diff --git a/docs/blog/posts/kubernetes-beta.md b/docs/blog/posts/kubernetes-beta.md
new file mode 100644
index 0000000000..fc1e28b746
--- /dev/null
+++ b/docs/blog/posts/kubernetes-beta.md
@@ -0,0 +1,315 @@
+---
+title: Orchestrating GPUs on Kubernetes clusters
+date: 2025-10-08
+description: "TBA"
+slug: kubernetes-beta
+image: https://dstack.ai/static-assets/static-assets/images/dstack-kubernetes.png
+categories:
+ - Changelog
+---
+
+# Orchestrating GPUs on Kubernetes clusters
+
+`dstack` gives teams a unified way to run and manage GPU-native containers across clouds and on-prem environments — without requiring Kubernetes.
+At the same time, many organizations rely on Kubernetes as the foundation of their infrastructure.
+
+To support these users, `dstack` is releasing the beta of its native Kubernetes integration.
+
+ +
+
+
+This update allows `dstack` to orchestrate dev environments, distributed training, and inference workloads directly on Kubernetes clusters — combining the best of both worlds: an ML-tailored interface for ML teams together with the full Kubernetes ecosystem.
+
+Read below to learn on how to use `dstack` with Kubernetes clusters.
+
+## Creating a Kubernetes cluster
+
+A major advantage of Kubernetes is its portability. Whether you’re using managed Kubernetes on a GPU cloud or an on-prem cluster, you can connect it to `dstack` and use it to orchestrate your GPU workloads.
+
+!!! info "NVIDIA GPU Operator"
+ For `dstack` to correctly detect GPUs in your Kubernetes cluster, the cluster must have the
+ [NVIDIA GPU Operator :material-arrow-top-right-thin:{ .external }](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/index.html){:target="_blank"} pre-installed.
+
+### Nebius example
+
+If you're using [Nebius :material-arrow-top-right-thin:{ .external }](https://nebius.com/){:target="_blank"}, the process of creating a Kubernetes cluster is straightforward.
+
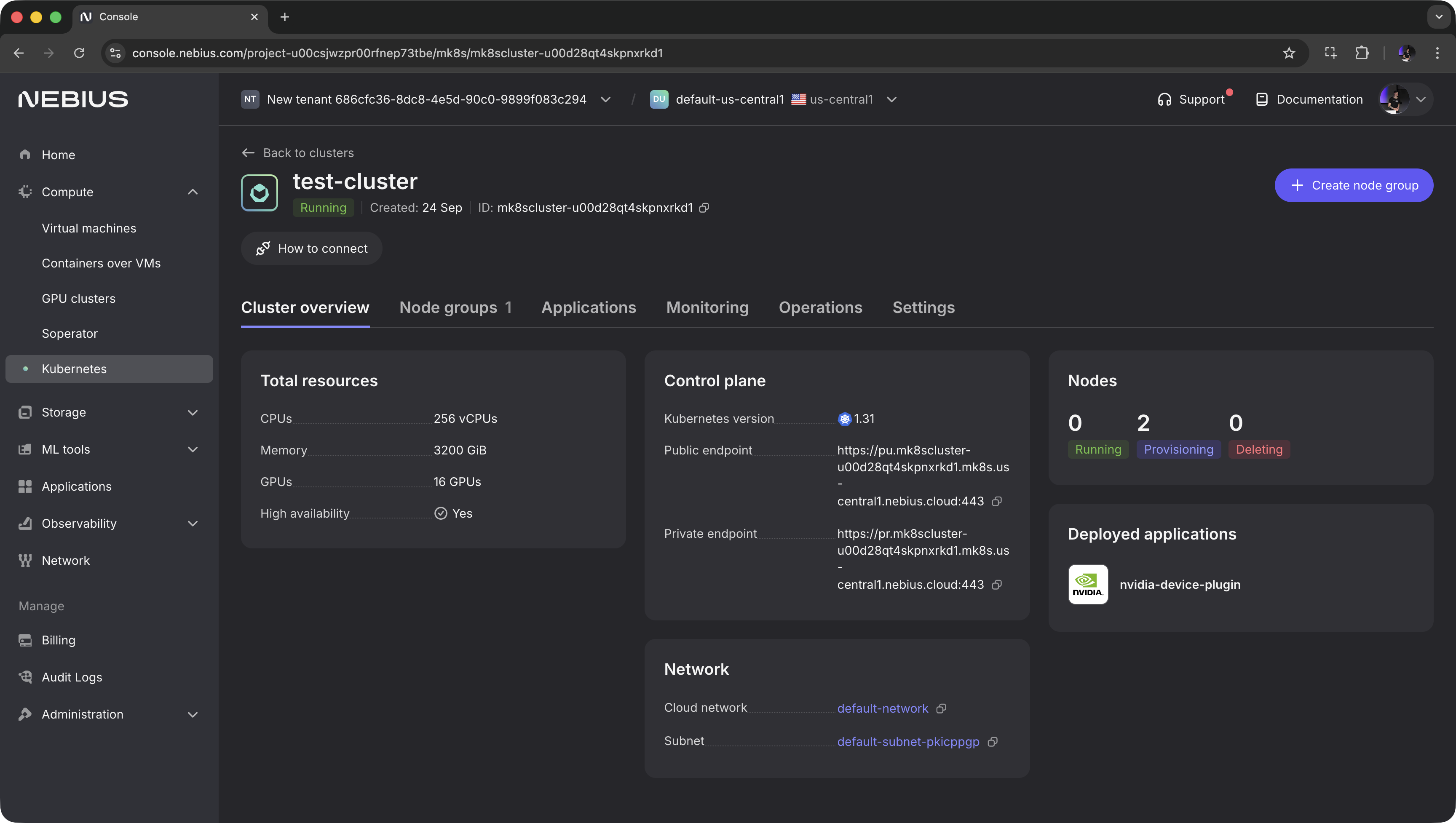
+Select the region of interest and click `Create cluster`.
+Once the cluster is created, switch to `Applications` and install the `nvidia-device-plugin` application — this can be done in one click.
+
+
+
+
+
+This update allows `dstack` to orchestrate dev environments, distributed training, and inference workloads directly on Kubernetes clusters — combining the best of both worlds: an ML-tailored interface for ML teams together with the full Kubernetes ecosystem.
+
+Read below to learn on how to use `dstack` with Kubernetes clusters.
+
+## Creating a Kubernetes cluster
+
+A major advantage of Kubernetes is its portability. Whether you’re using managed Kubernetes on a GPU cloud or an on-prem cluster, you can connect it to `dstack` and use it to orchestrate your GPU workloads.
+
+!!! info "NVIDIA GPU Operator"
+ For `dstack` to correctly detect GPUs in your Kubernetes cluster, the cluster must have the
+ [NVIDIA GPU Operator :material-arrow-top-right-thin:{ .external }](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/index.html){:target="_blank"} pre-installed.
+
+### Nebius example
+
+If you're using [Nebius :material-arrow-top-right-thin:{ .external }](https://nebius.com/){:target="_blank"}, the process of creating a Kubernetes cluster is straightforward.
+
+Select the region of interest and click `Create cluster`.
+Once the cluster is created, switch to `Applications` and install the `nvidia-device-plugin` application — this can be done in one click.
+
+ +
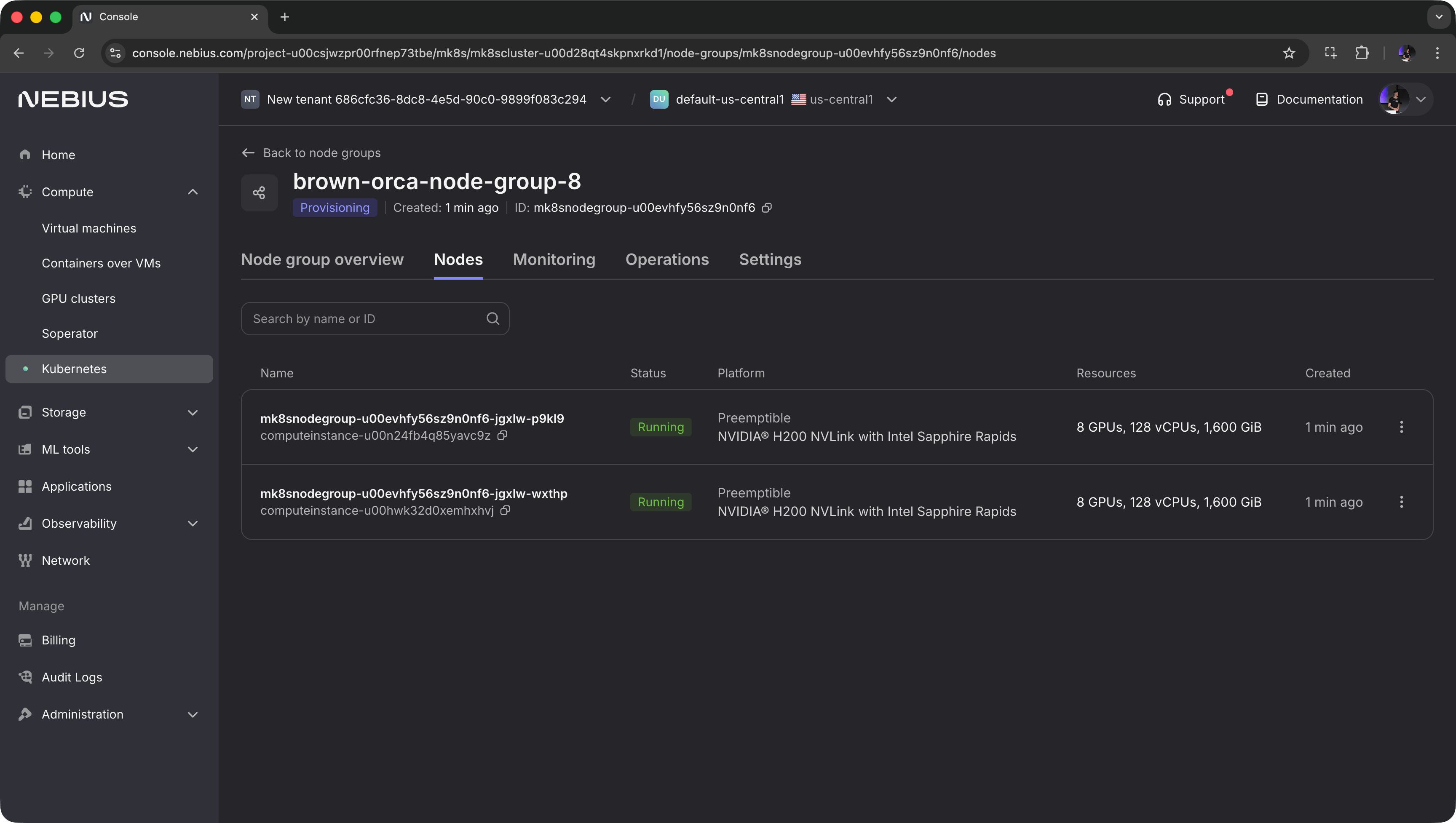
+Next, go to `Node groups` and click `Create node group`. Choose the GPU type and count, disk size, and other options.
+If `dstack` doesn't run in the same network, enable public IPs so that `dstack` can access the nodes.
+
+
+
+Next, go to `Node groups` and click `Create node group`. Choose the GPU type and count, disk size, and other options.
+If `dstack` doesn't run in the same network, enable public IPs so that `dstack` can access the nodes.
+
+ +
+## Setting up the backend
+
+Once the cluster is ready, you need to configure the `kubernetes` backend in the `dstack` server.
+To do this, add the corresponding configuration to your `~/.dstack/server/config.yml` file:
+
+
+
+## Setting up the backend
+
+Once the cluster is ready, you need to configure the `kubernetes` backend in the `dstack` server.
+To do this, add the corresponding configuration to your `~/.dstack/server/config.yml` file:
+
+
+
+```yaml
+projects:
+- name: main
+ backends:
+ - type: kubernetes
+ kubeconfig:
+ filename: ~/.kube/config
+ proxy_jump:
+ hostname: 204.12.171.137
+ port: 32000
+```
+
+
+
+The configuration includes two main parts: the path to the kubeconfig file and the proxy-jump configuration.
+
+If your cluster is on Nebius, click `How to connect` in the console — it will guide you through setting up the kubeconfig file.
+
+!!! info "Proxy jump"
+ To allow `dstack` to forward SSH traffic, it needs one node to act as a proxy jump.
+ Choose any node in the cluster and specify its IP address and an accessible port in the backend configuration.
+
+ Now that the backend is configured, go ahead and restart the `dstack server`.
+
+That’s it — you can now use all of `dstack`’s features, including [dev environments](../../docs/concepts/dev-environments.md), [tasks](../../docs/concepts/tasks.md), [services](../../docs/concepts/services.md), and [fleets](../../docs/concepts/fleets.md).
+
+## Running a dev environment
+
+A dev environment lets you provision an instance and connect to it from your desktop IDE.
+
+
+
+```yaml
+type: dev-environment
+# The name is optional, if not specified, generated randomly
+name: vscode
+
+python: "3.11"
+
+# Uncomment to use a custom Docker image
+#image: huggingface/trl-latest-gpu
+
+ide: vscode
+
+resources:
+ gpu: H200
+```
+
+
+
+To run a dev environment, pass the configuration to [`dstack apply`](../../docs/reference/cli/dstack/apply.md):
+
+
+
+```shell
+$ dstack apply -f examples/.dstack.yml
+
+ # BACKEND RESOURCES INSTANCE TYPE PRICE
+ 1 kubernetes (-) cpu=127 mem=1574GB disk=871GB H200:141GB:8 computeinstance-u00hwk32d0xemhxhvj $0
+ 2 kubernetes (-) cpu=127 mem=1574GB disk=871GB H200:141GB:8 computeinstance-u00n24fb4q85yavc9z $0
+
+Submit the run vscode? [y/n]: y
+
+Launching `vscode`...
+---> 100%
+
+To open in VS Code Desktop, use this link:
+ vscode://vscode-remote/ssh-remote+vscode/workflow
+```
+
+
+
+Dev environments support many [diffrent options](../../docs/concepts/dev-environments.md), including a custom Docker image, mounted repositories, idle timeout, min GPU utilization, and more.
+
+## Running distributed training
+
+Distributed training can be performed in `dstack` using [distributed tasks](../../docs/concepts/tasks.md#distributed-tasks).
+The configuration is similar to a dev environment, except it runs across multiple nodes.
+
+### Creating a cluster fleet
+
+Before running a distributed task, create a fleet with `placement` set to `cluster`:
+
+
+
+ ```yaml
+ type: fleet
+ # The name is optional; if not specified, one is generated automatically
+ name: my-k8s-fleet
+
+ # For `kubernetes`, `min` should be set to `0` since it can't pre-provision VMs.
+ # Optionally, you can set the maximum number of nodes to limit scaling.
+ nodes: 0..
+
+ placement: cluster
+
+ backends: [kuberenetes]
+
+ resources:
+ # Specify requirements to filter nodes
+ gpu: 1..8
+ ```
+
+
+
+Then, create the fleet using the `dstack apply` command:
+
+
+
+```shell
+$ dstack apply -f examples/misc/fleets/.dstack.yml
+
+Provisioning...
+---> 100%
+
+ FLEET INSTANCE BACKEND GPU PRICE STATUS CREATED
+```
+
+
+
+Once the fleet is created, you can run distributed tasks on it.
+
+### NCCL tests example
+
+Below is an example of using distributed tasks to run NCCL tests.
+It also demonstrates how to use mpirun with `dstack`:
+
+
+
+```yaml
+type: task
+name: nccl-tests
+
+nodes: 2
+
+# The `startup_order` and `stop_criteria` properties are required for `mpirun`
+startup_order: workers-first
+stop_criteria: master-done
+
+env:
+ - NCCL_DEBUG=INFO
+commands:
+ - |
+ if [ $DSTACK_NODE_RANK -eq 0 ]; then
+ mpirun \
+ --allow-run-as-root \
+ --hostfile $DSTACK_MPI_HOSTFILE \
+ -n $DSTACK_GPUS_NUM \
+ -N $DSTACK_GPUS_PER_NODE \
+ --bind-to none \
+ /opt/nccl-tests/build/all_reduce_perf -b 8 -e 8G -f 2 -g 1
+ else
+ sleep infinity
+ fi
+
+# The `kubernetes` backend requires it
+privileged: true
+
+resources:
+ gpu: nvidia:1..8
+ shm_size: 16GB
+```
+
+
+
+To run the configuration, use the [`dstack apply`](../../docs/reference/cli/dstack/apply.md) command.
+
+
+
+```shell
+$ dstack apply -f examples/clusters/nccl-tests/.dstack.yml --fleet my-k8s-fleet
+
+# BACKEND RESOURCES INSTANCE TYPE PRICE
+1 kubernetes (-) cpu=127 mem=1574GB disk=871GB H200:141GB:8 computeinstance-u00hwk32d0xemhxhvj $0
+2 kubernetes (-) cpu=127 mem=1574GB disk=871GB H200:141GB:8 computeinstance-u00n24fb4q85yavc9z $0
+
+Submit the run nccl-tests? [y/n]: y
+```
+
+
+
+### Distributed training example
+
+Below is a minimal example of a distributed training configuration:
+
+
+
+```yaml
+type: task
+name: train-distrib
+
+nodes: 2
+
+python: 3.12
+env:
+ - NCCL_DEBUG=INFO
+commands:
+ - git clone https://github.com/pytorch/examples.git pytorch-examples
+ - cd pytorch-examples/distributed/ddp-tutorial-series
+ - uv pip install -r requirements.txt
+ - |
+ torchrun \
+ --nproc-per-node=$DSTACK_GPUS_PER_NODE \
+ --node-rank=$DSTACK_NODE_RANK \
+ --nnodes=$DSTACK_NODES_NUM \
+ --master-addr=$DSTACK_MASTER_NODE_IP \
+ --master-port=12345 \
+ multinode.py 50 10
+
+resources:
+ gpu: 1..8
+ shm_size: 16GB
+```
+
+
+
+To run the configuration, use the [`dstack apply`](../../docs/reference/cli/dstack/apply.md) command.
+
+
+
+```shell
+$ dstack apply -f examples/distributed-training/torchrun/.dstack.yml --fleet my-k8s-fleet
+
+# BACKEND RESOURCES INSTANCE TYPE PRICE
+1 kubernetes (-) cpu=127 mem=1574GB disk=871GB H200:141GB:8 computeinstance-u00hwk32d0xemhxhvj $0
+2 kubernetes (-) cpu=127 mem=1574GB disk=871GB H200:141GB:8 computeinstance-u00n24fb4q85yavc9z $0
+
+Submit the run nccl-tests? [y/n]: y
+```
+
+
+
+For more examples, explore the [distirbuted training](../../examples.md#distributed-training) section in the docs.
+
+## FAQ
+
+### VM-based backends vs Kubernetes backend
+
+While the `kubernetes` backend is preferred if your team depends on the Kubernetes ecosystem,
+the [VM-based](../../docs/concepts/backends.md#vm-based) backends leverage native integration with top GPU clouds (including Nebius and others) and may be a better choice if Kubernetes isn’t required.
+
+VM-based backends also offer more granular control over cluster provisioning.
+
+> Note that `dstack` doesn’t yet support Kubernetes clusters with auto-scaling enabled (coming soon), which can be another reason to use VM-based backends.
+
+### SSH fleets vs Kubernetes backend
+
+If you’re using on-prem servers and Kubernetes isn’t a requirement, [SSH fleets](../../docs/concepts/fleets.md#ssh) may be simpler.
+They provide a lightweight and flexible alternative.
+
+### AMD GPUs
+
+Support for AMD GPUs is coming soon — our team is actively working on it right now.
+
+!!! info "What's next"
+ 1. Check [Quickstart](../../docs/quickstart.md)
+ 2. Explore [dev environments](../../docs/concepts/dev-environments.md),
+ [tasks](../../docs/concepts/tasks.md), [services](../../docs/concepts/services.md),
+ and [fleets](../../docs/concepts/fleets.md)
+ 3. Read the the [clusters](../../docs/guides/clusters.md) guide
+ 4. Join [Discord :material-arrow-top-right-thin:{ .external }](https://discord.gg/u8SmfwPpMd){:target="_blank"}