You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Analyzed, Cleaned and Visualised dataset of different patients.
Built a ML-Model using Python and Machine Learning that predicts whether a person is diabetic or not
Confusion Matrix
A Confusion matrix is an N x N matrix used for evaluating the performance of a classification model, where N is the number of target classes.
The matrix compares the actual target values with those predicted by the machine learning model.
Decision Tree
Decision Tree is a Supervised learning technique that can be used for both classification and Regression problems, but mostly it is preferred for solving Classification problems.
It is a tree-structured classifier, where internal nodes represent the features of a dataset, branches represent the decision rules and each leaf node represents the outcome.
Accuracy Using Decision Tree
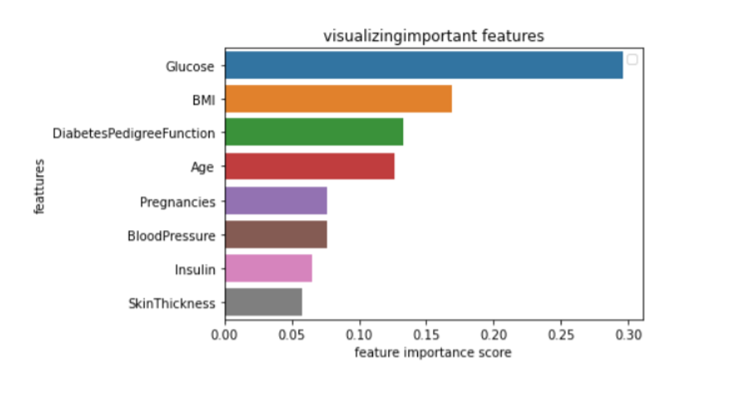
Feature Importance Score
Feature importance refers to techniques that assign a score to input features based on how useful they are at predicting a target variable.
Accuracy Using Random Forest Classification
Error Rate Vs K Rate
The optimal value of k reduces effect of the noise on the classification, but makes boundaries between classes less distinc.
Elbow method helps data scientists to select the optimal number of clusters for KNN clustering.
Accuracy Using K-Nearest Neighbors(KNN)
Clustering (No. of Clusters)
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups.
It is basically a collection of objects on the basis of similarity and dissimilarity between them.
K-Means ( Cluster)
K-Means Clustering is an Unsupervised Learning algorithm, which groups the unlabeled dataset into different clusters.
Here K defines the number of pre-defined clusters that need to be created in the process, as if K=2, there will be two clusters, and for K=3, there will be three clusters, and so o
Accuracy Using Naive Bayes Algorithm
Accuracy Using Support Vector Machine (Linear Kernel)
Accuracy Using Support Vector Machine (Poly Kernel)
Accuracy Using Support Vector Machine (Gaussian Kernel)
Accuracy Using Support Vector Machine (Sigmoid Kernel)
Accuracy Using Artificial Neural Network (ANN)
About
Analyzed, Cleaned and Visualised dataset of different patients. Built a ML-Model using Python and Machine Learning that predicts whether a person is diabetic or not