-
Notifications
You must be signed in to change notification settings - Fork 0
Project added #1
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Open
Annarrchy
wants to merge
6
commits into
main
Choose a base branch
from
Project
base: main
Could not load branches
Branch not found: {{ refName }}
Loading
Could not load tags
Nothing to show
Loading
Are you sure you want to change the base?
Some commits from the old base branch may be removed from the timeline,
and old review comments may become outdated.
Open
Changes from all commits
Commits
Show all changes
6 commits
Select commit
Hold shift + click to select a range
b1ed92f
File added
AnnaEf24 67c0ab2
Update README.md
Annarrchy 52ca949
Update README.md
Annarrchy 44a3f7e
Project fixed
AnnaEf24 a64e25b
Merge branch 'Project' of https://github.com/Annarrchy/Python-Efimova…
AnnaEf24 4df1ce3
Update README.md
Annarrchy File filter
Filter by extension
Conversations
Failed to load comments.
Loading
Jump to
Jump to file
Failed to load files.
Loading
Diff view
Diff view
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1 +1,69 @@ | ||
| # Python-Efimova-121 | ||
| # Шифровщик | ||
| Проект представляет собой программу, написанную на языке программирования Python, которая умеет шифровать и дешифровать текст разными методами. | ||
| Необходимы библиотеки: os, random, click. | ||
| При исполнении программа выводит шированный/дешифрованный текст и исходный в командную строку, а также создает файл, куда записывает результат. (Caesar_encryption.txt, Vigenere_encryption.txt, Vernam_encryption.txt) | ||
| Кроме этого при шифровании создается еще 1 файл: для шифра Цезаря - со значением сдвига шифрования, для Виженера и Вернама- со значением ключа. (Caesar_key.txt, Vigenere_key.txt, Vernam_key.txt) | ||
| ## Функционал: | ||
| + #### Шифрование шифрами: | ||
| + Цезаря | ||
| + Виженера | ||
| + Вернама | ||
| + #### Дешифрование представленных шифров | ||
| + #### Дешифрование шифра цезаря методом частотного анализа | ||
| + #### Выбор языка (русский, английский или оба) | ||
| + #### Вызов из командной строки, выбор режима с помощью ее аргументов | ||
| ## Режимы работы | ||
| У скрипта есть 7 режимов работы. Для каждого в командной строке нужно ввести 2 аргумента: | ||
| + --cipher (или -c) - режим работы программы. Один из: Caesar_cipher (или cac), Caesar_decipher (cad), Vigenere_cipher (vic), Vigenere_decipher (vid), Vernam_cipher (vec), Vernam_decipher (ved), Caesar_analysis (can). | ||
| + --input_file (или -i) - путь к исходному текстовому файлу, который нужно шифровать/дешифровать. | ||
| ##### Пример: | ||
| ``` | ||
| $ python encryption.py --cipher=Caesar_cipher --input_file=file.txt | ||
| ``` | ||
| #### Caesar_cipher/Caesar_decipher - Шифр Цезаря | ||
| При выборе потребуется ввести выбранный язык и значение сдвига: | ||
|  | ||
| #### Vigenere_cipher/Vigenere_decipher - Шифр Виженера | ||
| При выборе потребуется ввести выбранный язык и значение ключа (он должен быть на выбранном языке): | ||
|  | ||
| #### Vernam_cipher/Vernam_decipher - Шифр Вернама | ||
| Для шифровки ничего вводить не потребуется (языки шифруются одинаково, ключ создается сам случайно). | ||
| Для дешифровки потребуется также ввести путь к файлу с ключом: | ||
|  | ||
| #### Caesar_analysis - Дешифрование шифра цезаря методом частотного анализа | ||
| Ничего вводить не потребуется. | ||
| Важно помнить, что этот метод дешифрования может работать не на всех текстах (ниже описывается, почему). | ||
| Рекомендуется для примера использовать следующий: | ||
| > шерлок холмс - литературный персонаж, созданный артуром конан дойлом. его произведения, посвящённые приключениям шерлока холмса, знаменитого лондонского частного детектива, считаются классикой детективного жанра. | ||
| Также в папке проекта находится file.txt, содержащий отрывок из произведения "Война и мир", который также рекомендуется использовать для проверки. | ||
| ## Описание алгоритмов | ||
| #### Шифр Цезаря | ||
| Это тип шифра подстановочного типа, где каждая буква в открытом тексте заменяется на другую букву, смещенную на некоторое фиксированное количество (сдвиг) позиций в алфавите. | ||
| #### Шифр Виженера | ||
| Метод является усовершенствованным шифром Цезаря, где буквы смещались на определенную позицию. | ||
| Шифр Виженера состоит из последовательности нескольких шифров Цезаря с различными значениями сдвига. | ||
|
|
||
| Допустим у нас есть некий алфавит, где каждой букве соответствуют цифры: | ||
| 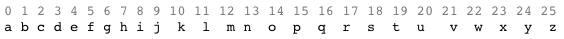 | ||
| Тогда если буквы a-z соответствуют числам 0-25, то шифрование Виженера можно записать в виде формулы: | ||
| 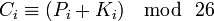 | ||
| #### Шифр Вернама | ||
| Для получения шифротекста открытый текст объединяется операцией «исключающее или» с секретным ключом. | ||
|
|
||
| Для каждого байта входного файла генерируется случайный байт, который записывается в отдельный файл-ключ. Далее вычисляется побитовое исключающее ИЛИ (XOR) для этих двух байтов и записывается в выходной файл. | ||
| Пример: | ||
|  | ||
| #### Дешифрование шифра цезаря методом частотного анализа | ||
| Частотный анализ - один из методов дешифровки, он заключается в том, что для каждой буквы алфавита, есть усредненная частота появления в тексте. | ||
| В русском языке наиболее часто встречающейся буквой, с точки зрения статистики, является буква "о", с частотой 10,983. В английском языке это буква e. | ||
| Заметим, что мы знаем усредненные частоты всех букв. | ||
|
|
||
| Обратите внимание, что частотный анализ будет прекрасно работать на шифротекстах, стостоящих из примерно десятка слов и более. Чем короче шифротекст, тем больше вероятность, что такой подход даст сбой. | ||
|
|
||
| В чем заключается суть алгоритма дешифрования: | ||
| 1. Запрашиваем исходный текст | ||
| 2. Находим средние частоты появления каждой буквы | ||
| 3. Для каждой буквы находим ближайшую к ней по частоте букву алфавита | ||
| 4. Зная местоположения в алфавите этих букв определяем сдвиг | ||
| 5. После такой обработки всех букв находим значение сдвига, которое втретчалось чаще прочих, и считаем его итоговым | ||
| 6. Расшифровываем текст, используя полученный ключ | ||
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,7 @@ | ||
| #alphabets | ||
| alphabet = 'ABCDEFGHIJKLMNOPQRSTUVWXYZАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ' | ||
| alphabet_vig = 'ABCDEFGHIJKLMNOPQRSTUVWXYZАБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ ><?.,/\|@#$!^&*()_+=-1234567890`~;:"[]{}' | ||
| alphabet_vigru = 'АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ ><?.,/\|@#$!^&*()_+=-1234567890`~;:"[]{}' | ||
| alphabet_vigeu = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ ><?.,/\|@#$!^&*()_+=-1234567890`~;:"[]{}' | ||
| alphabet_EU = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' | ||
| alphabet_RU = 'АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ' |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,71 @@ | ||
| from alphabet import * | ||
|
|
||
| rate_BOTH = [0.082, 0.015, 0.028, 0.043, 0.13, 0.022, 0.02, 0.061, 0.07, 0.0015, 0.0077, 0.04, 0.024, 0.067, 0.075, 0.019, 0.00095, 0.06, 0.063, 0.091, 0.028, 0.0098, 0.024, 0.0015, 0.02, 0.00074, 0.062, 0.014, 0.038, 0.013, 0.025, 0.072, 0.00031, 0.007, 0.016, 0.062, 0.010, 0.028, 0.035, 0.026, 0.053, 0.09, 0.023, 0.04, 0.045, 0.053, 0.021, 0.002, 0.009, 0.004, 0.012, 0.006, 0.000312, 0.016, 0.014, 0.003, 0.006, 0.018] | ||
| rate_RU = [0.062, 0.014, 0.038, 0.013, 0.025, 0.072, 0.00031, 0.007, 0.016, 0.062, 0.010, 0.028, 0.035, 0.026, 0.053, 0.09, 0.023, 0.04, 0.045, 0.053, 0.021, 0.002, 0.009, 0.004, 0.012, 0.006, 0.003, 0.000312, 0.016, 0.014, 0.003, 0.006, 0.018] | ||
| rate_EN = [0.082, 0.015, 0.028, 0.043, 0.13, 0.022, 0.02, 0.061, 0.07, 0.0015, 0.0077, 0.04, 0.024, 0.067, 0.075, 0.019, 0.00095, 0.06, 0.063, 0.091, 0.028, 0.0098, 0.024, 0.0015, 0.02, 0.00074] | ||
|
|
||
| def find_shift(text, ord_alpha, rate_al, alpha): | ||
| rate=[0 for _ in range(len(ord_alpha))] | ||
| space = 0 | ||
| enru = False | ||
| if len(ord_alpha) > len(alphabet_RU): | ||
| enru = True | ||
| for i in text: | ||
| if i == ' ': | ||
| space += 1 | ||
| elif i in alpha: | ||
| rate[ord_alpha[i]] += 1 | ||
| rate = list(map(lambda x: x / (len(text) - space), rate)) | ||
| shifts = {i : 0 for i in range(len(ord_alpha))} | ||
| for i in range(len(ord_alpha)): | ||
| diff = 1 | ||
| sdv = 0 | ||
| for p in range(len(ord_alpha)): | ||
| if diff > abs(rate[i] - rate_al[p]): | ||
| if (enru == False) or (enru and ((i < 26 and p < 26) or (i > 25 and p > 25))): | ||
| diff = abs(rate[i] - rate_al[p]) | ||
| sdv = p | ||
| if i > sdv: | ||
| sdv = i - sdv | ||
| elif i < sdv: | ||
| sdv = len(alpha) - sdv + i | ||
| shifts[sdv] += 1 | ||
|
|
||
| shift = sorted(list(shifts.keys()), key=lambda x: shifts[x])[-1] | ||
| return shift | ||
|
|
||
|
|
||
|
|
||
|
|
||
| def caesar_analysis(input_file): | ||
| lang = input('Choose language: RU/EU/BOTH: ') | ||
| with open(input_file, 'r') as f: | ||
| text = f.read().upper() | ||
|
|
||
| if lang == "BOTH": | ||
| alpha = alphabet | ||
| rate_al = rate_BOTH | ||
| if lang == "RU": | ||
| alpha=alphabet_RU | ||
| rate_al = rate_RU | ||
| if lang == "EU": | ||
| alpha=alphabet_EU | ||
| rate_al = rate_EU | ||
| ord_alpha = {} | ||
| for i in range(len(alpha)): | ||
| ord_alpha[alpha[i]] = i | ||
|
|
||
| shift = find_shift(text, ord_alpha, rate_al, alpha) | ||
| result = '' | ||
| for i in text: | ||
| place = alpha.find(i) | ||
| new_place = (place - shift) % len(alpha) | ||
| if i in alphabet: | ||
| result += alpha[new_place] | ||
| else: | ||
| result += i | ||
|
|
||
| print('Decipher:', result) | ||
| print('Input text: ', text) | ||
| res = open('Caesar_decoding.txt', 'w') | ||
| res.write(result) |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,60 @@ | ||
| from alphabet import * | ||
|
|
||
| def caesar_cipher(input_file): | ||
| lang = input('Choose language: RU/EU/BOTH: ') | ||
| with open(input_file, 'r', encoding = 'utf-8') as f: | ||
| text = f.read().upper() | ||
| #key of encryption | ||
| shift = int(input('Enter the shift value (number)): ')) | ||
| keyf = open('Caesar_key.txt', 'w') | ||
| keyf.write(str(shift)) | ||
| result = '' | ||
| alpha = '' | ||
| if lang == "BOTH": | ||
| alpha=alphabet | ||
| if lang == "RU": | ||
| alpha=alphabet_RU | ||
| if lang == "EU": | ||
| alpha=alphabet_EU | ||
|
|
||
| for i in text: | ||
| place = alpha.find(i) | ||
| new_place = (place + shift) % len(alpha) | ||
| if i in alphabet: | ||
| result += alpha[new_place] | ||
| else: | ||
| result += i | ||
|
|
||
| print('Cipher:', result) | ||
| print('Input text: ', text) | ||
| res = open('Caesar_encryption.txt', 'w') | ||
| res.write(result) | ||
|
|
||
| def caesar_decipher(input_file): | ||
| lang = input('Choose language: RU/EU/BOTH: ') | ||
| with open(input_file, 'r') as f: | ||
| text = f.read().upper() | ||
|
|
||
| shift = int(input('Enter the shift value (number)): ')) | ||
| result = '' | ||
| alpha = '' | ||
| if lang == "BOTH": | ||
| alpha=alphabet | ||
| if lang == "RU": | ||
| alpha=alphabet_RU | ||
| if lang == "EU": | ||
| alpha=alphabet_EU | ||
|
|
||
| for i in text: | ||
| place = alpha.find(i) | ||
| new_place = (place - shift) % len(alpha) | ||
| if i in alphabet: | ||
| result += alpha[new_place] | ||
| else: | ||
| result += i | ||
|
|
||
| print('Decipher:', result) | ||
| print('Input text: ', text) | ||
| res = open('Caesar_decoding.txt', 'w') | ||
| res.write(result) | ||
|
|
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,43 @@ | ||
| #!/usr/bin/env python3 | ||
| # -*- coding: utf-8 -*- | ||
|
|
||
| import os | ||
| import random | ||
| import click | ||
| import caesar_ciph | ||
| import vigenere_ciph | ||
| import vernam_ciph | ||
| import caesar_an | ||
|
|
||
| @click.command() | ||
| @click.option("--cipher", "-c", type=str, | ||
| help="Use one of: Caesar_cipher (cac), Caesar_decipher (cad), Vigenere_cipher (vic), Vigenere_decipher (vid), Vernam_cipher (vec), Vernam_decipher (ved), Caesar_analysis (can)") | ||
| @click.option("--input_file", "-i", type=click.Path(exists=True, file_okay=True), required=True, | ||
| help="Source of input file") | ||
| def main(cipher, input_file): | ||
| if cipher == 'Caesar_cipher' or cipher == 'cac': | ||
| caesar_ciph.caesar_cipher(input_file) | ||
| if cipher == 'Caesar_decipher' or cipher == 'cad': | ||
| caesar_ciph.caesar_decipher(input_file) | ||
| if cipher == 'Vigenere_cipher' or cipher == 'vic': | ||
| vigenere_ciph.vigenere_cipher(input_file) | ||
| if cipher == 'Vigenere_decipher' or cipher == 'vid': | ||
| vigenere_ciph.vigenere_decipher(input_file) | ||
| if cipher == 'Vernam_cipher' or cipher == 'vec': | ||
| vernam_ciph.vernam_cipher(input_file) | ||
| with open('Vernam_encryption.txt', 'r', encoding = 'Latin-1') as file: | ||
| print('Cipher: ', file.read()) | ||
| with open(input_file, 'r', encoding = 'utf-8') as file: | ||
| print('Input_text: ', file.read()) | ||
| if cipher == 'Vernam_decipher' or cipher == 'ved': | ||
| vernam_ciph.vernam_decipher(input_file) | ||
| with open('Vernam_decoding.txt', 'r', encoding = 'utf-8') as file: | ||
| print('Decipher: ', file.read()) | ||
| with open(input_file, 'r', encoding = 'Latin-1') as file: | ||
| print('Input_text: ', file.read()) | ||
| if cipher == 'Caesar_analysis' or cipher == 'can': | ||
| caesar_an.caesar_analysis(input_file) | ||
|
|
||
| if __name__ == "__main__": | ||
| main() | ||
|
|
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,4 @@ | ||
| Князь Василий говорил всегда лениво, как актер говорит роль старой пиесы. Анна Павловна Шерер, напротив, несмотря на свои сорок лет, была преисполнена оживления и порывов. | ||
| Быть энтузиасткой сделалось ее общественным положением, и иногда, когда ей даже того не хотелось, она, чтобы не обмануть ожиданий людей, знавших ее, делалась энтузиасткой. Сдержанная улыбка, игравшая постоянно на лице Анны Павловны, хотя и не шла к ее отжившим чертам, выражала, как у избалованных детей, постоянное сознание своего милого недостатка, от которого она не хочет, не может и не находит нужным исправляться. | ||
| В середине разговора про политические действия Анна Павловна разгорячилась. | ||
| — Ах, не говорите мне про Австрию! Я ничего не понимаю, может быть, но Австрия никогда не хотела и не хочет войны. Она предает нас. Россия одна должна быть спасительницей Европы. Наш благодетель знает свое высокое призвание и будет верен ему. Вот одно, во что я верю. Нашему доброму и чудному государю предстоит величайшая роль в мире, и он так добродетелен и хорош, что Бог не оставит его, и он исполнит свое призвание задавить гидру революции, которая теперь еще ужаснее в лице этого убийцы и злодея. Мы одни должны искупить кровь праведника. На кого нам надеяться, я вас спрашиваю.. Англия с своим коммерческим духом не поймет и не может понять всю высоту души императора Александра. Она отказалась очистить Мальту. Она хочет видеть, ищет заднюю мысль наших действий. Что они сказали Новосильцеву Ничего. Они не поняли, они не могли понять самоотвержения нашего императора, который ничего не хочет для себя и все хочет для блага мира. И что они обещали Ничего. И что обещали, и того не будет! Пруссия уже объявила, что Бонапарте непобедим и что вся Европа ничего не может против него.. |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,26 @@ | ||
| import random | ||
| from alphabet import * | ||
|
|
||
| def vernam_cipher(input_file): | ||
| with open(input_file, 'rb') as inf: | ||
| keyf = open('Vernam_key.txt', 'wb') | ||
| outf = open('Vernam_encryption.txt', 'wb') | ||
| byte_in = inf.read(1) | ||
| while byte_in: | ||
| new_key = random.randint(0, 255) | ||
| new_byte = bytes([ord(byte_in) ^ new_key]) | ||
| outf.write(new_byte) | ||
| keyf.write(bytes([new_key])) | ||
| byte_in = inf.read(1) | ||
|
|
||
| def vernam_decipher(input_file): | ||
| with open(input_file, 'rb') as inf: | ||
| key = input('Enter the key file (path)): ') | ||
| keyf = open(key, 'rb') | ||
| outf = open('Vernam_decoding.txt', 'wb') | ||
| byte_in = inf.read(1) | ||
| while byte_in: | ||
| new_key = keyf.read(1) | ||
| new_byte = bytes([ord(new_key) ^ ord(byte_in)]) | ||
| outf.write(new_byte) | ||
| byte_in = inf.read(1) |
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
отличное описание)