Learning Intelligence from Failed ML Experiments
FailureLens IQ — Foundry IQ-Powered ML Failure Reasoning Agent
Watch the project demo here: https://youtu.be/7vMRFpLqYM8
This demo shows FailureLens IQ diagnosing an ML experiment failure caused by target leakage / future information leakage, using a multi-agent reasoning pipeline with Foundry IQ grounding, Azure AI Search citations, deployment safety gates, remediation planning, and a judge-ready proof payload.
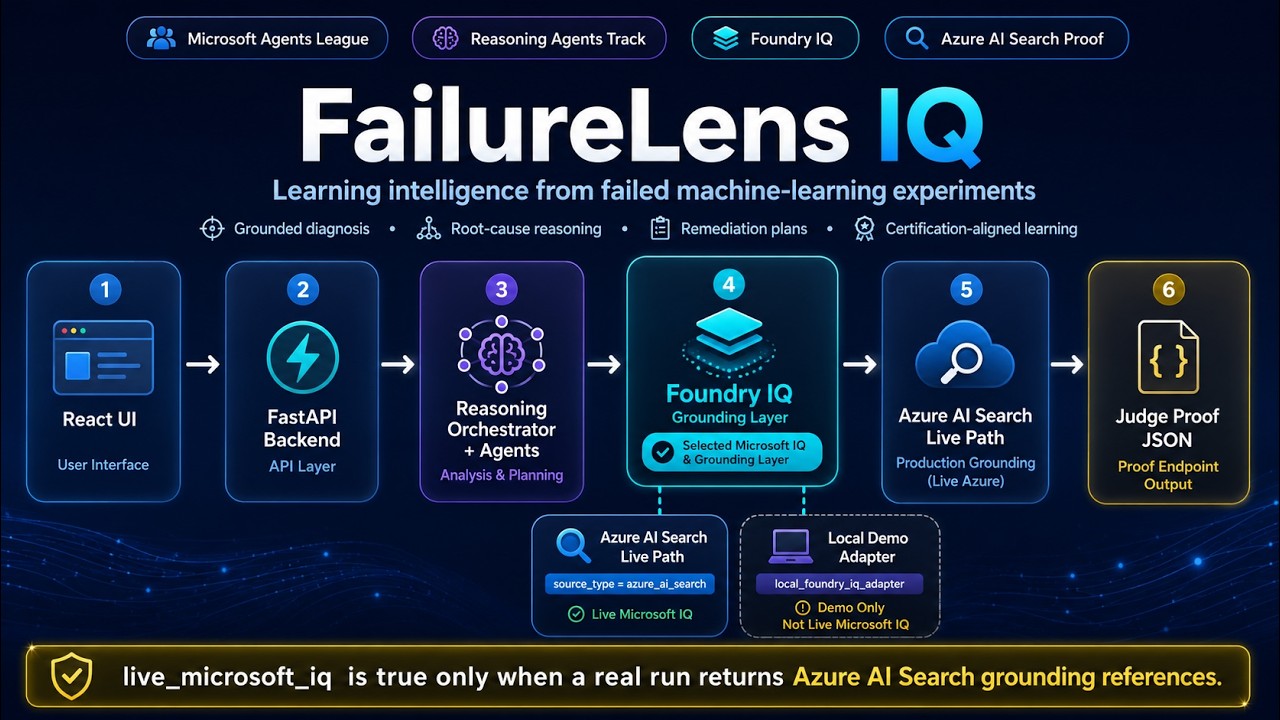
FailureLens IQ turns failed ML experiments into evidence-grounded diagnosis, remediation plans, and Microsoft certification-aligned team learning.
- Track: Reasoning Agents
- Microsoft IQ layer: Foundry IQ (grounded retrieval over Azure AI Search)
- Enterprise scenario: ML experiment failure learning and certification readiness
- ML teams repeat the same failure modes (leakage, overfitting, imbalance, drift) across experiments.
- Failed experiments are rarely converted into reusable, searchable team memory.
- Managers need evidence, uncertainty, and concrete learning actions — not a single opaque score.
- Certification / upskilling (DP-100, AI-102) should be connected to real failure cases, not generic advice.
FailureLens IQ runs a multi-agent reasoning pipeline that produces a canonical diagnosis, a remediation playbook, certification mapping, and a judge-facing proof payload — while being explicit about what is and is not live Microsoft IQ.
Selected IQ Layer: Foundry IQ.
- Grounding layer for agent reasoning (retrieval before final diagnosis).
- ML failure-taxonomy retrieval.
- Remediation playbook retrieval.
- Certification / learning-path retrieval (DP-100 / AI-102).
- Citation-backed reasoning with permission-aware source metadata.
- A judge proof payload that records exactly which sources grounded the run.
- Azure AI Search stores the Foundry IQ knowledge sources (
knowledge/foundry_iq_sources/). - The backend calls Azure AI Search before the final diagnosis.
- Returned references are attached to the reasoning trace and the canonical diagnosis.
- Live Microsoft IQ is claimed only when Azure AI Search returns citations with
source_type = azure_ai_searchand a permission filter was applied.
- Uses a local Foundry IQ-compatible adapter (
FoundryIQLocalAdapter). - Never claims live Microsoft IQ.
- Proof level:
local_foundry_iq_adapter. - The UI shows: "Local demo mode — not claiming live Microsoft IQ."
| Proof level | Grounding (Azure AI Search) | Reasoning (Microsoft model) | Live Microsoft IQ |
|---|---|---|---|
live_azure_foundry |
live citations | Microsoft Foundry/Azure OpenAI | Yes |
azure_search_live_with_local_reasoning |
live citations | local deterministic | partial (grounding only) |
foundry_model_live_without_search |
local adapter | Microsoft Foundry/Azure OpenAI | partial (reasoning only) |
local_foundry_iq_adapter |
local adapter | local deterministic | No (honest local demo) |
All proof routes return honest, run-specific status and never fabricate live claims.
| Route | Purpose |
|---|---|
GET /health |
Service + configuration health. |
GET /version |
Build version, app mode, active reasoning/grounding providers. |
GET /iq/status |
Current IQ layer/provider and proof level. |
GET /proof/live-iq |
Configuration-only proof snapshot (booleans + honest limitation). |
POST /proof/live-iq/run |
Runs the pipeline and returns the actual proof payload for that run. |
GET /proof/azure-search/test |
Direct Azure AI Search diagnostic (configured / request_success / result_count). |
Each proof payload includes: selected_iq_layer, proof_level, live_microsoft_iq_grounding,
live_microsoft_reasoning, azure_ai_search_configured, azure_ai_search_used_this_run,
foundry_or_azure_model_configured, foundry_or_azure_model_used_this_run,
active_reasoning_provider, active_grounding_provider, citation/grounding_refs counts,
permission scope (via citations), warnings, honest_limitation, run_id, and trace_ids.
Proof-level meanings
live_azure_foundry— both halves of live Microsoft IQ proven (search + Microsoft model).azure_search_live_with_local_reasoning— grounding is live; reasoning is local.foundry_model_live_without_search— reasoning is live; grounding is local.local_foundry_iq_adapter— fully local demo; live Microsoft IQ is honestlyfalse.
flowchart LR
UI["React / Vite Frontend"] --> API["FastAPI Backend"]
API --> ORCH["Reasoning Orchestrator"]
ORCH --> AGENTS["Reasoning Agents"]
AGENTS --> IQ["Foundry IQ Grounding Layer"]
IQ --> SEARCH["Azure AI Search"]
IQ --> LOCAL["Local Foundry IQ Adapter"]
AGENTS --> MODEL["Azure OpenAI / Foundry Model"]
ORCH --> PROOF["Judge Proof Payload"]
The FinalConsistencyValidatorAgent + build_final_report_payload produce one canonical
payload that drives the UI, the HTML/JSON export, and the proof — so judge-facing surfaces
cannot disagree (a single payload hash covers all of them).
| Agent | Role | Input | Output | Uses Foundry IQ citations | Uncertainty |
|---|---|---|---|---|---|
| ExperimentIntakeAgent | Normalize the experiment record, flag missing fields | raw prompt / experiment log | structured ExperimentLog, missing-field list |
no | missing-critical-fields list |
| FailureClassifierAgent | Rule-based taxonomy scoring | experiment metrics/notes | candidate category + conflicts + confidence | no | conflict list, requires_review flag |
| RootCauseAnalyzerAgent | LLM/grounded root-cause reasoning | classification + grounding | root cause, evidence, counter-evidence, reflections | yes | counter-evidence + reflection notes |
| ExperimentHistorianAgent | Find comparable past failures | diagnosis + history | recurrence signals | yes | similarity confidence |
| CertificationEvaluatorAgent | Map failure → Microsoft cert | category + gap | DP-100 / AI-102 path | yes | fallback flag when grounding weak |
| ReadinessAssessmentAgent | Build readiness questions | canonical diagnosis | targeted practice questions | yes | — |
| PrescriptiveCoachAgent | 3-day / 7-day remediation | canonical diagnosis | remediation playbook + lab | yes | — |
| IntegrationManagerAgent | Team heatmap + governance | team history | heatmap, cert relevance, recurring alerts | no | vulnerability level |
| FinalConsistencyValidatorAgent | Single source of truth | all agent outputs | canonical diagnosis + consistency gate | reconciles citations | contradictions list, fails on disagreement |
Reasoning is exposed only as structured summaries (evidence, counter-evidence, reflections, calibrated confidence). No hidden chain-of-thought is surfaced.
Prompt:
"Validation accuracy jumped to 98% after adding
renewal_status_after_30d. Test performance collapsed, and I suspect the feature contains future target information."
Expected output:
| Field | Value |
|---|---|
| Primary category | Data Leakage |
| Subtype | Target Leakage / Future Information Leakage |
| Deployment gate | BLOCKED_PENDING_HUMAN_REVIEW |
| Report Judge-ready | Yes (when proof + citations + parity + consistency pass) |
| Model Deployment-ready | No |
| Human review required | Yes |
leakage_audit_recommended |
true |
active_leakage_signal |
true |
| Responsible AI status | NOT_EVALUATED (no fairness data provided) |
| Certification path | DP-100 |
Report Judge-ready ≠ Model Deployment-ready. A complete, grounded report can correctly conclude the model must not ship.
The reverse case is also enforced: an Overfitting prompt (high train / low validation accuracy) is not flipped to Data Leakage just because the reasoning narrative mentions leakage — leakage stays a secondary, audit-recommended risk unless concrete leakage evidence (leakage columns / explicit future-state features) exists.
# 1) Backend virtual environment
python -m venv .venv
.\.venv\Scripts\Activate.ps1
pip install -r requirements.txt
# 2) Frontend packages
npm install --prefix frontend
# 3) Run backend only (http://127.0.0.1:8000)
python -m uvicorn backend.api.main:app --reload --host 127.0.0.1 --port 8000
# 4) Run frontend only (http://127.0.0.1:5173)
npm run dev:frontend --prefix frontend
# 5) Run BOTH together
npm run dev # from repo root (scripts/dev_full_stack.py)Root package.json scripts:
| Script | Action |
|---|---|
npm run dev |
Start backend + frontend together |
npm run dev:backend |
Backend (uvicorn) only |
npm run dev:frontend |
Frontend (Vite) only |
npm run install:all |
Install frontend packages + backend requirements |
npm run test:backend |
pytest tests -v |
npm run test:frontend |
Frontend Vitest suite |
Copy .env.example → .env (the repo .gitignore excludes .env; no real secrets are committed).
| Variable | Required for live | Notes |
|---|---|---|
APP_MODE |
yes | demo (local) or live/production. |
FOUNDRY_CALL_MODE |
— | Keep mock off in live mode. |
REQUIRE_LIVE_FOUNDRY_IQ |
optional | Fail-closed: forbid local fallback in live. |
AZURE_AI_SEARCH_ENDPOINT |
yes (live) | Azure AI Search endpoint (alias: AZURE_SEARCH_ENDPOINT). |
AZURE_AI_SEARCH_INDEX |
yes (live) | Index holding Foundry IQ sources. |
AZURE_AI_SEARCH_KEY |
yes (live) | Search admin/query key. |
AZURE_OPENAI_ENDPOINT / FOUNDRY_OPENAI_BASE_URL |
yes (live) | Microsoft model endpoint. |
AZURE_OPENAI_API_KEY / FOUNDRY_API_KEY |
yes (live) | Model key. |
AZURE_OPENAI_DEPLOYMENT / FOUNDRY_MODEL_DEPLOYMENT |
yes (live) | Deployment name. |
MODEL_PROVIDER |
— | foundry_openai / azure_openai / openai / local. |
Local demo mode needs none of the Azure values — it runs fully offline with the local Foundry IQ adapter and reports local_foundry_iq_adapter.
# Backend (pytest)
python -m pytest tests -q
# Byte-compile sanity
python -m compileall backend
# Frontend
npm run lint --prefix frontend # tsc --noEmit
npm run test --prefix frontend # Vitest
npm run build --prefix frontend # production buildCoverage highlights:
- Leakage scenario contract (category, gate, leakage audit, DP-100, RAI status).
- No DP-203 for leakage learning paths.
- Citation consistency across UI / proof / export / grounding refs / agent trace.
- Live IQ honesty — local adapter never claims live Microsoft IQ;
azure_ai_searchcitations required. - Report vs Deployment readiness are separate fields.
- UI / export parity — single canonical payload hash.
- Confidence calibration — one documented formula object.
- Open the app (
npm run dev). - Check
GET /iq/statusandGET /proof/live-iq(honest mode + proof level). - Run the leakage prompt from §8.
- Show the diagnosis and the blocked deployment gate (Report Judge-ready Yes / Model Deployment-ready No).
- Show the Foundry IQ citations (with
source_type+permission_scope). - Show the proof payload (
POST /proof/live-iq/runor the report's Proof section). - Export the report (HTML / JSON).
- Show report / UI parity (same payload hash, same readiness labels).
- docs/MICROSOFT_IQ_HONEST_COMPLIANCE.md — how live-vs-local Microsoft IQ claims are kept honest.
- docs/PRODUCTION_HARDENING.md — production hardening checklist.
- docs/SECURITY_MODEL.md — auth, CORS, rate limiting, and secret handling.
- docs/AZURE_POLICY_BLOCKER.md — documented Azure tenant policy blocker.
- docs/OPENAI_FALLBACK_PROVIDER.md — the OpenAI direct API does not replace Microsoft IQ; it is only a reasoning fallback when Microsoft endpoints are unavailable, and never counts as live Microsoft IQ.
- docs/JUDGE_REVIEW_GUIDE.md — judge walkthrough.
- docs/NO_SECRETS_POLICY.md — no secrets are committed;
.envis gitignored.
- Local mode is not live Microsoft IQ. It is clearly labeled
local_foundry_iq_adapter. - Live Microsoft IQ is only claimed when Azure AI Search returns
source_type = azure_ai_searchcitations and the permission filter is applied. - FailureLens IQ provides decision support, not automatic production approval. Every failure diagnosis blocks deployment pending review.
- Human review is required for leakage and low-confidence diagnoses.
- Responsible AI is reported as
NOT_EVALUATEDunless fairness / protected-attribute data and metrics are provided. - Agent reasoning is shown as structured summaries; no hidden chain-of-thought is exposed.