An OpenMP and non-OpenMP version of a C++ implementation of Floyd's algorithm was tested and compared. Results indicate dramatic speedup using OpenMP.
The single threaded version goes row-by-row through the matrix and calculates the score. The multi-threaded version using parallel OpenMP for loops.
C++14 standard library with GCC 5.2 was chosen due to ease of implementing OpenMP. The OMP_NUM_THREADS environment variable was used to control the number of OpenMP threads. Level 2 optimizations were also compared in the tests due to anecdotal evidence resulting in reduced processing time.
A Macbook Pro, Early 2015 with a 2.7GHz Core i5 processor with 8GB of DDR3 RAM was used for compilation and test runs. A Linux VM with Arch Linux and GCC 5.2 were used.
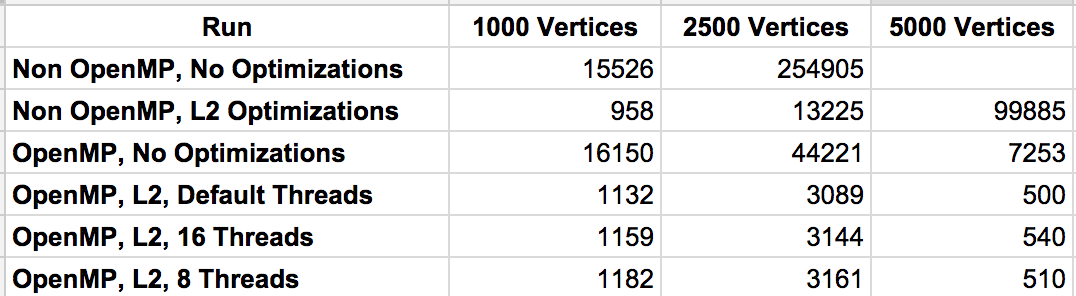
Here is the raw data of the test runs.
Here is the comparison of the data, graphed.
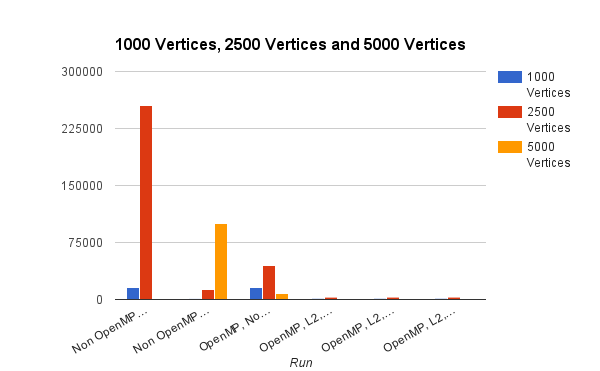
Both L2 optimizations and OpenMP have profound effect on processing time.
OpenMP reduced the processing time in all cases. L2 optimizations are also tuned to help in the case of nested for loops.