Develop a system that can generate a dance choreography of variable length for multiple performers. The output should be a 3D rendering which can be used by every individual dancer to study their part, e.g.:
| Frame 1 | Frame n |
|---|---|
 |
 |
Research on generative algorithms suited for this project revealed that a framework containing (a) neural network(s) could be used to achieve the desired outcome. Such a framework could be trained with existing choreographic sequences (video or motion capture) to generate new sequences. As already mentioned, neural networks usually require a training phase before they can generate new output or classify things etc. Therefor the system described here, reflects those phases.

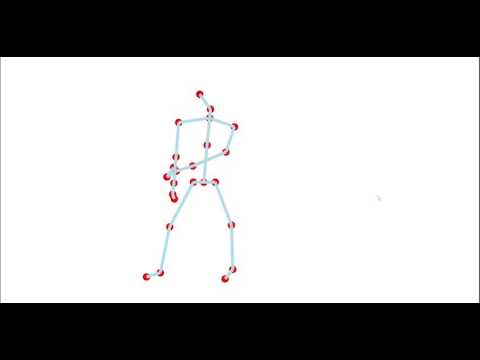
It is desired to design a system that works on so called keypoints, as the basic data structure for all phases. A keypoint reflects a joint in the human body, and sequences of keypoints can be easily retreived from pose recognition software ran on images or by using a Kinect to do a basic motion capture. Choreographic sequences used to build this system and also as output of such, are described with keypoints. A sequence is just a list of keypoints.
Alternatively to keypoints, an existing dance notation, e.g. Laban notation, could have been used as the base for all phases. But since this would require additional image recogition and 3D rendering code specifically written for such a visual notation, keypoints were chosen to be the base data structure for this project.

The above led to a system design that is split into multiple phases. Each phase is then implemented using one or more of the compoments described later in this section.
All motion generation is depending on a good training set. Good in this case means sufficiently large and also reflecting the style of the motions wanted.
This can only be achieved be recording dancers performing certain qualities and simple as well as complex movements [1].
Image or video-based keypoint extraction
OpenPose [2]
Since it is required to record the same scene from multiple views in order to perform 3D reconstruction, a test arrangement, ideally built in a rehearsal environment, needs to be created. This should include 4 Cameras, arranged on the rehearsal stage.
https://www.tensorflow.org/lite/models/pose_estimation/overview https://github.com/deephdc/posenet-tf
https://getrad.co/studio-product/
https://www.tensorflow.org/lite/models/pose_estimation/overview https://github.com/atomicbits/posenet-python
https://www.youtube.com/watch?v=GPjS0SBtHwY
A lot of groundwork has been done by Luka Crnkovic-Friis and Louise Crnkovic-Friis outlined in Generative Choreography using Deep Learning.
Store motion sequences in plain text files and create tool that can render them.
This section desribes a first draft of a system that could perform all phases. Components share interfaces which make them interchangeable.
OpenPose is an open-source toolkit which allows human pose estimation. It uses a pre-trained neural network to find keypoints in images and videos. If used with multiple cameras, captering multiple views of the same scene, it is able to perform 3D reconstruction. The output of OpenPose are JSON files which contain detected keypoints:
| Still | OpenPose result |
|---|---|
 |
 |
 |
 |
Since OpenPose requires the same scene recorded from multiple views in order to perform 3D reconstruction, a test arrangement, ideally built in a rehearsal environment, needs to be created. This should include 4 Cameras, arranged on the rehearsal stage.
All videos will be tagged and archived for further analysis.
The output of OpenPose, which is JSON, needs to be transformed in order to be read in phase 2. The JSON output needs to be parsed and only keypoints detected by the 3d reconstruction should be saved in the final output.
The transformation should create a format that is easily translatable to tensors.
Try implementing the method outlined in Generative Choreography using Deep Learning by Peltarion (Luka Crnkovic-Friis and Louise Crnkovic-Friis).
The re-implementation of chor-rnn (our name here) should then produce motion sequences and output them in a simple CSV format.
Even though rendering of sequences is a relatively simple task, it needs to be implemented early and should come with as less overhead as possible, such that the focus can stay on the actual training and learning process.
Therefor a simple rendering stage witten in Rust and based on the Kiss3D engine was choosen.
The naive in memory size estimation
In case of a 1 hour sequence at 25 fps: