
Streamline Your PyTorch Experiments. Offline-First, Secure, Reproducible and Portable.
![]()


PyTorchLabFlow is a lightweight, offline-first framework designed to bring structure and sanity to your deep learning experiments. It automates project setup, manages configurations, and tracks results, all while keeping your data completely private and secure on your local machine.
⚠️ NoticeA more advanced, domain-independent version is available at: ExperQuick/PyLabFlow
If you've worked on any deep learning project, this probably sounds familiar:
- 📂 Messy Directories: A chaotic mix of notebooks, scripts, model weights, and config files with names like
model_final_v2_best.pth. - ❓ Lost Configurations: Forgetting which hyperparameters, dataset version, or code commit produced your best results.
- 📊 Difficult Comparisons: Struggling to isolate the impact of a single change (e.g., a different learning rate) when comparing dozens of similar experiment runs that share the same model or dataset.
- 💻 Portability Nightmare: Moving your project from a laptop to a powerful cloud server requires tedious and error-prone reconfiguration.
- 🔒 Privacy Concerns: Using online experiment trackers means sending potentially sensitive code and data to third-party servers.
- 🌐 Internet Dependency: Many popular tools require a constant internet connection, hindering productivity in offline environments.
PyTorchLabFlow tackles this chaos with a simple, research-first philosophy.
- Structure by Default: It enforces a clean, standardized project structure, so you always know where to find your models, datasets, configs, and results.
- Reproducibility Built-In: Every experiment is automatically saved with its unique configuration, weights, and performance history, making any result perfectly reproducible.
- Effortless Portability: The
transferfeature lets you package an entire experiment and move it to another machine with a single command. Go from local prototyping to large-scale training without friction. - 100% Offline & Private: Your work stays on your machine. Always. No data is ever sent to the cloud, ensuring complete privacy and security.
Get up and running in under 5 minutes.
pip install PyTorchLabFlowAtypical Workflow where you can do all your experiemnts/trails differ by different Component and/or parameters is some fixed number of dedicated Jupiter files. No headech of finding trials that share same code-block( here it is Componet) and analysing their performance, just use functions, PipeLine manages all these things , just focus on analysis and dicision making. refer Workflow in documentation for more details.
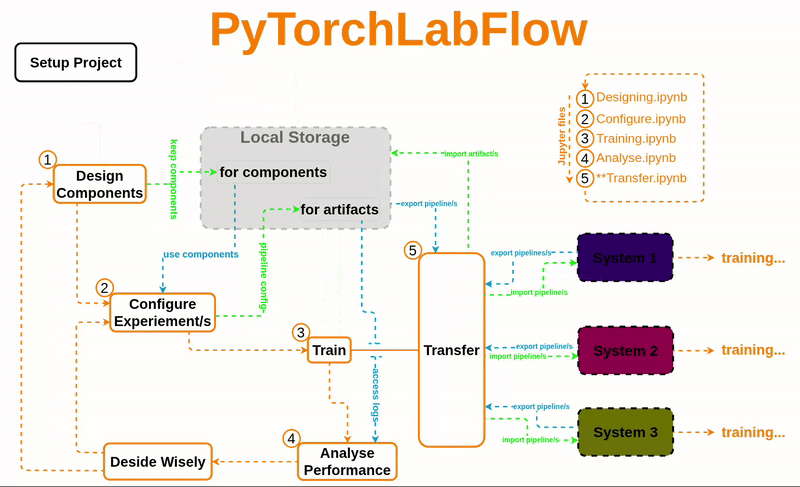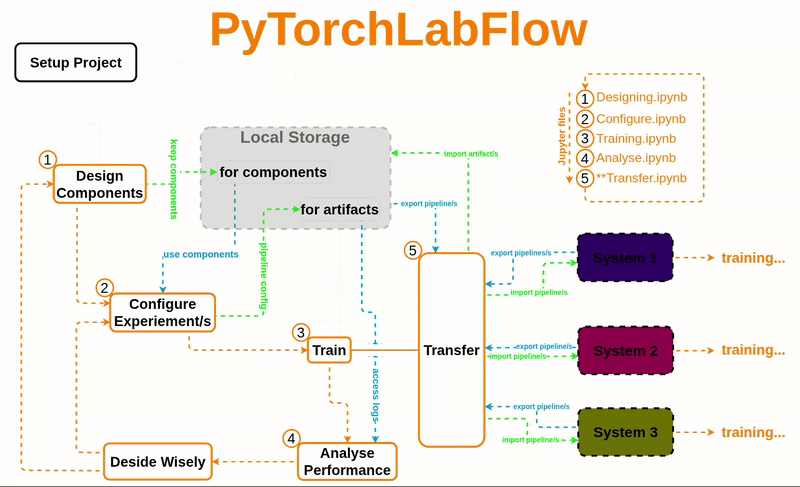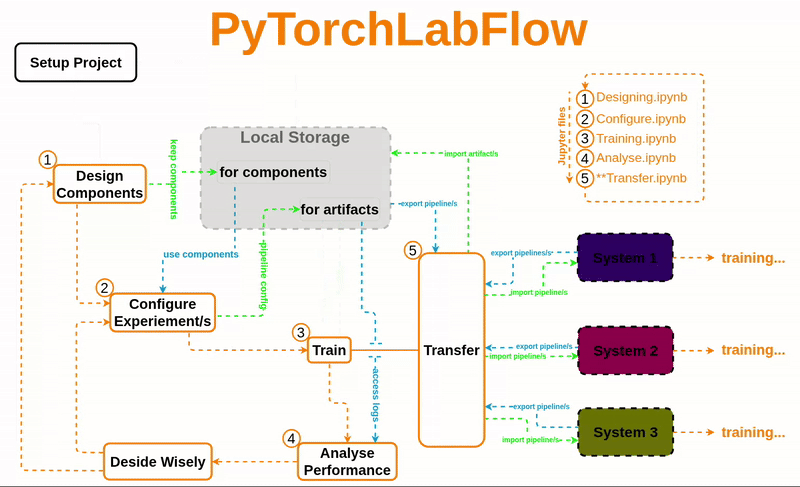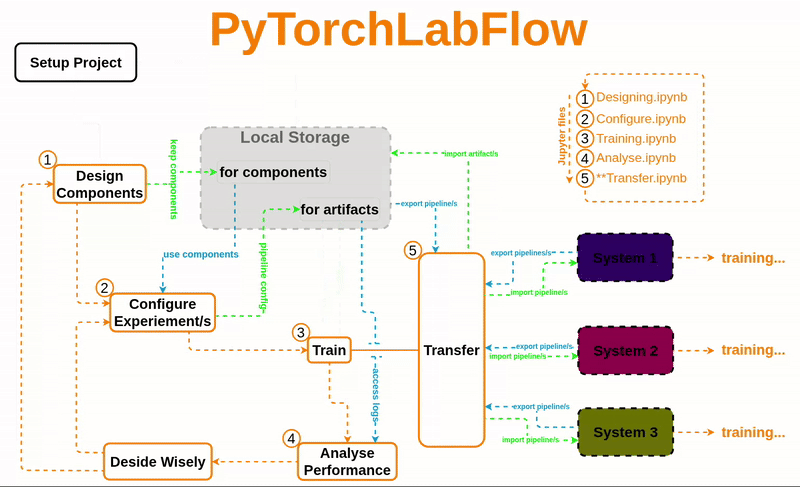
Dive deeper with our comprehensive resources.
- 📖 Official Documentation (Read the Docs): For complete API references, tutorials, and advanced guides.
- ✍️ Medium Articles (Deep Dive): Understand the "why" behind the framework.
✈️ End-to-End Example Project: See a complete, real-world application.
Contributions are the lifeblood of open source! We welcome bug reports, feature requests, and pull requests. Whether you're a seasoned developer or just starting, your help is valued.
- Fork the repository.
- Create a new branch (
git checkout -b feature/your-feature-name). - Make your changes and commit them (
git commit -m 'Add some amazing feature'). - Push to the branch (
git push origin feature/your-feature-name). - Open a Pull Request.
Please read our CONTRIBUTING.md guide for more details on our code of conduct and the process for submitting pull requests.
This project is licensed under the Apache License 2.0. See the LICENSE file for details.
If you use PyTorchLabFlow in your research, please consider citing it:
@article{Hati2025PyTorchLabFlow,
title={PyTorchLabFlow: A Local-First Framework for Reproducible Deep Learning Experiments},
author={Bibekananda Hati and Yogeshwar Singh Dadwhal},
journal={Journal of Applied Bioanalysis},
volume={11},
number={S6},
pages={538--546},
year={2025},
doi={10.53555/jab.v11si6.1940},
url={https://doi.org/10.53555/jab.v11si6.1940}
}