Prilikom pokretanja programa, korisnik bira direktorijum u kojem ce dalje vrsiti pretrazivanje, odnosno, korisnik vrsi pozicioniranje na zeljeni direktorijum. Nakon toga se pune strukture podataka stablo, graf, set na osnovu kojih ce se dalje vrsiti pretraga. Aplikacija je zasnovana na tome da korisnik na osnovu izabranog direktorijuma za pretrazivanje, moze da bira kljucne reci koje trazi i da na osnovu toga dobije rangirane fajlove sa svojim putanjama koje zadovoljavaju zeljenu pretragu.
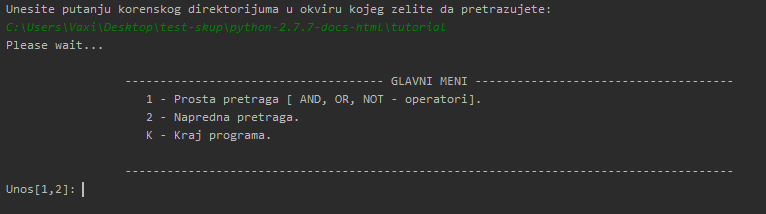
Kretanje kroz program je podeljeno u glavni meni i meni(jedna grana glavnog menija). U glavom meniju se vrsi izbor kompleksnosti pretrage, odnosno da li korisnik zeli da koristi logicke operatore 'AND', 'OR', 'NOT' ili zeli da koristi kompleksniju pretragu sa mogucnoscu vise recnog pretrazivanja uz pomoc operatora '||' - or, '&&' - and, '!' - not .
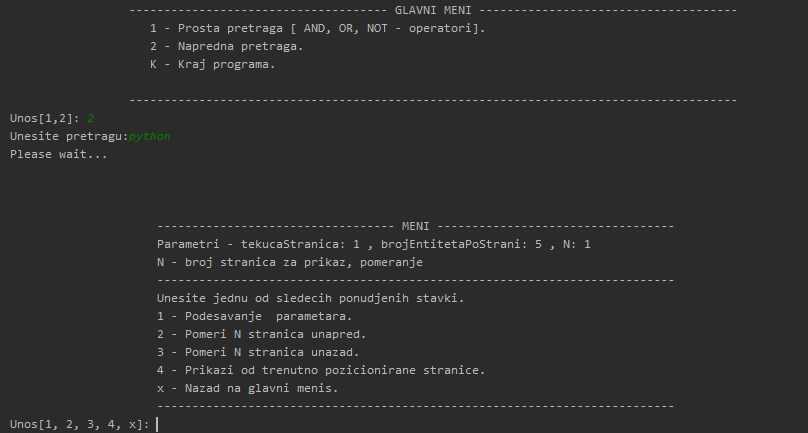
Nakon izbora pretrage, unosi se pretraga, odnosno vrsimo trazenje zeljenih reci u .html fajlovima . U meniju nakon zeljene pretrage imamo mogucnost podesavanja parametara prikaza zeljene pretrage ili jednostavnim izborom stavke 4 biramo prikaz po default parametrima.
Trenutna verzija ne zahteva nikakvo dodatno instaliranje vise od jedne biblioteke, stoga sve sto je potrebno je instalacija biblioteke parglare i program se dalje pokrece preko pokretanja modula 'pokretac.py'
$ pip install parglareU buducim verzijama, a i sada po vasem izboru mozete uz pozivanja requiments.txt fajla instalirati sve potrebne zavisnosti, odnosno:
$ pip install -r requirements.txt$ git clone https://github.com/Pufke/OISISI-drugi-projektni-zadatak.git
Potrebno je da se pozicionirate u okvir direktorijum vas_path/SearchEngine/ koji ste prethodno skinuli/klonovali. A potom na sledeci nacin mozete pokrenuti aplikaciju:
$ python pokretac.py- Graficko korisnicki interfejs, u kome se interakcija sa korisnikom vrsi preko GUI-a
- ...
- Trie ~ struktura koja cuva parsirane reci iz svih fajlova unetog direktorijuma i na kraju reci( u listu stabla) cuva i stranice koje imaju tu rec. ( vise o stablu)
- Graph ~ struktura u kojoj se cuvaju veze izmedju stranica, odnosno koja stranica pokazuje na koju stranicu, i na koju stranicu pokazuju koje stranice, kako bi posle mogli vrsiti delotvornije rangiranje. ( vise o grafu)
- Set ~ struktura podataka u kojem se cuvamo stranice odredjene reci, a kasnije koristimo kako bi vrsili uniju, presek, komplement nad setom pretrazivane reci. ( vise o setu)
Osnovna pretraga se vrsi tako sto u zavisnosti od unetog logickog operatora vrsimo odredjene operacije nad setovima unetih reci. Odnosno, uneti string je dekomponovan na vise reci, i za svaku rec imamo set odnosno skup stranica u kojem se ta rec pojavljuje, nakon toga vrsimo operacije nad setovima ( unija, presek, komplement ) i dobijamo rezultujuci set stranica koje predstavljaju rezultat pretrage.
Kao i osnovna pretraga, samo sto sada koristimo biblioteku parglare . Potrebno je bilo napraviti IR (intermediate representation) u obliku Python klasa. Gde su prilikom redukcije, parglare akcije zadužene za instanciranje klasa IR-a i izgradnju stabla parsiranja. A nakon toga se vrsi evaluiranje stabla parsiranja.
Primeri na osnovu koga funkcionise nasa kompleksna pretraga : primer kalkulatora i po ugledu na gramatiku za +,-,*,/
E -> E + T | E - T | T
T -> T * F | T / F | F
F -> F ^ X | B
B -> i | (E)
X -> i | (E)Pravimo nasu gramatiku:
E: E "||" T
| T
;
T : T "&&" F
| F
;
F : "!" X
| X
;
X: reci
| "(" E ")"
;Rangiranje rezultata pretrage se vrši tako što imamo više faktora koji utiču na rang, najbitnije stavke su:
- broj linkova iz drugih stranica na pronađenu stranicu
- broj pojavljivanja traženih reči na stranici
- broj traženih reči u stranicama koje sadrže link na traženu stranicu
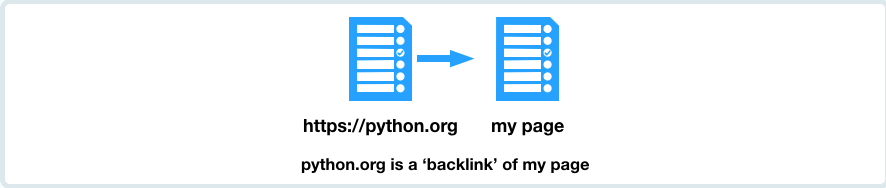
Težine ovih faktora su skalirane, tj. broj traženih reči na stranici nema isti uticaj na rangiranje kao broj linkova iz drugih stranica na pronađenu stranicu. Konkretno najveci uticaj na rangiranje imaju "beklinkovi" tj broj linkova iz drugih stranica na pronađenu stranicu.
Formula po kojoj se odredjuje broj bodova za rangiranje izgleda ovako: rang = (beklinkovi * 1) + (brojPojavljivanjaTrazenihReciNaTojStranici * 0.7) + (brojponavljanjatrazenihReciNaStranicamaKojeLinkuju * 0.4)
Iz formule jasno vidimo da najveci uticaj na rang imaju beklinkovi, zatim broj pojavljivanja traženih reči na stranici i na kraju najmanji uticaj ima broj traženih reči u stranicama koje sadrže link na traženu stranicu, baš iz tog razloga imamo mnozenje tj skaliranje tog faktora sa 0.4. Na osnovu izracunatuh bodova tj ranga svake stranice vršimo paginaciju rezultata, osim putanja stranica prikazujemo korisniku i bodove rangiranja.(otvori sliku za bolji pregled)
