Here is the final project of HPML course, the team members are Andre Nakkab and Hao Tian.
Project description:
In this project, we hope to optimize a novel method of generative design which Andre Nakkab developed recently. Here is the past work repo : https://github.com/ajn313/Deep-Learning-Final-Project-Fall2021.
This architecture, which we will refer to as the Targeted Generative Adversarial Network (TGAN) utilizes a fully trained image recognition network as a sort of tertiary element in a generative adversarial network. This new architecture is meant to generate specific, convincing categorical elements based on the image set used for training. Specifically, we will be optimizing the Deep Convolutional version of this architecture, the TDCGAN
Repository:
All our code files are in the "project files" folder, you can upload the "HPML_project_script.py" to the NYU Greene HPC, then run with sbatch file.
For example, for 1 gpu running, we can use the command: sbatch project_sbatch_1_gpu.sbatch.
The models with modular learning rates each have an associated sbatch file that can run the associated script to generate appropriately named output files.
All our output pictures include the measurement of loss and time are in other folders, you can check those results.
Code structure:
Basiclly, our code has three NN modules: the Generator, the Discriminator, and the Targeter. The Targeter is a ResNet-18 model which is used to predict the label of the generated image. The Discriminator is also a ResNet-18 model, and is used to binarily classify generated images as real or fake. The Generator is a simpler CNN with 5 layers. First, we download the dataset and train the Targeter, then we train the Generator and Discriminator concurrently.
Results and Observations:
We can see from the following pictures, the traditional GAN architecture can generate images from any category in the dataset, but cannot focus in on a specific category using binary loss. Our model (TDCGAN) generates specific, convincing categorical elements based on the image set used for training.

When we only use one high-end commercial GPU, the total train time for the Targeter is 1586.81 sec, and the total train time for the GAN is 8472.17 sec
Upgrading to an Nvidia RTX 8000 sees that drop to 1395.12 sec and 8453.02, a modest increase:
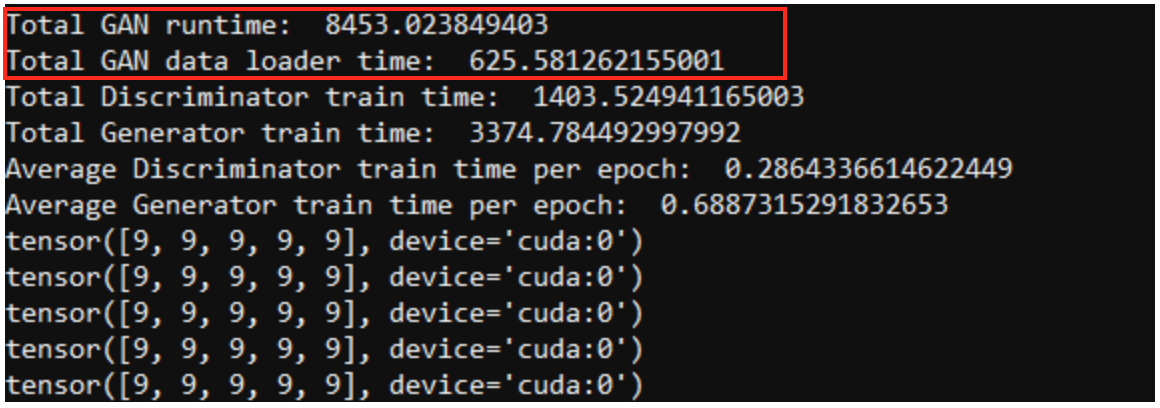
Using the optimized version distributed over two RTX 8000s and utilizing multi-threading for data loads, we find that the total train time for the Targeter is 466.24 sec, and the total train time for the GAN is 4387.42 sec:
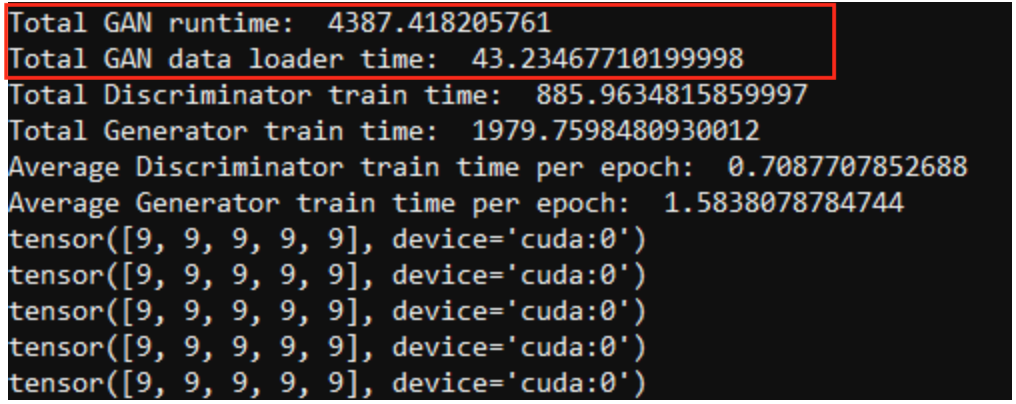
Depending on the procedure, our optimization methodology can lead to a 2-fold or 3-fold speed increase for elements of the TDCGAN architecture