Elasticsearch 是一个兼有搜索引擎和NoSQL数据库功能的开源系统,基于Java/Lucene构建,可以用于全文搜索,结构化搜索以及近实时分析。可以说Lucene是当今最先进,最高效的全功能开源搜索引擎框架。 说明: Lucene:只是一个框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene,学习成本高,Lucene确实非常复杂。 Elasticsearch 是 面向文档型数据库,这意味着它存储的是整个对象或者 文档,它不但会存储它们,还会为他们建立索引,这样你就可以搜索他们了。
- 应用场景
- solr VS ES
- 核心概念
- 存储模型
- 分片模型
- 副本模型
- 一致性模型
- 扩展模型
- 写入查询流程
-
集群(Cluster): 包含一个或多个具有相同 cluster.name 的节点.
- 集群内节点协同工作,共享数据,并共同分担工作负荷。
- 由于节点是从属集群的,集群会自我重组来均匀地分发数据.
- cluster Name是很重要的,因为每个节点只能是群集的一部分,当该节点被设置为相同的名称时,就会自动加入群集。
- 集群中通过选举产生一个mater节点,它将负责管理集群范畴的变更,例如创建或删除索引,添加节点到集群或从集群删除节点。master 节点无需参与文档层面的变更和搜索,这意味着仅有一个 master 节点并不会因流量增长而成为瓶颈。任意一个节点都可以成为 master 节点。我们例举的集群只有一个节点,因此它会扮演 master 节点的角色。
- 作为用户,我们可以访问包括 master 节点在内的集群中的任一节点。每个节点都知道各个文档的位置,并能够将我们的请求直接转发到拥有我们想要的数据的节点。无论我们访问的是哪个节点,它都会控制从拥有数据的节点收集响应的过程,并返回给客户端最终的结果。这一切都是由 Elasticsearch 透明管理的
-
节点(node): 一个节点是一个逻辑上独立的服务,可以存储数据,并参与集群的索引和搜索功能, 一个节点也有唯一的名字,群集通过节点名称进行管理和通信.
-
索引(Index): 索引与关系型数据库实例(Database)相当。索引只是一个 逻辑命名空间,它指向一个或多个分片(shards),内部用Apache Lucene实现索引中数据的读写 文档类型(Type):相当于数据库中的table概念。每个文档在ElasticSearch中都必须设定它的类型。文档类型使得同一个索引中在存储结构不同文档时,只需要依据文档类型就可以找到对应的参数映射(Mapping)信息,方便文档的存取
-
文档(Document) :相当于数据库中的row, 是可以被索引的基本单位。例如,你可以有一个的客户文档,有一个产品文档,还有一个订单的文档。文档是以JSON格式存储的。在一个索引中,您可以存储多个的文档。请注意,虽然在一个索引中有多分文档,但这些文档的结构是一致的,并在第一次存储的时候指定, 文档属于一种 类型(type),各种各样的类型存在于一个 索引 中。你也可以通过类比传统的关系数据库得到一些大致的相似之处:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns) Elasticsearch ⇒ 索引 ⇒ 类型 ⇒ 文档 ⇒ 字段(Fields) -
Mapping: 相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以自动根据数据创建
-
分片(shard) :是 工作单元(worker unit) 底层的一员,用来分配集群中的数据,它只负责保存索引中所有数据的一小片。
- 分片是一个独立的Lucene实例,并且它自身也是一个完整的搜索引擎。
- 文档存储并且被索引在分片中,但是我们的程序并不会直接与它们通信。取而代之,它们直接与索引进行通信的
- 把分片想象成一个数据的容器。数据被存储在分片中,然后分片又被分配在集群的节点上。当你的集群扩展或者缩小时,elasticsearch 会自动的在节点之间迁移分配分片,以便集群保持均衡
- 分片分为 主分片(primary shard) 以及 从分片(replica shard) 两种。在你的索引中,每一个文档都属于一个主分片
- 从分片只是主分片的一个副本,它用于提供数据的冗余副本,在硬件故障时提供数据保护,同时服务于搜索和检索这种只读请求
- 索引中的主分片的数量在索引创建后就固定下来了,但是从分片的数量可以随时改变。
- 一个索引默认设置了5个主分片,每个主分片有一个从分片对应
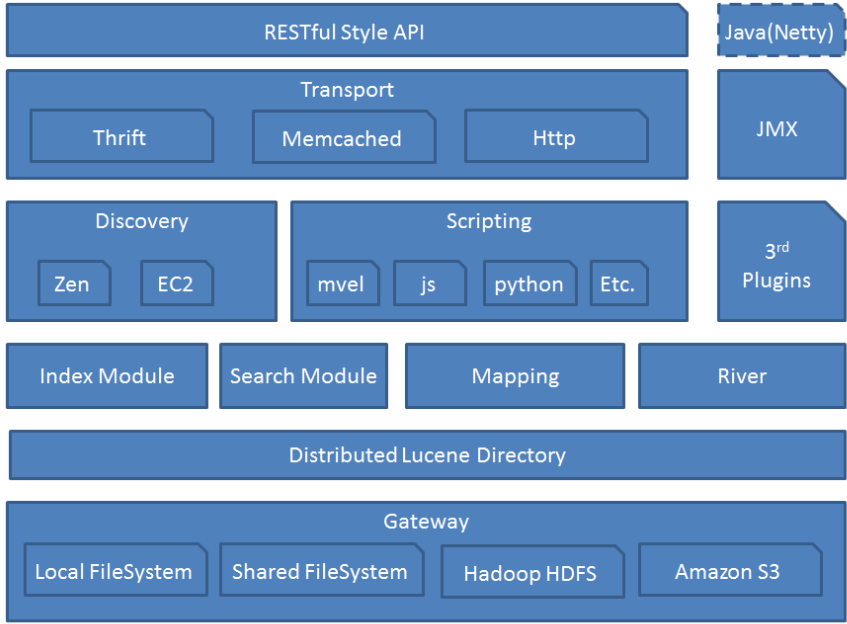
基础模块架构图如下:
<img src="https://images2015.cnblogs.com/blog/1004194/201611/1004194-20161124185700128-46209682.png" width="600px",height="400">
{kind=link}
-
Gateway: 代表ES的持久化存储方式,包含索引信息,ClusterState(集群信息),mapping,索引碎片信息,以及transaction log等
- 对于分布式集群来说,当一个或多个节点down掉了,能够保证我们的数据不能丢,最通用的解放方案就是对失败节点的数据进行复制,通过控制复制的份数可以保证集群有很高的可用性,复制这个方案的精髓主要是保证操作的时候没有单点,对一个节点的操作会同步到其他的复制节点上去。
- ES一个索引会拆分成多个碎片,每个碎片可以拥有一个或多个副本(创建索引的时候可以配置),这里有个例子,每个索引分成3个碎片,每个碎片有2个副本,如下:
$ curl -XPUT http://localhost:9200/twitter/ -d ' index : number_of_shards : 3 number_of_replicas : 2
-
每个操作会自动路由主碎片所在的节点,在上面执行操作,并且同步到其他复制节点,通过使用“non blocking IO”模式所有复制的操作都是并行执行的,也就是说如果你的节点的副本越多,你网络上的流量消耗也会越大。复制节点同样接受来自外面的读操作,意义就是你的复制节点越多,你的索引的可用性就越强,对搜索的可伸缩行就更好,能够承载更多的操作
-
第一次启动的时候,它会去持久化设备读取集群的状态信息(创建的索引,配置等)然后执行应用它们(创建索引,创建mapping映射等),每一次shard节点第一次实例化加入复制组,它都会从长持久化存储里面恢复它的状态信息
-
Lucence Directory: 是lucene的框架服务发现以及选主 ZenDiscovery: 用来实现节点自动发现,还有Master节点选取,假如Master出现故障,其它的这个节点会自动选举,产生一个新的Master
-
它是Lucene存储的一个抽象,由此派生了两个类:FSDirectory和RAMDirectory,用于控制索引文件的存储位置。使用FSDirectory类,就是存储到硬盘;使用RAMDirectory类,则是存储到内存
-
一个Directory对象是一份文件的清单。文件可能只在被创建的时候写一次。一旦文件被创建,它将只被读取或者删除。在读取的时候进行写入操作是允许的
-
-
Discovery
- 节点启动后先ping(这里的ping是 Elasticsearch 的一个RPC命令。如果 discovery.zen.ping.unicast.hosts 有设置,则ping设置中的host,否则尝试ping localhost 的几个端口, Elasticsearch 支持同一个主机启动多个节点)
- Ping的response会包含该节点的基本信息以及该节点认为的master节点
- 选举开始,先从各节点认为的master中选,规则很简单,按照id的字典序排序,取第一个
- 如果各节点都没有认为的master,则从所有节点中选择,规则同上。这里有个限制条件就是 discovery.zen.minimum_master_nodes,如果节点数达不到最小值的限制,则循环上述过程,直到节点数足够可以开始选举
- 最后选举结果是肯定能选举出一个master,如果只有一个local节点那就选出的是自己
- 如果当前节点是master,则开始等待节点数达到 minimum_master_nodes,然后提供服务, 如果当前节点不是master,则尝试加入master.
- ES支持任意数目的集群(1-N),所以不能像 Zookeeper/Etcd 那样限制节点必须是奇数,也就无法用投票的机制来选主,而是通过一个规则,只要所有的节点都遵循同样的规则,得到的信息都是对等的,选出来的主节点肯定是一致的. 但分布式系统的问题就出在信息不对等的情况,这时候很容易出现脑裂(Split-Brain)的问题,大多数解决方案就是设置一个quorum值,要求可用节点必须大于quorum(一般是超过半数节点),才能对外提供服务。而 Elasticsearch 中,这个quorum的配置就是 discovery.zen.minimum_master_nodes 。
-
memcached
- 通过memecached协议来访问ES的接口,支持二进制和文本两种协议.通过一个名为transport-memcached插件提供
- Memcached命令会被映射到REST接口,并且会被同样的REST层处理,memcached命令列表包括:get/set/delete/quit
-
River : 代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的,river这个功能将会在后面的文件中重点说到
es的数据存储模型是基于Lucene,Lucene是一个Java开源的搜索引擎,所以介绍es前,我们先介绍Lucene的大致架构和存储架构
可以从网络,存储方向进行优化,分片策略;路由优化;控制索引合并;GC;
能用filter就不用query
增加冗余字段将部分range aggregation查询变成terms aggregation
为常用字段增加配置,将fielddata的loading设成eager,尽量多加载到内存
增加集群的缓存资源,把内存尽量多的用起来
Global ordinals
Index warmer
调整aggregation的collect_mode
上SSD
Elasticsearch索引速度优化:
index.refresh_interval :-1
index.number_of_shards : X
index.number_of_replicas : 0
index.translog.sync_interval : 30s
index.translog.durability : “async”
index.translog.flush_threshold_size: 4g
index.translog.flush_threshold_ops: 50000
其它:
去掉_all字段可节省一半空间
开启索引压缩可节省空间,但会有10%-20%的性能损耗
不需分词的字符串字段设成not_analyzed