) {
node = node.left;
}
else {
return node;
}
}
return null;
}
}https://leetcode.com/problems/binary-search-tree-iterator/
- Применить inorder обход и вернуть список
- Итерироваться по списку
Будем использовать стек, как и подобает итеративному inorder обходу.
Будем также использовать функцию descentLeft(TreeNode root), которая осуществляет левосторонний спуск по дереву. При создании итератора спустимся от корня дерева к самому левому элементу дерева, чтобы итератор начинал работу с минимального элемента.
hasNext(): Итератор может двигаться дальше при непустом стеке.
next(): Если верхушка стека не имеет правого ребенка, то вернем её значение сразу. Если имеет, то перед этим перейдем направо, спустимся по левостороннему пути, добавляя в стек новые элементы.
class BSTIterator {
Stack<TreeNode> stack;
public BSTIterator(TreeNode root) {
this.stack = new Stack<TreeNode>();
this.descentLeft(root);
}
private void descentLeft(TreeNode root) {
while (root != null) {
this.stack.push(root);
root = root.left;
}
}
public int next() {
TreeNode nextMin = this.stack.pop();
if (nextMin.right != null) {
this.descentLeft(nextMin.right);
}
return nextMin.val;
}
public boolean hasNext() {
return this.stack.size() > 0;
}
}