diff --git a/docs/assets/stylesheets/extra.css b/docs/assets/stylesheets/extra.css
index 45d69f9067..d42a749182 100644
--- a/docs/assets/stylesheets/extra.css
+++ b/docs/assets/stylesheets/extra.css
@@ -1318,10 +1318,6 @@ html .md-footer-meta.md-typeset a:is(:focus,:hover) {
display: none;
}
- .md-tabs__item:nth-child(7) {
- display: none;
- }
-
/* .md-tabs__item:nth-child(5):after {
content: url('data:image/svg+xml,');
line-height: 14px;
diff --git a/docs/blog/posts/digitalocean-and-amd-dev-cloud.md b/docs/blog/posts/digitalocean-and-amd-dev-cloud.md
new file mode 100644
index 0000000000..7560c7ccbb
--- /dev/null
+++ b/docs/blog/posts/digitalocean-and-amd-dev-cloud.md
@@ -0,0 +1,151 @@
+---
+title: Orchestrating GPUs on DigitalOcean and AMD Developer Cloud
+date: 2025-09-04
+description: "TBA"
+slug: digitalocean-and-amd-dev-cloud
+image: https://dstack.ai/static-assets/static-assets/images/digitalocean-and-amd-dev-cloud.png
+categories:
+ - Changelog
+---
+
+# Orchestrating GPUs on DigitalOcean and AMD Developer Cloud
+
+Orchestration automates provisioning, running jobs, and tearing them down. While Kubernetes and Slurm are powerful in their domains, they lack the lightweight, GPU-native focus modern teams need to move faster.
+
+`dstack` is built entirely around GPUs. Our latest update introduces native integration with [DigitalOcean :material-arrow-top-right-thin:{ .external }](https://www.digitalocean.com/products/gradient/gpu-droplets){:target="_blank"} and
+[AMD Developer Cloud :material-arrow-top-right-thin:{ .external }](https://www.amd.com/en/developer/resources/cloud-access/amd-developer-cloud.html){:target="_blank"}, enabling teams to provision cloud GPUs and run workloads more cost-efficiently.
+
+
+
+
+
+## About Digital Ocean
+
+DigitalOcean is one of the leading cloud platforms offering GPUs both as VMs and as bare-metal clusters equipped with NVIDIA and AMD GPUs.
+
+## About AMD Developer Cloud
+
+AMD Developer Cloud is a new cloud platform designed to make AMD GPUs easily accessible to developers, academics, open-source contributors, and AI innovators worldwide.
+
+## Why dstack
+
+Unlike Kubernetes, dstack provides a high-level, AI-engineer-friendly interface where GPUs work out of the box—no custom operators or low-level setup required. Unlike Slurm, it’s use-case agnostic, equally suited for training, inference, benchmarking, and dev environments.
+
+With the new DigitalOcean and AMD Developer Cloud backends, you can now provision NVIDIA or AMD GPU VMs and run workloads with a single CLI command.
+
+## Getting started
+
+Best part about `dstack` is that it's very easy to get started.
+
+1. Create a project in Digital Ocean or AMD Developer Cloud
+2. Get credits or approve a payment method
+3. Create an API key
+
+Then, configure the backend in `~/.dstack/server/config.yml`:
+
+
+
+For more details, see [Installation](../../docs/installation/index.md).
+
+Use the `dstack` CLI to
+manage [dev environments](../../docs/concepts/dev-environments.md), [tasks](../../docs/concepts/tasks.md),
+and [services](../../docs/concepts/services.md).
+
+
+
+The `digitalocean` and `amddevcloud` backends support NVIDIA and AMD GPU VMs, respectively, and allow you to run
+[dev environments](../../docs/concepts/dev-environments.md) (interactive development), [tasks](../../docs/concepts/tasks.md)
+(training, fine-tuning, or other batch jobs), and [services](../../docs/concepts/services.md) (inference).
+
+Here’s an example of a service configuration:
+
+
+
+```yaml
+type: service
+name: gpt-oss-120b
+
+model: openai/gpt-oss-120b
+
+env:
+ - HF_TOKEN
+ - MODEL=openai/gpt-oss-120b
+ # To enable AITER, set below to 1. Otherwise, set it to 0.
+ - VLLM_ROCM_USE_AITER=1
+ # To enable AITER Triton unified attention
+ - VLLM_USE_AITER_UNIFIED_ATTENTION=1
+ # below is required in order to enable AITER unified attention by disabling AITER MHA
+ - VLLM_ROCM_USE_AITER_MHA=0
+image: rocm/vllm-dev:open-mi300-08052025
+commands:
+ - |
+ vllm serve $MODEL \
+ --tensor-parallel $DSTACK_GPUS_NUM \
+ --no-enable-prefix-caching \
+ --disable-log-requests \
+ --compilation-config '{"full_cuda_graph": true}'
+port: 8000
+
+volumes:
+ # Cache downloaded models
+ - /root/.cache/huggingface:/root/.cache/huggingface
+
+resources:
+ gpu: MI300X:8
+ shm_size: 32GB
+```
+
+
+
+As with any configuration, you can apply it via `dstack apply`. If needed, `dstack` will automatically provision new VMs and run the inference endpoint.
+
+
 +
+
+
+## About Digital Ocean
+
+DigitalOcean is one of the leading cloud platforms offering GPUs both as VMs and as bare-metal clusters equipped with NVIDIA and AMD GPUs.
+
+## About AMD Developer Cloud
+
+AMD Developer Cloud is a new cloud platform designed to make AMD GPUs easily accessible to developers, academics, open-source contributors, and AI innovators worldwide.
+
+## Why dstack
+
+Unlike Kubernetes, dstack provides a high-level, AI-engineer-friendly interface where GPUs work out of the box—no custom operators or low-level setup required. Unlike Slurm, it’s use-case agnostic, equally suited for training, inference, benchmarking, and dev environments.
+
+With the new DigitalOcean and AMD Developer Cloud backends, you can now provision NVIDIA or AMD GPU VMs and run workloads with a single CLI command.
+
+## Getting started
+
+Best part about `dstack` is that it's very easy to get started.
+
+1. Create a project in Digital Ocean or AMD Developer Cloud
+2. Get credits or approve a payment method
+3. Create an API key
+
+Then, configure the backend in `~/.dstack/server/config.yml`:
+
+
+
+
+
+## About Digital Ocean
+
+DigitalOcean is one of the leading cloud platforms offering GPUs both as VMs and as bare-metal clusters equipped with NVIDIA and AMD GPUs.
+
+## About AMD Developer Cloud
+
+AMD Developer Cloud is a new cloud platform designed to make AMD GPUs easily accessible to developers, academics, open-source contributors, and AI innovators worldwide.
+
+## Why dstack
+
+Unlike Kubernetes, dstack provides a high-level, AI-engineer-friendly interface where GPUs work out of the box—no custom operators or low-level setup required. Unlike Slurm, it’s use-case agnostic, equally suited for training, inference, benchmarking, and dev environments.
+
+With the new DigitalOcean and AMD Developer Cloud backends, you can now provision NVIDIA or AMD GPU VMs and run workloads with a single CLI command.
+
+## Getting started
+
+Best part about `dstack` is that it's very easy to get started.
+
+1. Create a project in Digital Ocean or AMD Developer Cloud
+2. Get credits or approve a payment method
+3. Create an API key
+
+Then, configure the backend in `~/.dstack/server/config.yml`:
+
+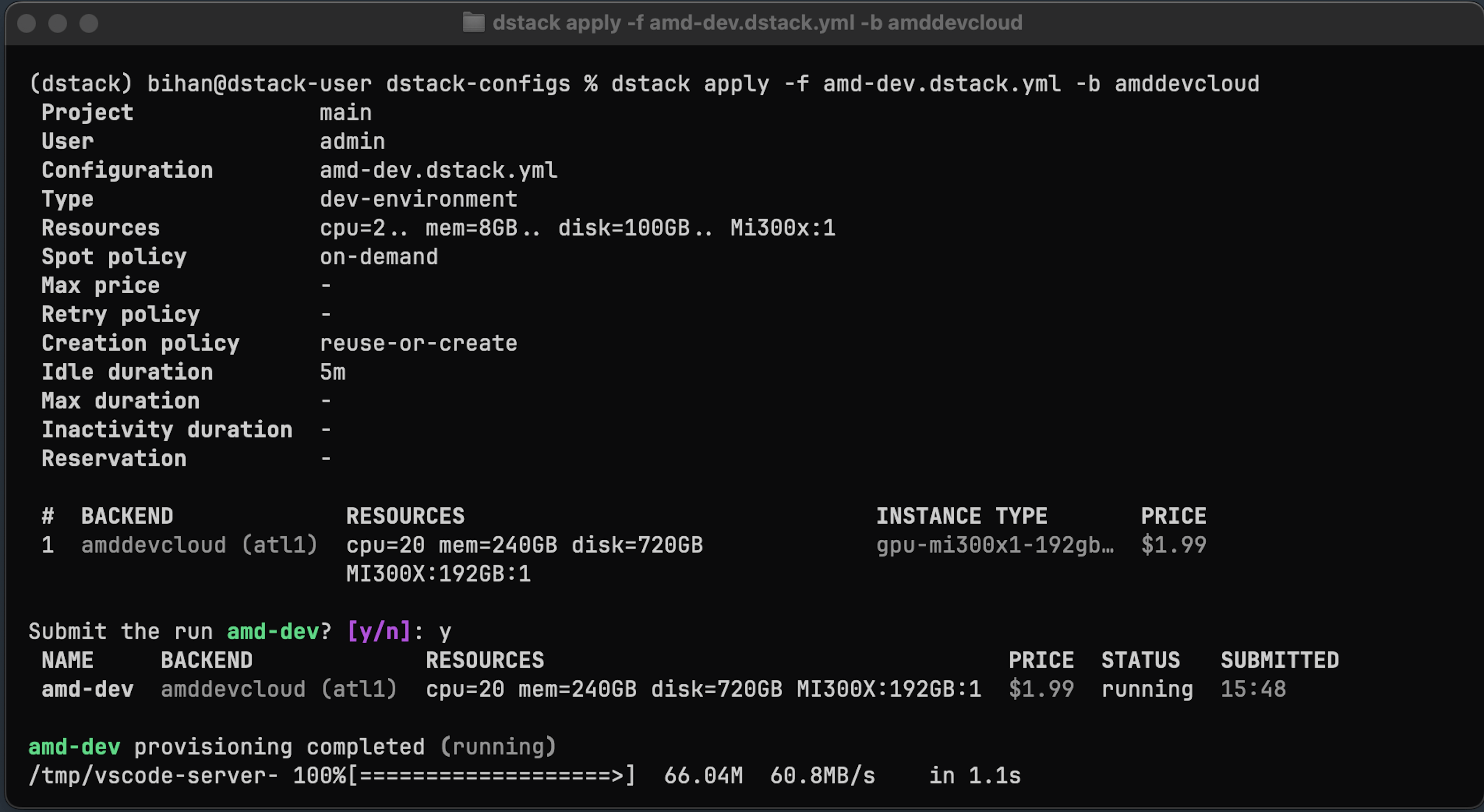 +
+The `digitalocean` and `amddevcloud` backends support NVIDIA and AMD GPU VMs, respectively, and allow you to run
+[dev environments](../../docs/concepts/dev-environments.md) (interactive development), [tasks](../../docs/concepts/tasks.md)
+(training, fine-tuning, or other batch jobs), and [services](../../docs/concepts/services.md) (inference).
+
+Here’s an example of a service configuration:
+
+
+
+The `digitalocean` and `amddevcloud` backends support NVIDIA and AMD GPU VMs, respectively, and allow you to run
+[dev environments](../../docs/concepts/dev-environments.md) (interactive development), [tasks](../../docs/concepts/tasks.md)
+(training, fine-tuning, or other batch jobs), and [services](../../docs/concepts/services.md) (inference).
+
+Here’s an example of a service configuration:
+
+