Goal: Create a neo4j graph/database, characterizing the relationships of wikipedia articles hyperlinking to each other.
Written by: Daniel Bowder
Started on: 2018-01-15 -- 2018 Jan 15
Github: https://github.com/DotBowder
Dependencies:
- python3
- neo4j python driver
Version: 0.6
This program was designed to take the 64GB xml file, enwiki-20170820-pages-articles.xml, (see Helpful Links: Wikipedia Data Dump Torrents), find wikipedia hyperlinks on each page, and determine what wikipedia pages have links to other wikipedia pages.
The end goal of this program is to use neo4j to visualize, or just store, information pertaining to the page to page link relationships of wikipedia.
This can serve as a tool for discovering how different topics relate to each other, as characterized by wikipedia linking relationships.
Wikipedia "wikitext" parsing https://en.wikipedia.org/wiki/Help:Wikitext#Links_and_URLs
Wikipedia Data Dump Torrents https://meta.wikimedia.org/wiki/Data_dump_torrents
lxml syntax http://lxml.de/parsing.html
V0.7
- Copy TSV to "/var/lib/neo4j/import/" directory for less manual-intervention.
- Add ability to import Nodes and Relationships via CSV IMPORT in the python program. (Getting errors saying using periodic commit won't work with a python driver transaction object)
V0.5 -> 0.6
- Re-wrote neo4j connection class using the python neo4j driver.
- WIKI_LINK_NEOCONNECT.py
-
- Built framework for neo4j connection manager.
- Ran into issues trying to import CSV into neo4j. The python driver transmit object does not appear to be able to use the "USING PERIODIC COMMIT" cypher operation.
- Once the master_ids.tsv, and relationships.tsv are generated and copied to /var/lib/neo4j/import/[...].tsv, then they can be imported using the following cypher queries.
-
CREATE CONSTRAINT ON (n:Article) ASSERT n.name is UNIQUE; -
CREATE CONSTRAINT ON (n:Article) ASSERT n.id is UNIQUE; -
USING PERIODIC COMMIT -
LOAD CSV FROM 'file:///master_ids.tsv' AS line FIELDTERMINATOR '\t' -
CREATE (:Article {name: line[0], id: line[1]}) -
USING PERIODIC COMMIT -
LOAD CSV FROM 'file:///relationships.tsv' AS line FIELDTERMINATOR '\t' -
MATCH (source:Article {id: line[0] }) -
MATCH (dest:Article {id: line[1] }) -
MERGE (source)-[:LINKSTO{strength: line[2]}]->(dest)
-
-
- A CLI has been added as a front end and is largely contained in main.py. Probably could be replaced by something better, but it works.
V 0.4 -> 0.5
- Re-wrote wikipedia file extraction & organize into TSV format. Output TSV files to be imported to neo4j via Cyphertext CSV IMPORT.
- Parsing appears to work significantly better.
- WIKI_LINK_PARSE.py
-
- Reduce the size of the wikipeida datastore by extracting only the <title>page titles</title> & [[wikilinks]].
- (default output: wiki_reduced_file.tsv)
- (Duration (FX6300 @ 3.6Ghz): 2100 seconds)
-
- Combine the list of pages and links into one master list without duplicates. Assign a unique ID to each string and save to tsv.
- (default output: master_ids.tsv) Used to CREATE list of Nodes into neo4j
- (Duration (FX6300 @ 3.6Ghz): 450 seconds)
-
- Create relationship TSV file based on the id number in the master_list
- (default output: relationships.tsv) Used to MERGE list of Node Relationships into neo4j
- (Duration (FX6300 @ 3.6Ghz): 1100 seconds)

V 0.3.5 -> 0.4
- Found the parsing issue.
- The code looks for a "[[" delimiter on the page of a wikipedia article as it's the opening symbol for a link that links to another wikipedia article. ( eg: [[Closure_(computer_programming)]] ) Unfortunately, a coding article, http://wikipedia.org/wiki/Closure_(computer_programming) has a block of example code (... return [[ ^int() { ...) that throws a link detected alert, and breaks the parsing. This has been dealt with in a hack-ey way by adding an if statement (in find_links()) excluding the detection of links that include either an open curly bracket, or a close curly bracket. This will need a better solution before V 1.0.
V 0.3 -> 0.3.5
-
V0.3.5 is broken in that, there is some input parsing left to do on the memory map file mem_map, or, a quick hack may be to place a, try: except: function, in a function of the Connect class when querying neo4j for a node in order to prevent receiving a None type object.
-
Restructured code into classes, tearing away many of the low-level functions and abstracting them into classes.
-
Spent a lot of time trying to get multi-threading to work right, but, I'm letting the program remain single threaded at the moment. Hopefully the way I've re-structured the classes will facilitate threading at a later time.
-
Primary Classes:
- FileManager() # # # # # for loading, saving, or retrieving data for the nodes or wikipedia database.
- ConnectionManager() # for interacting with the neo4j server. Has queue-able transmission objects for communication.
-
Despite 0.3.5 being broken, it takes our first glimpse of the end program.
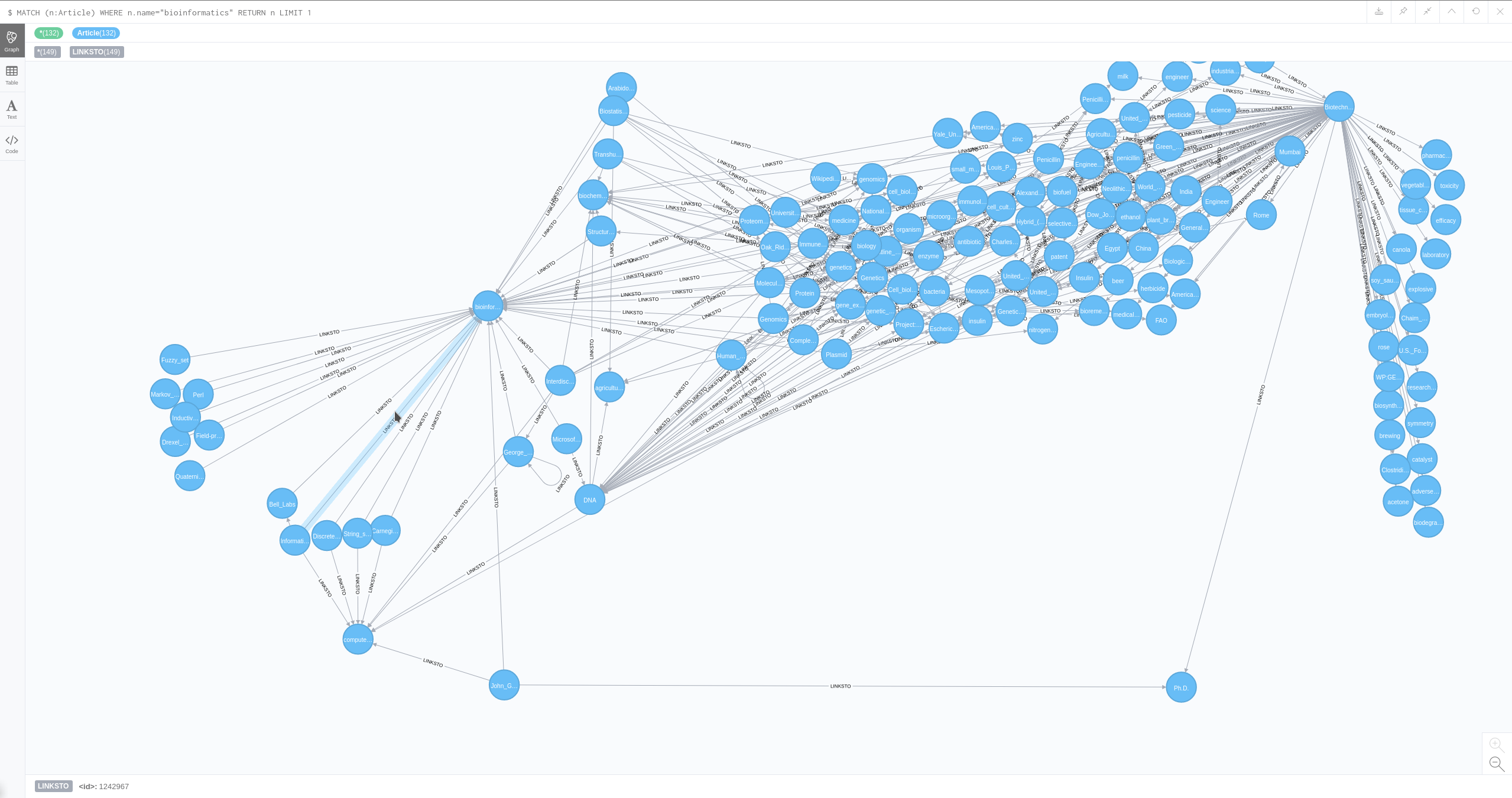
V 0.2 -> 0.3
Complete re-write from the ground up.
- Adds functionality to create nodes in neo4j in a batch manor.
- Cleans up the code and adds a user cli front-end.
Created Functions
- Data Stream Helpers
- find_tag() * Seeks through text and searches for a given tag
- get_next_page() * Uses find_tag to seek through text looking for "page", compiles whole "page" "/page" text into a block
- XML Search Helpers
- get_..._from_page_text() * Takes a "page" block of text (from wiki database) in, and returns whatever the function name implies "..."
- get_..._from_page_parser() * Takes a closed lxml parser object (containint "page" xml object from wiki database), and returns whatever the function name implies "..."
- Neo4J Helpers
- connect * Returns graph from neo4j server after connecting
- batch_create_nodes * Intakes a list of nodes in dictionary format. Queues nodes for transmission to neo4j server, and commits all nodes from dictionary in one transaction.
- DELETE_ALL * Deletes all nodes and relationships from neo4j graph.
- Disk Related Functions
- save_... * Saves file to input "file_name". Various save functions for TSV lookup files & neo4j server profiles
- load_... * Loads data from various files. Wiki Database Files, TSV lookup files, & neo4j server profiles
- delete_file * Writes over a file passed to the function.
- Main
- Handles user input and directs the user to the correct place.
V 0.1 -> 0.2 step_through_pages
- Now includes a lxml parser object and no longer requires trasversal of the whole dataset to generate a lookup table for the page numbers. The page nubmers COULD be useful, but, really isn't ideal for my purposes. process_page
- Collects Wikipedia ID, Wikipedia Title, and WikiText Links, and merges them into a list [0:WIKIPEDIA_ID,1:WIKIPEDIA_TITLE,2-INF:WIKI_LINKS] find_wikitext_links
- parses a string looking for WikiText links (charactorised by "[[" as an opener and "]]" as a closer) Returns list of links found in a given string write_wikilinks_file
- ingests masterlist (list of wikipedia ID, wikipedia Title, and wikipedia links located on article) and appents to a TSV formatted file.
V 0.0 -> 0.1 parse_page_lines
- can step through a data file and generate a lookup table file, detailing the start and end lines containing "page" "/page" xml tags. step_through_pages
- can iterate through the lookup table file, and use the start and end lines to walk back through the data file knowing right where to stop for each page. *inefficient? Yes, I'll impliment an lxml parser object and feed it the xml data later. process_page
- can look at the "page" xml object, and extract the wikipedia ID, Title, Text, and can determine if the Text of the page has a hyperlink.