Clone the repo and get going. No build steps or anything needed, just a python install.
The voynich root folder contains the various scripts for analysis. It also containes two sub-folders: /texts/ and /figures/. All text outputs are saved in /texts/, all figure outputs are saved to /figures/. It is reccomended that input txt files are also stored in /texts/. Furthermore, test text files have also been stored in this folder.
The purpose of this formatter is to take transliterated text of the Voynich Manuscript and convert it into a form that is needed for particular analyses.
The formatter takes a single required argument and many optional arguments.
The path to the plaintext file containing the transliterated Voynich Manuscript, written in EVA (Extensible Voynich Alphabet and formatted in IVTFF.
A number of optional arguments can be passed through the command line to toggle certain text features from being formatted.
--keepcomments: Comments made by the transcriber in the text file are retained.--locusraw: Locus indicators are retained in raw form. i.e.<f...>. Further details about locus indicators can be found below.--locusproc: Locus indicators are retained but processed into meaningful English. i.e.<f17r>would become "Beginning of folio 17, right side" in the output text.--nospace:.characters are not converted into whitespace in the output text.--nouncertainspace:,characters are not converted into whitespace in the output text.--keepuncertain: Uncertain characters are retained in their "list" form. I.e.[x:y:z].--pararaw: Paragraph identifiers (%at the start and$at the end) are kept in raw form.--paraproc: Paragraph identifiers are processed into meaningful English. "New Paragraph" or "End Paragraph" respectively.--noillegible: No illegible words. Not only are?and???character sequences removed, if they occur within a word (delimited by.characters), the entire word is removed aswell.--keepillegible: Illegible characters and their containing words are retained in the output text.
The output of the formatter is a single text file of formatted ASCII. The file will be located in /texts/ and will be named the same as the input file with _formatted.txt appended.
If passed no command line arguments, the formatter will produce an output file in the following default format.
- Comments removed.
- Locus indicators removed.
.characters converted to whitespace.- Uncertain spaces (
,characters) converted to whitespace. - Uncertain character readings, found in the transcription in form
[x:y:z]replaced with the first character in the option sequence. This character is the one that the transliteration producer deemed most likely. - ASCII codes are retained for rare characters. 3.g.
@185. -characters are removed- Paragraph identifiers are removed and replaced with double newlines to format text into actual paragraphs.
- Illegible character identifiers
?and???are removed.
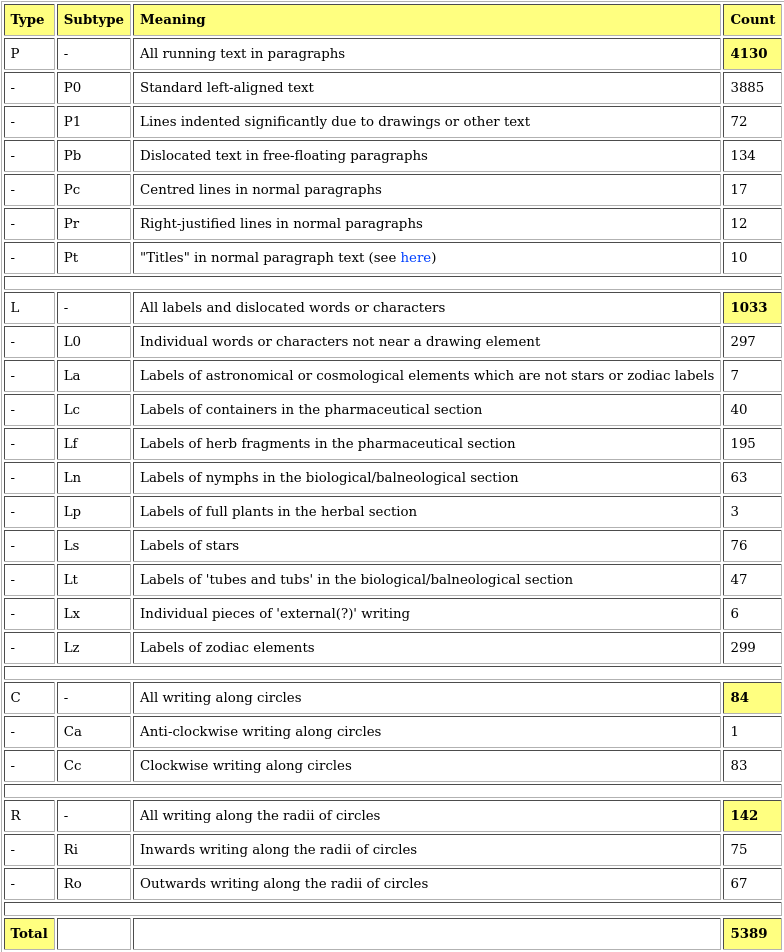
Locus indicators provide a lot of meta information about the manuscript's text. There are three forms of locus indicators.
<f17r>: Indicates the beginning of a new page, in this case, folio 17, right side. Following will be meta comments about the contents of page.<f17r.N@Ab>:Nis the current count of this locus as an identified unique section of text on the current page.@Abis a code which gives some more insight into the grouping of text section types that this locus is a part of (See below).<f17r.N@Ab;T>:Tidentifies the transcriber of this particular locus.
The frequency anaysler (frequencyAnalyser.py) takes a text, producing a frequency analysis and providing other key details such as the longest word in the text, the word count, etc.
The frequency analyser takes a single required argument: the path to the text file to be analysed. The --voynich option can be passed as an optional argument, and is required when a frequency analysis of the Voynich Manuscript is to be performed. This will ensure that ligatures and special characters are treated as single characters rather than the string of ASCII characters they appear as in the transliteration.
The frequency analyser produces a text output, aswell as a figure.
The text output will be saved to /texts/ and will be named the same as the input file with _frequency_analysis.txt appended. Within this file can be found a summary of the interesting characteristics of the text:
- Number of words
- Number of unique characters
- Longest word and its length
- Average word length
In addition, the text output contains the frequency counts for each unique character appearing in the text.
The figure output will be saved to /figures/ and will be named the same as the input file with _freq_analysis.png appended. This figure is a bar chart of the frequency of each unique character in the text.
In the case of texts with a large number of unique characters, or the Voynich Manscript where ligatures are long strings of ASCII characters, it may occur that the figure does not fit all unique characters on the x-axis. It is likely possible to tweak the figure size to fix this issue, but it has not been confirmed.
The anagram analyser (anagrammer.py) takes a text, producing data on the tendancy for words and characters in the text to form anagrams.
The anagram analyser takes a single required argument: the path to the text to be analysed. The optional --voynich argument should be specified when analysing transliterations of the Voynich Manuscript so that characters are handled correctly, as in the frequency analyser.
The anagram analyser produces a text output, aswell as a figure.
The text output will be saved to /texts/ and will be named the same as the input file with _anagrams.txt appended. Within this file can be found a summary of words and characters that form anagrams in the text.
Words are shown with the number of anagrams they form, and what those anagrams are.
Characters are shown with the percentage of their appearances that appear in words which form anagrams.
The figure output will be saved to /figures/ and will be named the same as the input file with _anagram_plot.png appended. This figure is a bar chart showing each unique character in the text and their percentage of appearances in words that form anagrams.
This program trains a hidden Markov model to predict numbers and words in the Voynich Manuscript based on the status of strings in training tests.
To use this, place all the texts you want to train on in training_texts and specify the path to the Voynich Manuscript in the script variable labelled VM. By default results will be sent to HMM_outputs. The names of these directories can be changed at the user's leisure but they must be consistent with changes in the script(s).
This script can be used to calculate the entropy of words and numbers in a given text. This will generate a threshold for distinguishing the two categories which can then be applied to the Voynich Manuscript to produce predictions for strings falling into these two categories.
This Script is written to run on one text at a time (an inefficiency).
Set 'VM' in the script to 'False'.
The script calculates the entropy of the individual characters in a text and then uses this to calculate the entropy of each string (normalised and non-normalised on string length). Following this, it finds the average entropy for numbers and words in that text. Only unique characters are considered for the average calculation.
Outputs are sent to the entropy folder.
By setting the 'VM' variable to 'True' in the script and enerting the entropy thresholds calculated in the previous step, the script will extract strings in the Voynich Manuscript and categorise them according to these thresholds.
HMMTest.py is simply a scipt used to demonstrate that the HMM functions work.
The WRI analyser produces a plot of the Word Recurrence Interval for a number of texts. Word_RI.py plots the results of a single test, WRI_3.py can handle 3 texts, WRI_4.py can handle 4 and WRI_All.py can handle 5.
The directory for where these texts are stored needs to be specified in the script.
Names of plots can be changed at the user's leisure.
Outputs are sent to the WRI_figures directory.
WRI folder just consists of the output of test scripts.
This codebase contains a corpus of texts in a number of different languages covering various topics. These texts are stored in plaintext files and are used in conjunction with the various analysis scripts to help draw patterns with the VM. Below is a list of the texts included and their important features.
- UN Declaration of Human Rights [Chosen for its availability in many languages; Human Rights]
- English
- Spanish
- French
- German
- Italian
- Species Plantarum Sections I-III [Latin; Botanical]
- Nova Analysis Aquarum Medeviensium [Latin; Chemistry]
- Ephemerides Barometricae Mutinenses (anni M.DC.XCIV) [Latin; Weather Patterns]
- De Canibus Britannicis[Latin; Animals/Agriculture]
- Of English Dogges [English; Animals/Agriculture; Translated from Canibus Britannicis]
- The Medicinal Plants of the Philippines [English; Botanical]
- The Works of Edgar Allen Poe (Volume II) [English; Narrative Fiction]
- A Preliminary Dissertation on the Mechanisms of the Heavens [English; Astronomy]
- The New England Cook book or Young Housekeeper's Guide [English; Recipes]
- Henley's Twentieth Century Formulas, Recipes and Processes [English; Chemistry]
- Die Epiphytische Vegetation Amerikas [German; Botanical]
- Sonne und Sterne [German; Astronomy]
- Neuestes Suddeutsches Kochbuch fur alle Stande [German; Recipes]
- Le Systeme Solaire se Mouvant [French; Astronomy]
- La Navigation Aerienne L'aviation Et La Direction Des Aerostats Dans Les Temps [French; Aeronautics, History]