You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
1. 변수는 변수 명과 값이 우측 Environment 창에 출력되고, 계산 결과는 아래 콘솔창에 출력된다.
2. 결과 출력을 위해 필요한 함수는 없다. 바로 ctrl + enter 혹은 화면의 'Run' 버튼을 클릭.
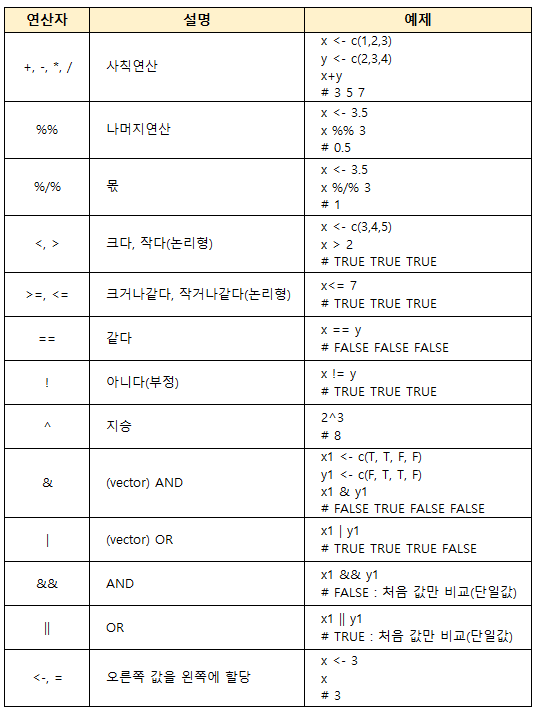
3. 대입 연산자: <-
ex) x <- 1 // x에 1을 대입
4. demo: 각종 시각적 그래프를 plots 창에서 보여준다. => 굉장히 다양한 그래프를 만들 수 있어서 "표현력이 좋다."
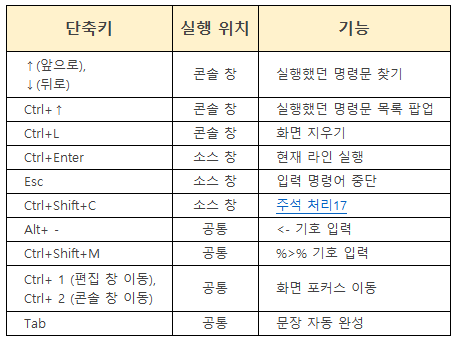
2. R Studio 단축키
3. 파일 입출력
Ⅰ. 파일 입력
1) 현재 경로 확인
• getwd()
2) 경로 설정
• setwd("폴더경로")
3) 파일 읽어오기(.txt, .csv, .xlsx, .xml, .json)
• read.table("파일명.txt")
• read.csv("파일명.csv")
• read_excel("파일명.xlsx")
• xmlToDataFrame("파일명.xml")
• fromJSON("파일명.json")
• scan() # 외부 텍스트 파일 불러와서 벡터 형식으로 저장
• readline() # 사용자 입력 데이터 저장
• readLine() # 텍스트 파일 한 줄씩 읽어 문자여 벡터로 저장
4) 파일 읽어올 때 추가 설정
• header = T /F # 원시 데이터 1행 (컬럼명) 가져올 지 결정
• skip = n # 특정 행을 제외하고 데이터 가져오기
• nrow = n # 특정 행 까지 불러오기
• sep = "" // "," // "\t" //... # 원시 데이터 구분자
• fileEncoding = 'euc-kr' # 한글 인코딩
• stringsAsFactors = F # 문자열 컬럼 팩터화
Ⅱ. 파일 출력
• write.csv("파일명.csv") # 데이터 프레임을 외부 csv파일로 저장
4. R 기초
1) 할당
• 변수명 <- 데이터
2) vector 생성
• c(value1, value2, ...)
3) 요약 확인
• summary(data명)
- min : 최소값
- 1st Qu : 1사분위 값 (하위 25%)
- median : 중위값
- mean : 평균값
- 3rd Qu. : 3사분위 값 (하위 75%)
- max : 최대값
4) 데이터 형태 파악
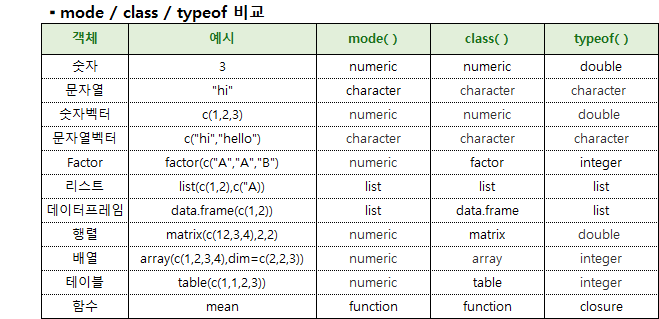
• class(data명) # 데이터의 속성만 제공
5) 객체 내부 타입 파악
• mode(data명) # 객체의 내부적 타입 제공
6) 객체 구조 파악
• str(data명) # 해당 변수의 속성과 길이, 그리고 미리보기 값 제공
7) 객체 리스트 확인
• ls()
8) 객체 삭제
• rm(객체(변수)명)
9) 문자열 합치기
• paste()
10) 도움말
• help(객체명)
• ?객체명
11) 설치된 패키지 확인
• search()
12) 패키지 설치 및 로딩
• install.packages("패키지명")
• library(패키지명)
13) 주석 처리
• #
5. 객체 타입
1) 상수(atomic)
- 정수형 integer
- 실수형 double
- 문자형 character
- 논리형 logical
- 복소수형 complex number
- 결측값 NA
- 계산불가 NaN
- 존재x NULL
- 무한대 Inf / -Inf
2) 벡터(vector)
하나 이상의 원소로 이루어진 자료.
원소의 데이터 타입이 동일해야 함.
길이가 1인 벡터가 Scalar 데이터타입.
(1) 벡터 생성
• c(val1, val2, val2, ...)
• n : m # 연속된 정수 벡터 생성(n 부터 m 까지)
(2) 함수를 이용한 벡터 생성
• rep(반복할 숫자, 반복횟수)
ex) rep(1,5) => [1] 1 1 1 1 1
• seq(시작, 끝, 간격)
ex) seq(0, 10, 2) => [1] 0 2 4 6 8 10
• seq(시작, 끝, length = n)
ex) seq(0, 10, length = 5) => [1] 0.0 2.5 5.0 7.5 10.0
• numeric / double / integer / character (length = n)
ex) character(length = 5) => [1] "" "" "" "" ""
(3) 벡터의 클래스
- numeric : 연속형
- factor : 범주형
- ordered : 순서가 있는 범주형
3) 행렬(matrix)
2차원 자료의 저장.
행(row)과 열(column)로 구성됨.
(1) 행렬 생성
• x <- matrix(원소범위, nrow = 행길이, ncol = 열길이) # nrow만 정해도 col은 자동으로 정해진다.
ex) matrix(1:10, nrow=2, ncol=5) => [,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
• y <- diag(대각선 숫자, 정방행렬크기) # 대각행렬(정방행렬 중 원소가 i=j인 곳에만 숫자를 채우고, 나머지는 0)
ex) x <- diag(1,5) => [,1] [,2] [,3] [,4] [,5]
[1,] 1 0 0 0 0
[2,] 0 1 0 0 0
[3,] 0 0 1 0 0
[4,] 0 0 0 1 0
[5,] 0 0 0 0 1
ex) diag(10), diag(1:10), diag(c(1,3,5,7,9))
(1-1) 대각원소 추출
• diag(객체명)
ex) diag(x) => [1] 1 1 1 1 1
(2) 행렬/벡터 결합
- 행 단위 결합
• rbind( x , y )
- 열 단위 결합
• cbind( x , y )
(3) 행렬 연산
- 곱
• x * y
- 전치행렬
• t(x)
- 행렬곱
• %*%
- 역행렬
• solve(x)
4) 배열(Array)
2차원 이상의 자료의 저장.
동일한 형태의 원소 데이터를 갖는다.
(1) 배열 생성
• array(원소값, dim= c(행, 열, 차원))
ex) array(data = 1:24, dim = c(3, 4, 2)) # 1~24숫자를 원소로 갖는 3X4 행렬의 2층짜리 배열 만들기
# 'data=', 'dim=' 생략 가능
(2) 배열 이름 붙이기
• dimnames = list(c(행 이름), c(열 이름), c(층 이름))
(3) 배열 요소 추출
• arr명[행인덱스, 열인덱스, 층인덱스] # 위치로 찾기
• arr명["행이름", "열이름", "층이름"] # 이름으로 찾기
(4) 배열 요소 삭제
• arr명[-행인덱스, -열인덱스, -층인덱스]
5) 리스트(list)
서로다른 객체들의 원소로 구성되는 객체.
원소는 상수/벡터/행렬/데이터프레임/함수 등 모든 객체 가능
(1) 리스트 생성
• LST <- list(colName1 = val1, colName2 = val2, colName3 = c(1,2,3), ...)
(2) 리스트 원소 접근
• 리스트명[[인덱스]]
ex) LST[[1]]
• 리스트명[['컬럼명']]
ex) LST[["name"]]
• 리스트명[[인덱스 n : 인덱스 m]]
(3) 원소 갯수
• length(리스트명)
(4) 리스트 결합
• c(list1, list2)
6) 데이터 프레임
테이블 형태의 데이터 객체
컬럼(변수) 길이는 모두 동일
컬럼들은 서로 다른 속성(vector, factor 등)을 가질 수 있음
(1) 데이터프레임 생성
• data.frame(데이터)
ex) data.frame(name = name, gender = sex, income = income)
• as.data.frame()
: 리스트나 행렬을 데이터프레임으로 변환
(2) 관련 함수
• head( )
• tail( )
• names( )
• nrow( ) # 행 데이터 차원 출력
• ncol( ) # 열 데이터 차원 출력
• dim( ) # 행, 열 데이터 차원 출력
7) 팩터(Factor)
카테고리 분류형
levels: 팩터가 갖는 값들
(1) 팩터 객체 생성
• factor(c("범주1", "범주2", ...))
ex) gender <- factor(gender, levels = c("여성", "남성"))
(2) 팩터 변수 levels 보기
• levels(객체명)
(3) 팩터 요소 추출
• 객체명[인덱스] # 벡터와 유사
(1) for
- 조건이 허락할 때 까지 반복.
- 가급적 반복함수 보다는 map(), apply()를 이용하여 벡터기반 반복작업을 추천
• for (item in vector) { 반복 실행 }
ex) for (i in 1:5) {print(i)}
(2) while
- for()함수와 유사하나 더 유연하다.
- 조건이 만족하는 한 계속 반복
• while (조건문) { 반복실행 }
ex) i <-1
while(i < 3) {
print(i)
i <- i+1
}
(3) repeat
- while보다 유연한 반복함수
- break를 만날 때 까지 반복.
• repeat{ 반복 실행 if (조건) { break } }
ex) x <- 1
repeat {
print(x)
x <- x+1
if (x == 6) {break}
}
8. 사용자 정의 함수
1) 함수 정의 방법
• 함수명 <- function(인수1, 인수2, ...) {
# 함수 계산 코드
return(반환값)
}
2) 함수 호출
• 함수명(인수1 = val1, 인수2 = val2, ...) # 인수1=, 인수2= 생략가능, 인수 차례대로 넣으면됨.
3) 함수 디버깅
• traceback() # 함수를 어떤 순서로 호출했는지만 보여줌
• debug(함수명) # 해당 함수 실행시 마다 디버깅 모드 진입. 디버깅모드에서 함수 소스가 나타남.
> (콘솔창) help # 사용할 수 있는 명령어 확인
> n # 한 줄씩 실행하면서 결과 확인
(s: 실행 함수 안으로 다시 들어감, c: 전체 소스 실행완료 후 종료, Q: 소스 실행하지 않고 바로 종료)
> undegbug(함수명) # 디버그 모드 해제
• options(error = recover) # 바로잡기 추천 옵션
> 옵션 선택 (exit: 0)
> options(error=stop) # recover 옵션 해제
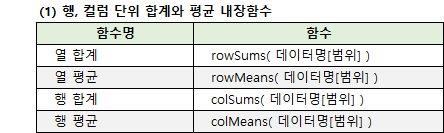
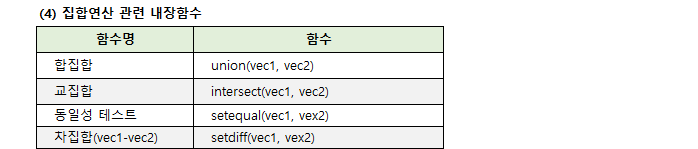
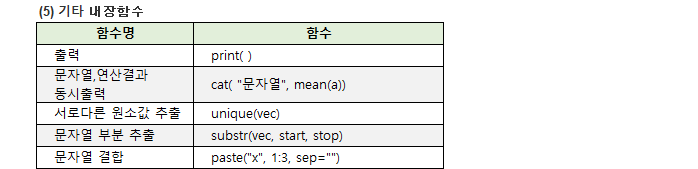
9. 내장함수
10. EDA, 패키지
1) EDA(Exploratory Data Analysis, 탐색적 데이터 분석)
raw data 의 description, dictionary 를 통해 데이터의 각 column들과 row의 의미 이해하기.
결측치 처리 및 데이터필터링.
누구나 이해하기 쉬운 시각화.
=> bias = 0. 데이터를 있는 그대로 보고 분석하자!
(1) 파일(데이터) 읽어오기
• data <- read.csv(path = '파일명.csv', header = T, sheet = 'Sheet2', fileEncoding = 'euc-kr', sep=',')
(2) 데이터를 데이터프레임에 넣기
• df <- data.frame(data)
(3) 데이터 확인
• summary( ) # 기초통계값 확인
• head( ) # df의 처음 6개값 확인
• table( ) # 빈도표 확인
• mode( ) # 데이터 내부 값의 형태
• class( ) # 데이터 전체 타입
• typeof( ) # 데이터 내부 값의 타입
• unique(df$컬럼명) # 해당 컬럼의 unique값 확인
(4) 데이터 전처리
(4-1) 필요한 열 추출
• subset()
ex) df1 <- subset(df, df$컬럼명 == '컬럼값')
• df <- df[c('컬럼명1', '컬럼명2', '컬럼명3', ...)]
ex) df2 <- df[df$구분 == "역주행", ]
• df <- df[, c('컬럼명1', '컬럼명2', '컬럼명3', ...)]
ex) df22 <- df22[, c('암종별', '성별', '발생자수')]
(4-2) 열 명 수정
• names(df) <- c('컬럼명1', '컬럼명2', '컬럼명3', ...)
ex) names(df) <- c('암종별', '성별', '연령별', '2019년', '2019년(십만명)' )
(4-3) 그룹핑
• df$컬럼명 <- ifelse( 조건1, True일때 값, False일때 값)
ex) df$불쾌지수단계 <- ifelse((df$불쾌지수>=80),'매우높음',
ifelse((df$불쾌지수>=75 & df$불쾌지수<80),'높음',
ifelse((df$불쾌지수 >= 68 & df$불쾌지수 < 75),'보통', '낮음')))
(4-4) 데이터 타입 변경
• as.type(df$컬럼명)
ex) df2$y2019 <- as.numeric(df2$y2019) # as.factor(), as.Date(), as.data.frame(data명)
(4-5) 필요한 데이터만 추출
• dplyr > filter
ex) df2 <- df %>%
filter(암종별 != "모든 암(C00-C96)") %>%
filter(연령별 == "계")
(4-6) 중복 제거
• unique(df$컬럼명)
ex) cols = unique(df$세목명)
(4-7) 결측치 제거
• na.omit( )
ex) df3 <- na.omit(df)
(4-8) 결측치 대체
• raplace(is.na(df), 0) # 전체 na를 0으로 대체
ex) df <- df %>% replace(is.na(df), 0)
• col <- names(df4)[3:6]
for(i in col) {
temp <- df[,i] # 모든 열을 돌면서 temp에 담기
temp <- ifelse(is.na(temp), 0,temp) # temp에 na값이 있으면 0, 아니면 기존 temp값.
df[,i] <- temp # 다시 temp를 df에 담기
}
(5) 시각화
• ggplot()
ex) ggplot(mapping =aes(x=연령대, y=계, fill=성별), data=df2gr) +
geom_bar(stat="identity", position=position_dodge()) +
ggtitle('연령대별 성별 분석')+
theme(plot.title = element_text(hjust = 0.5,size=20,face='bold'))
• ggvis() : 그래프를 겹쳐서 그릴 때
ex) mtcars %>% ggvis(~mpg, ~wt, fill=~cyl) %>%
layer_points() %>% layer_smooths() %>%
add_axis("x", title ="MPG", values=c(10:35)) %>%
add_axis("y", title = "WT", subdivide = 4)
2. 패키지
1) 패키지 설치
• install.packages("패키지명")
2) 패키지 실행
• library("패키지명")
3) 패키지 종류
• dplyr # 파이프라인으로 데이터 연결
• lubridate # 날짜처리
• ggplot2 # 시각화 그래프
• ggthemes # 그래프 theme 제공
• gridExtra # 여러 그림들을 하나의 plot으로 그려주는 기능
• ggvis # 그래프를 겹쳐서 그릴 때