Py@Codette #4 5. Support Vector Machine
SVM este un algoritm de învățare automată pe care-l putem folosi atât în probleme de regresie cât și în probleme de clasificare, cu mențiunea că învățarea se face într-o manieră supervizată. Cu alte cuvinte, algoritmul trebuie să știe în faza de training atributele și etichetele pe care ne așteptăm să le avem atașate lor (de către algoritm la finalul procesului de învățare).
În cei mai bine de cincizeci de ani de viață, SVM a avut timp să fie optimizat pentru tot felul de situații la care inițial s-a dovedit a fi sensibil, sau în care nu se aplica inițial. Prin urmare, merită să-i acordăm și noi un pic de atenție într-un așa workshop orientat către beginner level în Machine Learning, mai ales că este una dintre primele cărămizi pe care, convențional, le punem la bazele cunoștințelor noastre în acest domeniu.
Ideea centrală a SVM este găsirea unui hiperplan care să separe exemplele din setul de date în două clase. Prin urmare, SVM în forma sa clasică este mai degrabă (și mai natural) potrivit pentru probleme binare. Dacă luăm exemplul practic pe care o să lucrăm noi la workshop, cele două clase sunt diagnosticul "M/B" (Malign/Benign). Punctele noastre sunt de fapt exemplele din setul de date, ale căror "coordonate" putem considera că sunt atributele cu care au venit (în cazul breast cancer: textură, dimensiuni, etc.).
Să aruncăm o privire la imaginea de mai jos, preluată de aici:
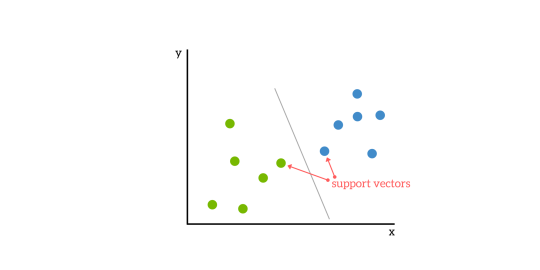
În imagine, putem spune că pe axa x sunt reprezentate valorile pentru un feature (atribut), pa axa y pentru alt atribut. Culoarea punctelor reprezintă clasele cărora acestea aparțin (label-urile).
Acestea sunt punctele cele mai apropiate de hiperplanul ce separă cele două clase. Dacă ștergem punctele astea, se va modifica și poziția hiperplanului și separarea generală a celor două clase. De aceea vectorii suport sunt elemente critice din SVM. Și tot de asta au propriul lor nume fancy care dă 2/3 din numele algoritmului.
Putem să vedem un hiperplan ca pe o linie ce separă cele două clase de care vorbeam mai sus. O mențiune aici ar fi că hiperplanul este o linie atâta vreme cât vorbim de un spațiu bi-dimensional al feature-urilor. În exemplul nostru cu "Breast Cancer Detection" vorbim de 30 de features. Prin urmare un feature este o dimensiune în SVM, iar numărul feature-urilor ne dă dimensionalitatea spațiului problemei.
Revenind la hiperplan. O intuiție pe care se impune să o dobândim despre hiperplan, este următoarea: cu cât un punct este mai departe de acesta, cu atât avem o încredere mai mare că el a fost clasificat corect. Așa ajungem să formulăm scopurile din SVM:
- vrem ca punctele noastre să fie cât mai departe de margine
- și să fie totuși de partea corectă a marginii.
Problema: cum găsim acest hiperplan? Sau, altfel spus, cum facem această separare a celor doua clase? La urma-urmei, sunt multe linii care separă corect punctele dintr-o clasă de cele din celaltă. Întrebarea ar fi cum alegem cea mai bună linie. Aici apare conceptul de margine - distanța dintre hiperplan și punctul (din oricare dintre cele două seturi de date) cel mai apropiat de acesta.
Soluția: maximizarea marginii - asta ne garantează robustețea soluției. Cu cât marginea este mai îngustă, cu atât cresc șansele de clasificare greșită a unor exemple. Foarte important de reținut este că maximizarea marginii se face după ce am ales hiperplanul care clasifică exemplele curente corect.
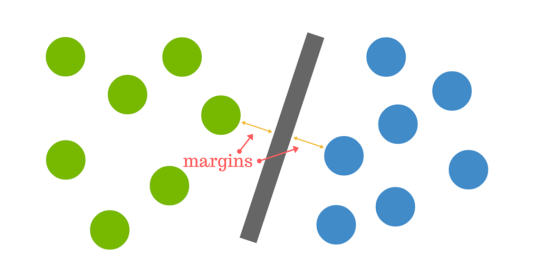
O ilustrare mai grafică a conceptului de margine, putem să vedem în imaginea de mai jos (stânga), preluată de aici:
| The concept of "margin" ilustrated | Non-linear separable data points |
|---|---|
 |
 |
Oricât de simplă ar putea să pară treaba asta cu maximizarea marginii, ne putem uita în imaginea de mai sus (dreapta) să vedem un caz unde lucrurile o iau razna și nu prea mai știm cum să alegem hiperplanul.
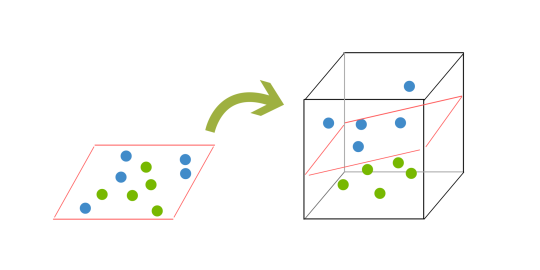
Este vorba aici despre proprietatea de "separabilitate lineară" a punctelor din plan. Adică dacă există linia aia pe care pot să o trag și să delimiteze cele două clase cât mai bine. Dar oare dacă nu există o linie care să facă acea delimitare... nu putem să facem asta cu un plan? Și exact asta facem: ne mutăm în 3D cu problema noastră (formal: într-un spațiu cu mai multe dimensiuni decât cel inițial). Tehnica asta se numește kerneling și este ca și cum ai ridica în aer o foaie cu mingi care stătea pe podea adineauri. Putem arunca o privire la imaginea alăturată ca să înțelegem mai bine cum functionează treaba asta.
Acestea sunt punctele care deși aparțin unei clase, prin feature-urile pe care le au, vom tinde să le așezăm mai degrabă în partea de plan a celeilalte clase.
SVM poate să ignore aceste extremități și să-și facă treaba cu restul punctelor ce se pot clasifica ok.
În sklearn avem vreo două implementări pentru SVM:
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma=0.0, coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, random_state=None)
sklearn.svm.LinearSVC(penalty=’l2’, loss=’squared_hinge’, dual=True, tol=0.0001, C=1.0, multi_class=’ovr’, fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)
În general o să alegem LinearSVC dacă avem un set de date foarte mare, pentru că acesta converge direct proporțional cu volumul setului de date.
Mai multe despre parametrii și metodele SVC, găsiți aici, iar despre LinearSVC aici.
O să spunem aici câteva cuvinte (totuși) despre parametrul C pe care-l observăm atât la SVC cât și la LinearSVC. Prin valoarea pe care o setăm pentru acest parametru, spunem de fapt câte de multe erori suntem dispuși să acceptăm. Cu cât C-ul este mai mic, cu atât vom avea de-a face cu margine mai mare. Iar asta ce înseamnă? Că dacă gradul de separabilitate al punctelor din setul meu de date este ridicat, atunci nu mă va afecta foarte tare grosimea mai mare a marginii. Pe de altă parte, dacă punctele din setul meu de date sunt foarte apropiate unele de celelalte, s-ar putea să vreau o margine mai îngustă, deci un C mai mic.
În exemplul practic pe care-l vom face în cadrul workshop-ului, vom antrena de mai multe ori, pe diverse bucăți din setul de date, și îl vom seta pe C la valoarea cea mai potrivită pentru datele pe care le avem la îndemână.
Avantaje
- Acuratețe bună în general.
- Merge destul de bine pe seturi de date mici (dar mai "curate").
Dezavantaje
- Dacă setul de training este mare, s-ar putea să dureze extrem de mult antrenarea.
- Dacă am zgomot în setuld e date și clase ce se suprapun, nu este o idee prea bună să folosesc SVM.
Utilizări
În general vorbim de task-uri de clasificare de text:
- category assignment (dignostic-ul de breast cancer de care ziceam mai devreme)
- spam detection
- analiza sentimentelor
It is also commonly used for image recognition challenges, performing particularly well in aspect-based recognition and color-based classification. SVM also plays a vital role in many areas of handwritten digit recognition, such as postal automation services.
Notă Această introducere în SVM a fost una foarte high-level. După cum ați putut vedea nu am intrat în formule și detalii prea multe. Noi am ales, într-un timp așa scurt să ne concentrăm mai degrabă pe a vă da intuiția ce stă în umbra SVM, mai degrabă decât rigori de calcul și prea multe interpretări geometrice. Dacă vreți ceva mai didactic de atât, căutați pe internet tutoriale din care să vedeți și formulele și calulele ce se folosesc/fac de fapt și care dau această funcționalitate a SVM.
Support Vector Machine - A Simple Explanation
An Introduction to Support Vector Machines
Support Vector Machine (SVM) - Tutorial
Understanding Support Vector Machine algorithm from examples (along with code)