diff --git a/docs/blog/posts/benchmark-amd-containers-and-partitions.md b/docs/blog/posts/benchmark-amd-containers-and-partitions.md
new file mode 100644
index 0000000000..4df51c1263
--- /dev/null
+++ b/docs/blog/posts/benchmark-amd-containers-and-partitions.md
@@ -0,0 +1,491 @@
+---
+title: "Benchmarking AMD GPUs: bare-metal, containers, partitions"
+date: 2025-07-15
+description: "TBA"
+slug: benchmark-amd-containers-and-partitions
+image: https://dstack.ai/static-assets/static-assets/images/benchmark-amd-containers-and-partitions.png
+categories:
+ - Benchmarks
+---
+
+# Benchmarking AMD GPUs: bare-metal, containers, partitions
+
+Our new benchmark explores two important areas for optimizing AI workloads on AMD GPUs: First, do containers introduce a performance penalty for network-intensive tasks compared to a bare-metal setup? Second, how does partitioning a powerful GPU like the MI300X affect its real-world performance for different types of AI workloads?
+
+ +
+This benchmark was supported by [Hot Aisle :material-arrow-top-right-thin:{ .external }](https://hotaisle.xyz/){:target="_blank"},
+a provider of AMD GPU bare-metal and VM infrastructure.
+
+
+
+## Benchmark 1: Bare-metal vs containers
+
+### Finding 1: No loss in interconnect bandwidth
+
+A common concern is that the abstraction layer of containers might slow down communication between GPUs on different nodes. To test this, we measured interconnect performance using two critical methods: high-level RCCL collectives (AllGather, AllReduce) essential for distributed AI, and low-level RDMA write tests for a raw measure of network bandwidth.
+
+#### AllGather
+
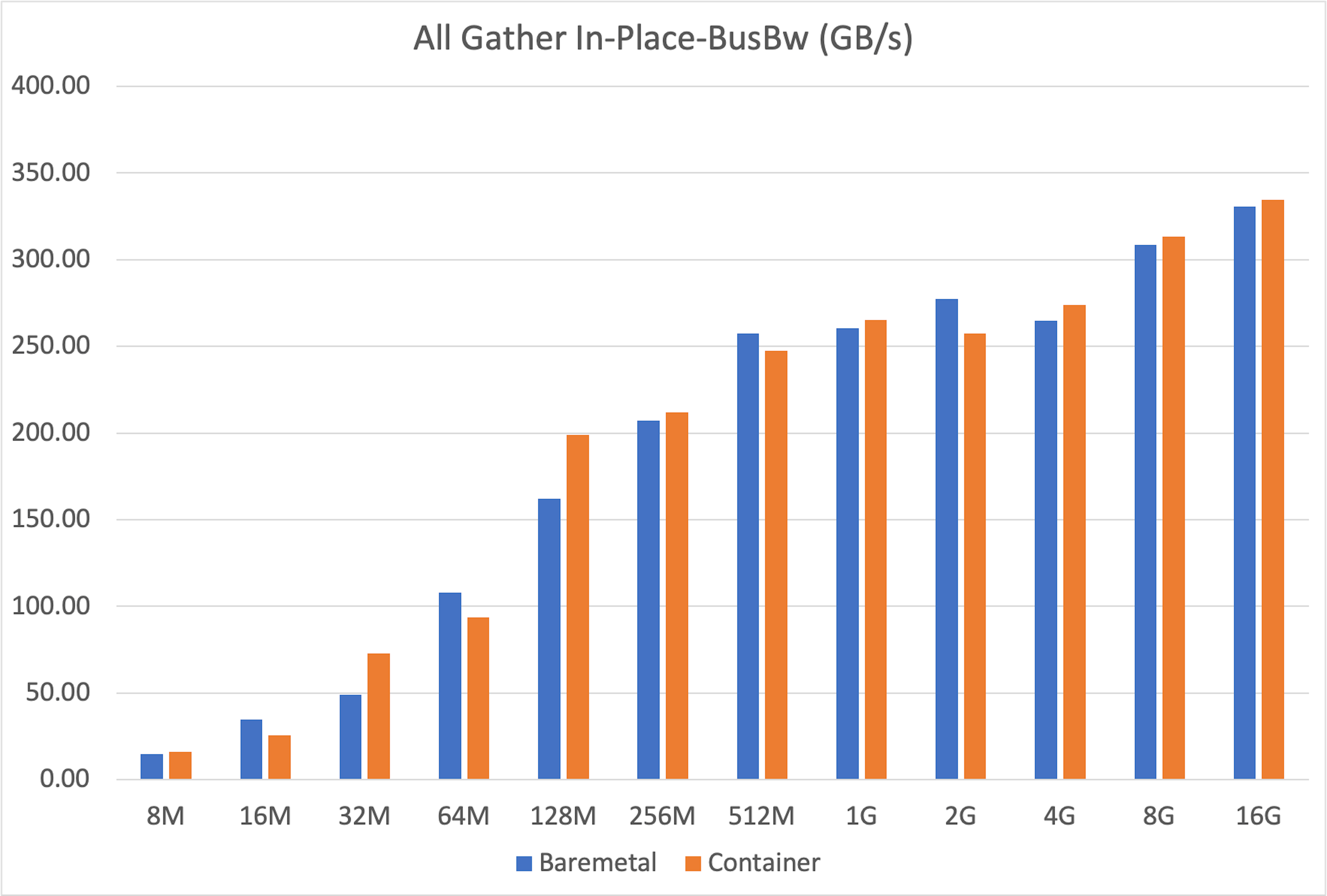
+The `all_gather` operation is crucial for tasks like tensor-parallel inference, where results from multiple GPUs must be combined. Our tests showed that container performance almost perfectly matched bare-metal across message sizes from 8MB to 16GB.
+
+
+
+This benchmark was supported by [Hot Aisle :material-arrow-top-right-thin:{ .external }](https://hotaisle.xyz/){:target="_blank"},
+a provider of AMD GPU bare-metal and VM infrastructure.
+
+
+
+## Benchmark 1: Bare-metal vs containers
+
+### Finding 1: No loss in interconnect bandwidth
+
+A common concern is that the abstraction layer of containers might slow down communication between GPUs on different nodes. To test this, we measured interconnect performance using two critical methods: high-level RCCL collectives (AllGather, AllReduce) essential for distributed AI, and low-level RDMA write tests for a raw measure of network bandwidth.
+
+#### AllGather
+
+The `all_gather` operation is crucial for tasks like tensor-parallel inference, where results from multiple GPUs must be combined. Our tests showed that container performance almost perfectly matched bare-metal across message sizes from 8MB to 16GB.
+
+ +
+#### AllReduce
+
+Similarly, `all_reduce` is the backbone of distributed training, used for synchronizing gradients. Once again, the results were clear: containers performed just as well as bare-metal.
+
+
+
+#### AllReduce
+
+Similarly, `all_reduce` is the backbone of distributed training, used for synchronizing gradients. Once again, the results were clear: containers performed just as well as bare-metal.
+
+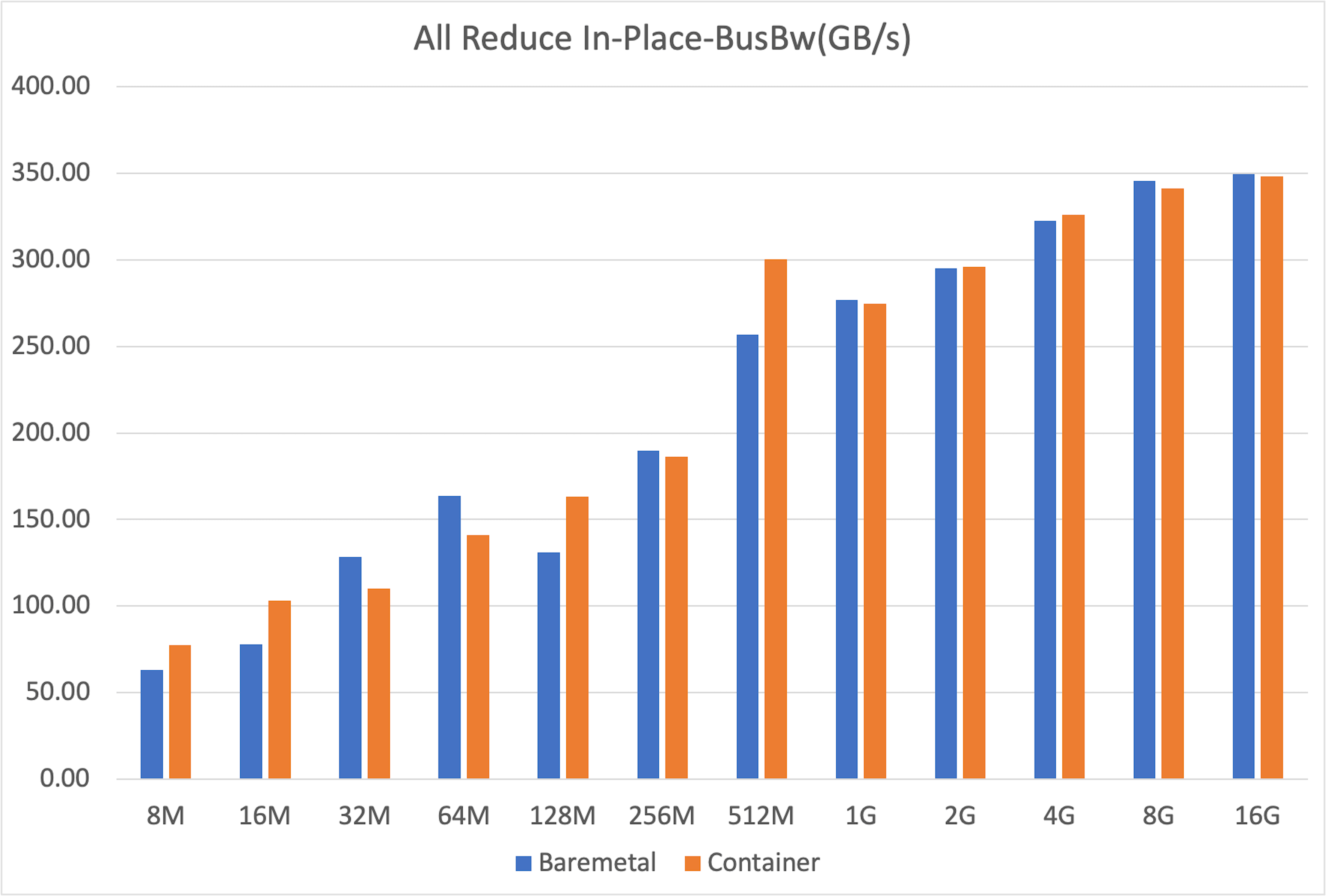 +
+Both bare-metal and container setups achieved nearly identical peak bus bandwidth (around 350 GB/s for 16GB messages), confirming that containerization does not hinder this fundamental collective operation.
+
+??? info "Variability"
+ Both setups showed some variability at smaller message sizes—typical behavior due to kernel launch latencies—but converged to stable, identical peak bandwidths for larger transfers. The fluctuations at smaller sizes are likely caused by non-deterministic factors such as CPU-induced pauses during GPU kernel launches, occasionally favoring one setup over the other.
+
+#### RDMA write
+
+To isolate the network from any framework overhead, we ran direct device-to-device RDMA write tests. This measures the raw data transfer speed between GPUs in different nodes.
+
+
+
+Both bare-metal and container setups achieved nearly identical peak bus bandwidth (around 350 GB/s for 16GB messages), confirming that containerization does not hinder this fundamental collective operation.
+
+??? info "Variability"
+ Both setups showed some variability at smaller message sizes—typical behavior due to kernel launch latencies—but converged to stable, identical peak bandwidths for larger transfers. The fluctuations at smaller sizes are likely caused by non-deterministic factors such as CPU-induced pauses during GPU kernel launches, occasionally favoring one setup over the other.
+
+#### RDMA write
+
+To isolate the network from any framework overhead, we ran direct device-to-device RDMA write tests. This measures the raw data transfer speed between GPUs in different nodes.
+
+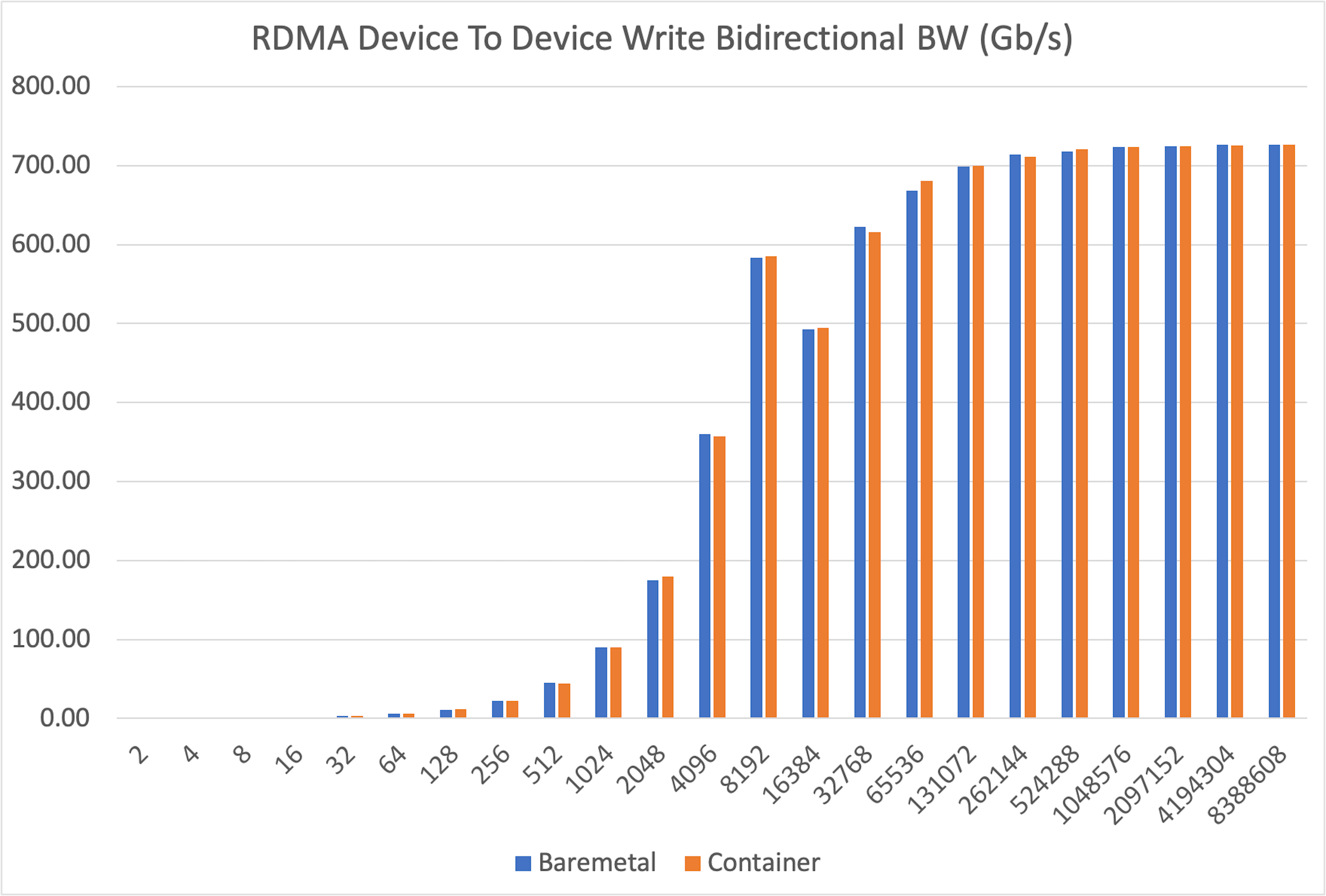 +
+The results were definitive: bidirectional bandwidth was virtually identical in both bare-metal and container environments across all message sizes, from a tiny 2 bytes up to 8MB.
+
+#### Conclusion
+
+Our experiments consistently demonstrate that running multi-node AI workloads inside containers does not degrade interconnect performance. The performance of RCCL collectives and raw RDMA bandwidth on AMD GPUs is on par with a bare-metal configuration. This debunks the myth of a "container tax" and validates containers as a first-class choice for scalable AI infrastructure.
+
+## Benchmark 2: Partition performance isolated vs mesh
+
+The AMD GPU can be [partitioned :material-arrow-top-right-thin:{ .external }](https://instinct.docs.amd.com/projects/amdgpu-docs/en/latest/gpu-partitioning/mi300x/overview.html){:target="_blank"} into smaller, independent units (e.g., NPS4 mode splits one GPU into four partitions). This promises better memory bandwidth utilization. Does this theoretical gain translate to better performance in practice?
+
+### Finding 1: Higher performance for isolated partitions
+
+First, we sought to reproduce and extend findings from the [official ROCm blog :material-arrow-top-right-thin:{ .external }](https://rocm.blogs.amd.com/software-tools-optimization/compute-memory-modes/README.html){:target="_blank"}. We benchmarked the memory bandwidth of a single partition (in CPX/NPS4 mode) against a full, unpartitioned GPU (in SPX/NPS1 mode).
+
+
+
+The results were definitive: bidirectional bandwidth was virtually identical in both bare-metal and container environments across all message sizes, from a tiny 2 bytes up to 8MB.
+
+#### Conclusion
+
+Our experiments consistently demonstrate that running multi-node AI workloads inside containers does not degrade interconnect performance. The performance of RCCL collectives and raw RDMA bandwidth on AMD GPUs is on par with a bare-metal configuration. This debunks the myth of a "container tax" and validates containers as a first-class choice for scalable AI infrastructure.
+
+## Benchmark 2: Partition performance isolated vs mesh
+
+The AMD GPU can be [partitioned :material-arrow-top-right-thin:{ .external }](https://instinct.docs.amd.com/projects/amdgpu-docs/en/latest/gpu-partitioning/mi300x/overview.html){:target="_blank"} into smaller, independent units (e.g., NPS4 mode splits one GPU into four partitions). This promises better memory bandwidth utilization. Does this theoretical gain translate to better performance in practice?
+
+### Finding 1: Higher performance for isolated partitions
+
+First, we sought to reproduce and extend findings from the [official ROCm blog :material-arrow-top-right-thin:{ .external }](https://rocm.blogs.amd.com/software-tools-optimization/compute-memory-modes/README.html){:target="_blank"}. We benchmarked the memory bandwidth of a single partition (in CPX/NPS4 mode) against a full, unpartitioned GPU (in SPX/NPS1 mode).
+
+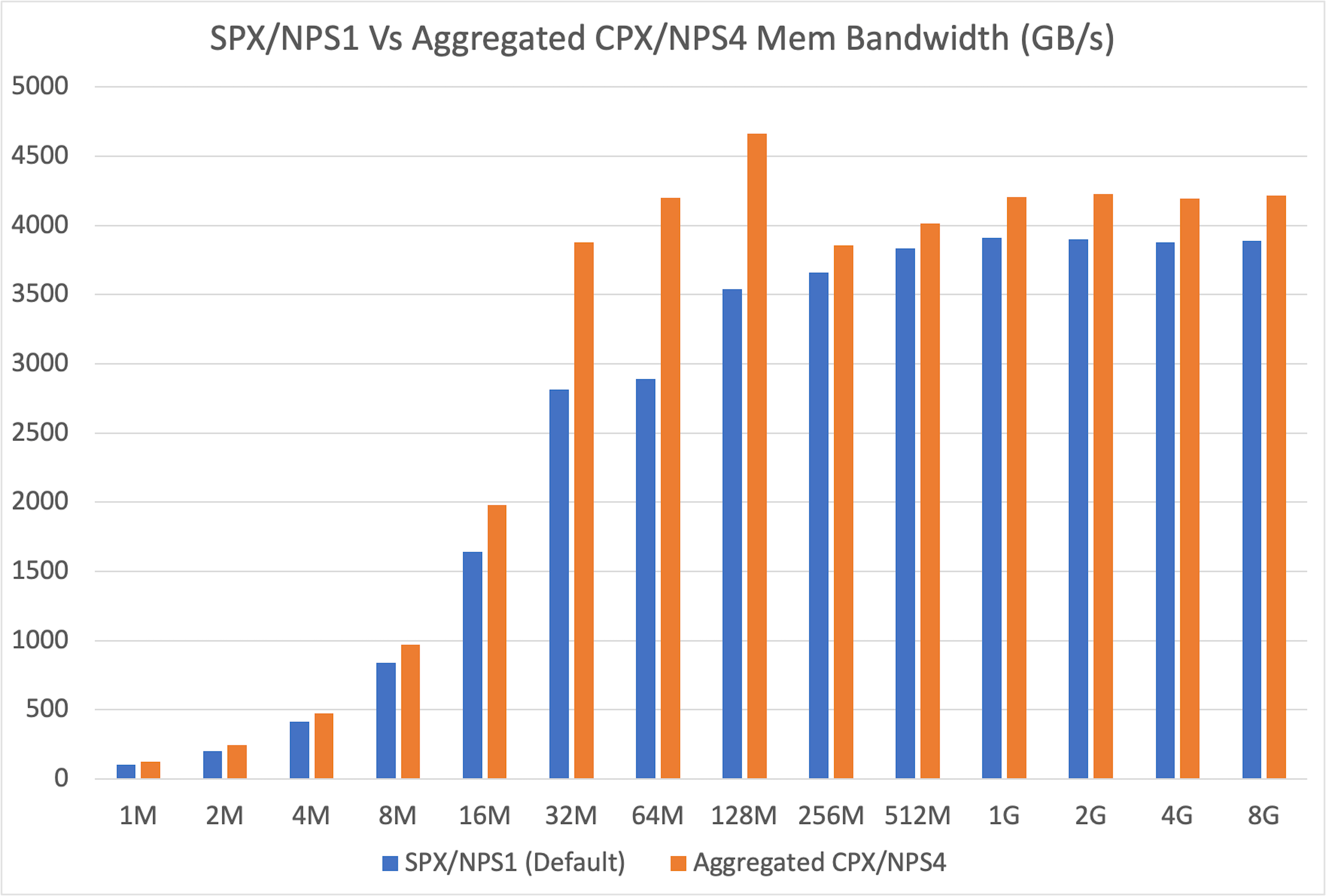 +
+Our results confirmed that a single partition offers superior memory bandwidth. After aggregating the results to ensure an apples-to-apples comparison, we found the partitioned mode delivered consistently higher memory bandwidth across all message sizes, with especially large gains in the 32MB to 128MB range.
+
+### Finding 2: Worse performance for partition meshes
+
+Our benchmark showed that isolated partitions in CPX/NPS4 mode deliver strong memory bandwidth. But can these partitions work efficiently together in mesh scenarios? If performance drops when partitions communicate or share load, the GPU loses significant value for real-world workloads.
+
+#### Data-parallel inference
+
+We ran eight independent vLLM instances on eight partitions of a single MI300X and compared their combined throughput against one vLLM instance on a single unpartitioned GPU. The single GPU was significantly faster, and the performance gap widened as the request rate increased. The partitions were starved for memory, limiting their ability to handle the KV cache for a high volume of requests.
+
+
+
+Our results confirmed that a single partition offers superior memory bandwidth. After aggregating the results to ensure an apples-to-apples comparison, we found the partitioned mode delivered consistently higher memory bandwidth across all message sizes, with especially large gains in the 32MB to 128MB range.
+
+### Finding 2: Worse performance for partition meshes
+
+Our benchmark showed that isolated partitions in CPX/NPS4 mode deliver strong memory bandwidth. But can these partitions work efficiently together in mesh scenarios? If performance drops when partitions communicate or share load, the GPU loses significant value for real-world workloads.
+
+#### Data-parallel inference
+
+We ran eight independent vLLM instances on eight partitions of a single MI300X and compared their combined throughput against one vLLM instance on a single unpartitioned GPU. The single GPU was significantly faster, and the performance gap widened as the request rate increased. The partitions were starved for memory, limiting their ability to handle the KV cache for a high volume of requests.
+
+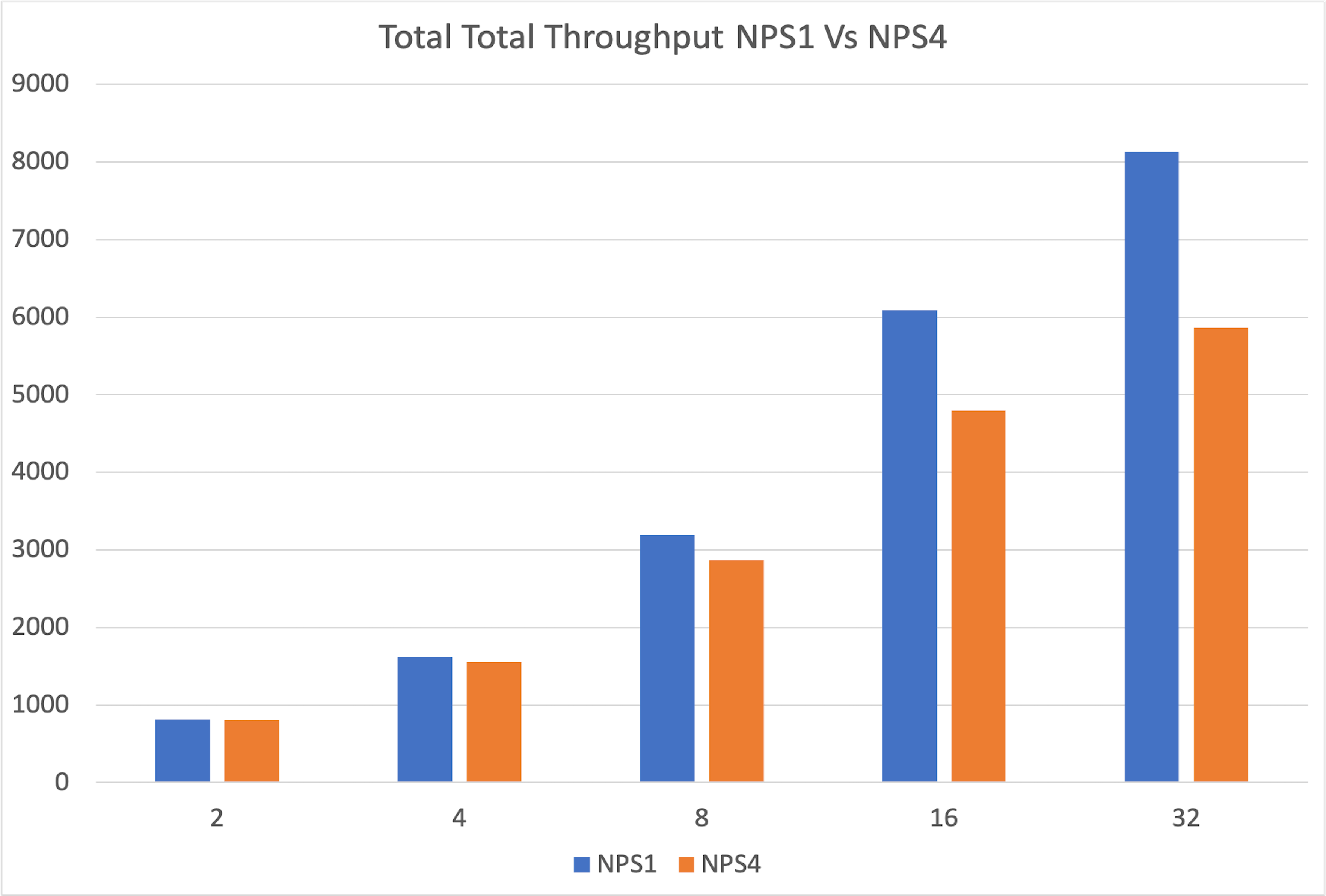 +
+The degradation stems from increased memory pressure, as each partition has only a fraction of GPU memory, limiting its ability to handle larger workloads efficiently.
+
+#### Tensor-parallel inference
+
+We built a toy inference benchmark with PyTorch’s native distributed support to simulate Tensor Parallelism. A single GPU in SPX/NPS1 mode significantly outperformed the combined throughput of 8xCPX/NPS4 partitions.
+
+
+
+The degradation stems from increased memory pressure, as each partition has only a fraction of GPU memory, limiting its ability to handle larger workloads efficiently.
+
+#### Tensor-parallel inference
+
+We built a toy inference benchmark with PyTorch’s native distributed support to simulate Tensor Parallelism. A single GPU in SPX/NPS1 mode significantly outperformed the combined throughput of 8xCPX/NPS4 partitions.
+
+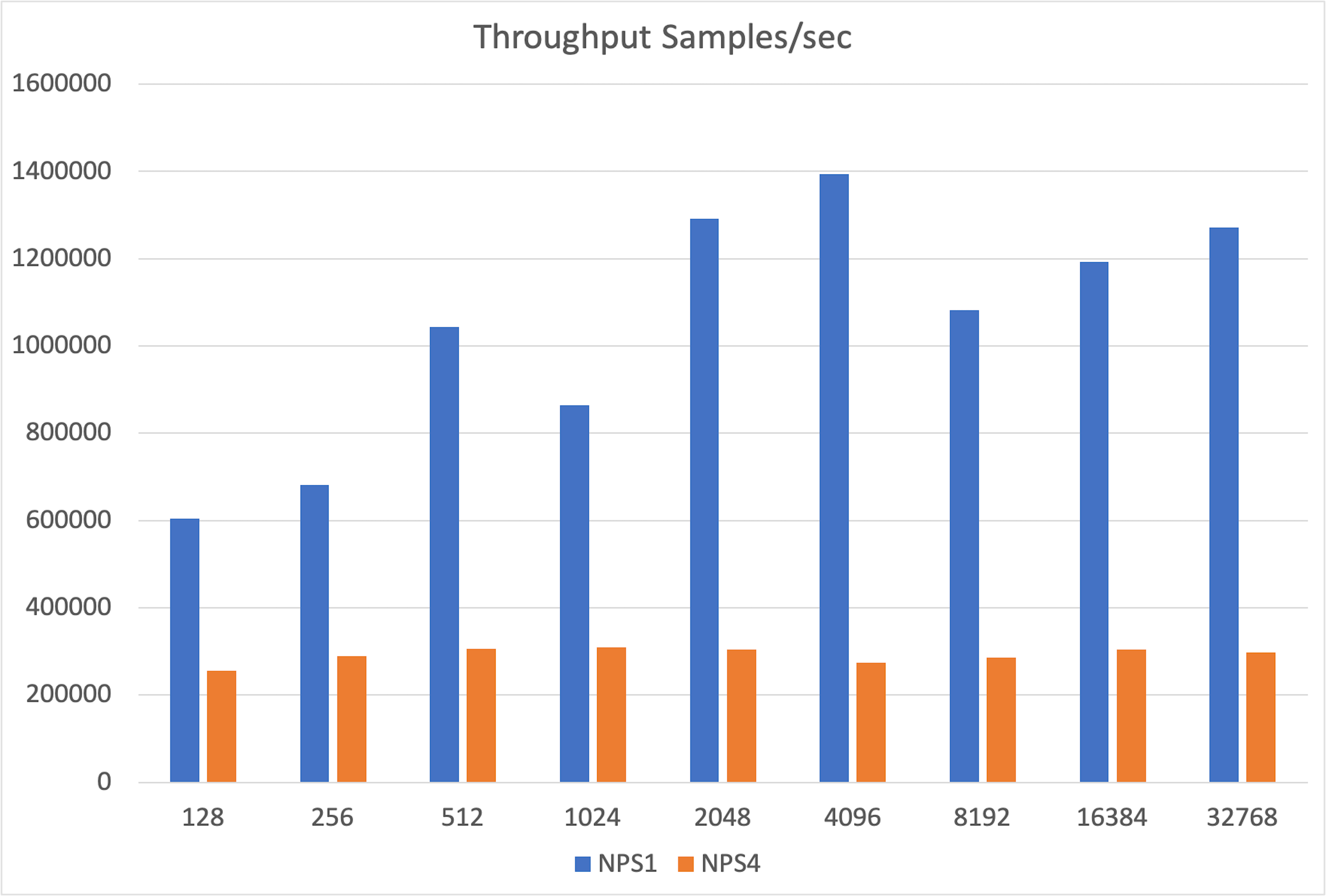 +
+The gap stems from the overhead of collective operations like `all_gather`, which are needed to synchronize partial outputs across GPU partitions.
+
+#### Conclusion
+
+Although GPU partitioning provides a memory bandwidth boost in isolated microbenchmarks, this benefit does not carry over to practical inference scenarios.
+
+In reality, performance is limited by two factors:
+
+1. **Reduced memory**: Each partition has only a fraction of the GPU's total HBM, creating a bottleneck for memory-hungry tasks like storing KV caches.
+2. **Communication overhead**: When partitions must work together, the cost of communication between them negates the performance gains.
+
+GPU partitioning is only practical if used dynamically—for instance, to run multiple small development jobs or lightweight models, and then "unfractioning" the GPU back to its full power for larger, more demanding workloads.
+
+#### Limitations
+
+1. **Reproducibility**: AMD’s original blog post on partitioning lacked detailed setup information, so we had to reconstruct the benchmarks independently.
+2. **Network tuning**: These benchmarks were run on a default, out-of-the-box network configuration. Our results for RCCL (~339 GB/s) and RDMA (~726 Gbps) are slightly below the peak figures [reported by Dell :material-arrow-top-right-thin:{ .external }](https://infohub.delltechnologies.com/en-us/l/generative-ai-in-the-enterprise-with-amd-accelerators/rccl-and-perftest-for-cluster-validation-1/4/){:target="_blank"}. This suggests that further performance could be unlocked with expert tuning of network topology, MTU size, and NCCL environment variables.
+
+## Benchmark setup
+
+### Hardware configuration
+
+Two nodes with below specifications:
+
+* Dell PowerEdge XE9680 (MI300X)
+* CPU: 2 x Intel Xeon Platinum 8462Y+
+* RAM: 2.0 TiB
+* GPU: 8 x AMD MI300X
+* OS: Ubuntu 22.04.5 LTS
+* ROCm: 6.4.1
+* AMD SMI: 25.4.2+aca1101
+
+### Benchmark methodology
+
+The full, reproducible steps are available in our GitHub repository. Below is a summary of the approach.
+
+#### Creating a fleet
+
+We first defined a `dstack` [SSH fleet](../../docs/concepts/fleets.md#ssh) to manage the two-node cluster.
+
+```yaml
+type: fleet
+name: hotaisle-fleet
+placement: any
+ssh_config:
+ user: hotaisle
+ identity_file: ~/.ssh/id_rsa
+ hosts:
+ - hostname: ssh.hotaisle.cloud
+ port: 22007
+ - hostname: ssh.hotaisle.cloud
+ port: 22015
+```
+
+#### Bare-metal
+
+**RCCL tests**
+
+1. Install OpenMPI:
+
+```shell
+apt install libopenmpi-dev openmpi-bin
+```
+
+2. Clone the RCCL tests repository
+
+```shell
+git clone https://github.com/ROCm/rccl-tests.git
+```
+
+3. Build RCCL tests
+
+```shell
+cd rccl-tests
+make MPI=1 MPI_HOME=$OPEN_MPI_HOME
+```
+
+4. Create a hostfile with node IPs
+
+```shell
+cat > hostfile <
+
+The gap stems from the overhead of collective operations like `all_gather`, which are needed to synchronize partial outputs across GPU partitions.
+
+#### Conclusion
+
+Although GPU partitioning provides a memory bandwidth boost in isolated microbenchmarks, this benefit does not carry over to practical inference scenarios.
+
+In reality, performance is limited by two factors:
+
+1. **Reduced memory**: Each partition has only a fraction of the GPU's total HBM, creating a bottleneck for memory-hungry tasks like storing KV caches.
+2. **Communication overhead**: When partitions must work together, the cost of communication between them negates the performance gains.
+
+GPU partitioning is only practical if used dynamically—for instance, to run multiple small development jobs or lightweight models, and then "unfractioning" the GPU back to its full power for larger, more demanding workloads.
+
+#### Limitations
+
+1. **Reproducibility**: AMD’s original blog post on partitioning lacked detailed setup information, so we had to reconstruct the benchmarks independently.
+2. **Network tuning**: These benchmarks were run on a default, out-of-the-box network configuration. Our results for RCCL (~339 GB/s) and RDMA (~726 Gbps) are slightly below the peak figures [reported by Dell :material-arrow-top-right-thin:{ .external }](https://infohub.delltechnologies.com/en-us/l/generative-ai-in-the-enterprise-with-amd-accelerators/rccl-and-perftest-for-cluster-validation-1/4/){:target="_blank"}. This suggests that further performance could be unlocked with expert tuning of network topology, MTU size, and NCCL environment variables.
+
+## Benchmark setup
+
+### Hardware configuration
+
+Two nodes with below specifications:
+
+* Dell PowerEdge XE9680 (MI300X)
+* CPU: 2 x Intel Xeon Platinum 8462Y+
+* RAM: 2.0 TiB
+* GPU: 8 x AMD MI300X
+* OS: Ubuntu 22.04.5 LTS
+* ROCm: 6.4.1
+* AMD SMI: 25.4.2+aca1101
+
+### Benchmark methodology
+
+The full, reproducible steps are available in our GitHub repository. Below is a summary of the approach.
+
+#### Creating a fleet
+
+We first defined a `dstack` [SSH fleet](../../docs/concepts/fleets.md#ssh) to manage the two-node cluster.
+
+```yaml
+type: fleet
+name: hotaisle-fleet
+placement: any
+ssh_config:
+ user: hotaisle
+ identity_file: ~/.ssh/id_rsa
+ hosts:
+ - hostname: ssh.hotaisle.cloud
+ port: 22007
+ - hostname: ssh.hotaisle.cloud
+ port: 22015
+```
+
+#### Bare-metal
+
+**RCCL tests**
+
+1. Install OpenMPI:
+
+```shell
+apt install libopenmpi-dev openmpi-bin
+```
+
+2. Clone the RCCL tests repository
+
+```shell
+git clone https://github.com/ROCm/rccl-tests.git
+```
+
+3. Build RCCL tests
+
+```shell
+cd rccl-tests
+make MPI=1 MPI_HOME=$OPEN_MPI_HOME
+```
+
+4. Create a hostfile with node IPs
+
+```shell
+cat > hostfile <