{kind=link}
{kind=link}
CUDA's programming paradigm (SIMD) is different than serial programming in C/C++. This program compares the muscle work problem
In the serial program, two arrays are created. Force and distance arrays are then iterated through in order to add to a final sum. In the parallel program, three arrays are created. Force and distance arrays are generated. Then, a result array is generated by multiple threads. When the result array is complete, addition of the final sum is performed serially.
For the serial program, Clang/LLVM 3.6 is used with level 2 compiler optimizations enabled. The parallel GPU program is compiled with Nvidia's CUDA compiler driver V7.5 that wraps gcc. The serial program and GPU program results were the same in every test.
A Macbook Pro with a Core i5 at 2.7GHz and 8GB RAM is used for the serial program. GVSU's Seawolf with a Tesla K40c is used for the GPU version of the program.
Raw data results:
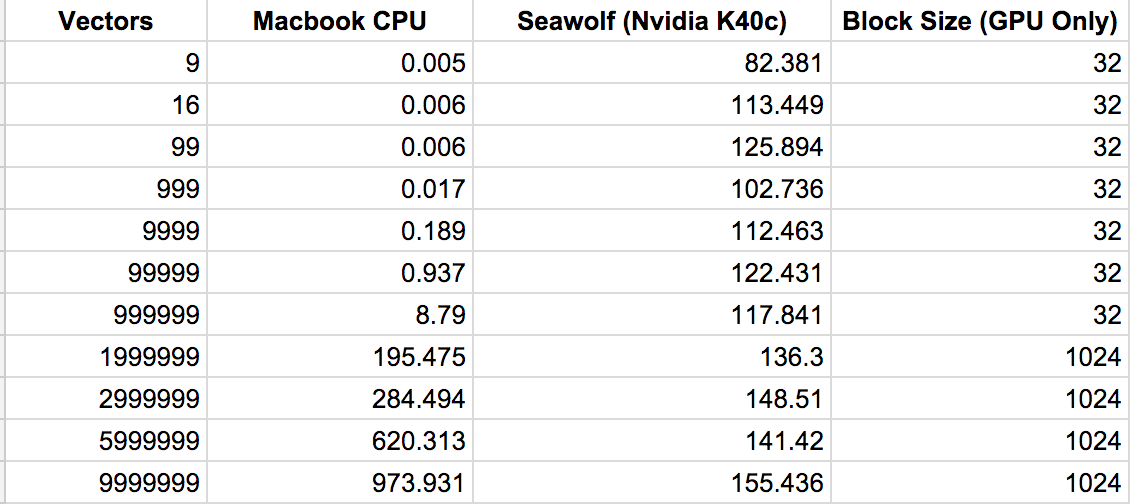
Graph:
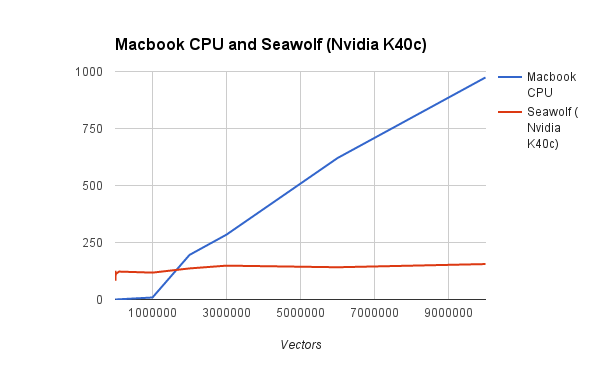
The serial program with compiler operation does well until the number of vertices get above 2 million. Parallel speedup heavily depends on the amount of data given.