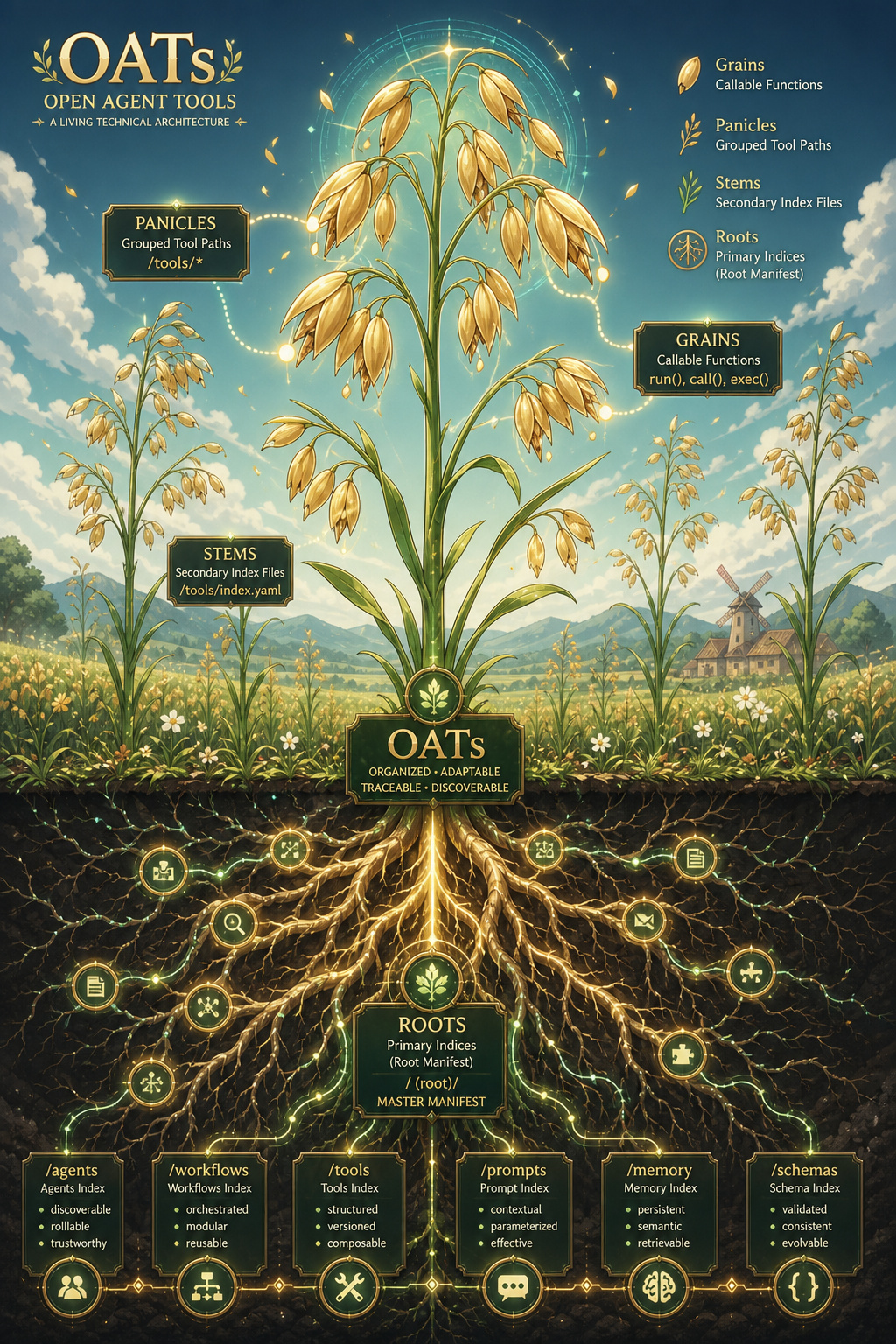
Open Agent Tools (oats) enables small-to-large self-hosted ai models to use local source code when running tool-calling agentic workloads. We actively data mine 20,800+ (2+ TB) popular github repos using large and small ai models to create reuseable: json, markdown and parquet files for local-first tool-calling models. How does it work? Over multiple passes, we compile and export a fast, compressed prompt index for all python source code in any repo. Agents refer to the local prompt index to use already-written source code on disk instead of http with mcp or having an expensive frontier ai model re-build something that is already working locally with expensive tokens. We use oats to free up large model tokens usage by delegating the local tool-calling to smaller, open source ai models.
-
Supports running local self-hosted models that can run 1-250+ local tool-calling commands using an agentic coding ai.
-
Supports over 141,000 tools using the open-agent-tools prompt indices repo. Requires cloning the repo(s) locally for the tool-calling to function.
Here is a recording showing how to install and get started quickly:

git clone https://github.com/district-solutions/open-agent-tools-coder oats
cd oats
pip install -e .
# litellm installs an older aiohttp version, upgrade this to the new version and ignore the warning
pip install --upgrade aiohttp
This section does not require any ai models, it is validating that your local python runtime is ready for matching prompts to local tools. You can modify the prompt index file locally to map functions to different prompts. Let us know what you find!
We do this before deploying ai models because we can validate the prompt-to-tool mapping works before we add complexity with multiple self-hosted local ai models.
Confirm your local repo is setup for using the included repo_uses prompt index file. This command lets you quickly check which tools will show up for any prompt before burning any tokens on ai messages. Use this approach to validate a prompt will map to the expected tool before chatting to an ai model:
get-tools -p 'get third friday'
The output should be a valid json dictionary with a dictionary containing minimal choices for a small agentic ai model to process locally with local source code tool-calling:
{
"status": true,
"actions": [
"get_third_friday"
],
"prompts": [
"generate third Friday dates for the next 6 months in YYYYMMDD format"
],
"src_files": [
"coder/date.py"
],
"partial_actions": [],
"partial_prompts": [],
"partial_src_files": [],
"index_files": [
"/opt/ds/coder/.ai/AGENT.repo_uses.python.tools.json"
],
"tool_data": {
"query": "get third friday",
"model": "bm25",
"reranked": false,
"best_files": [
"coder/date.py"
],
"best_uses": {
"coder/date.py": {
"utc": "utc datetime",
"get_utc_str": "get utc",
"get_utc_datetime": "get the current timezone-aware UTC datetime",
"get_naive_datetime": "get the current timezone-naive datetime from UTC",
"get_third_friday_dates": "generate third Friday dates for the next 6 months in YYYYMMDD format",
"run_date_tool": "run the date module to print third Friday dates for the next 6 months"
}
},
"results": [
{
"file": "coder/date.py",
"func": "get_third_friday_dates",
"description": "generate third Friday dates for the next 6 months in YYYYMMDD format",
"score": 1.0,
"retrieval_score": 1.0
}
]
},
"version": "9"
}
cd stack
We only need 1 of these models loaded on a 5090 or on an nvidia blackwell RTX 6000 to run completely locally:
- Download the quantized version of 27B: https://huggingface.co/cyankiwi/Qwen3.6-27B-AWQ-INT4 to
./stack/models/hf/qwen/Qwen3.6-27B-AWQ-INT4
and/or
-
Download the quantized version of 35B: https://huggingface.co/cyankiwi/Qwen3.6-35B-A3B-AWQ-4bit to
./stack/models/hf/qwen/Qwen3.6-35B-A3B-AWQ-4bit -
Deploying the Qwen36 27B with vLLM requires >35 GB VRAM:
./restart-vllm-qwen36-27b.sh
- Deploying the Qwen36 35B with vLLM requires >35 GB VRAM:
./restart-vllm-qwen36-35b.sh
- Download FunctionGemma from HuggingFace: https://huggingface.co/google/functiongemma-270m-it to the dir below. Use your huggingface username and huggingface token as the git username/password.
git clone https://huggingface.co/google/functiongemma-270m-it stack/models/hf/google/functiongemma-270m-it
- Now that the model is ready, deployment requires ~6 GB RAM/VRAM
./restart-tool-functiongemma-1.sh
To use local models from any directory on disk, make sure to set the CODER_CONFIG_FILE env variable to the default
# may want to add to your ~/.bashrc to always load at the abosolute path on disk:
# export CODER_CONFIG_FILE=PATH/coder.json
# for testing from the repo's root directory:
export CODER_CONFIG_FILE=$(pwd)/oats/config/coder.json
We usually keep the credentials outside the repo like:
# from the repo root dir
cp ./oats/config/coder.json /opt/oats-coder.json
Then we edit the /opt/oats-coder.json file and then set the env variable in our ~/.bashrc:
export CODER_CONFIG_FILE=/opt/oats-coder.json
$ ff
Let's build together!! 🤗 🤖 🔨 🔧
Starting up oats coder please wait...
If you hit an error, please open an issue so we can help fix it:
github.com/district-solutions/open-agent-tools-coder/issues
coder v1.2.0 · chat:latest · vllm-small
/opt/ds/oats
──────────────────────────────────────────────────
Enter to send · Alt+Enter for newline · /help for commands
mode: edit — edit — supervised, ask before writes. Switch with /edit /auto /plan /caveman
❯
❯ say hello
──────────────────────────────────────────────────
2026-05-12 17:01:23 - sprc - INFO - loading_core_tools: 15
2026-05-12 17:01:23 - sprc - INFO - using_core_tools: {'tool_search', 'websearch', 'grep', 'todowrite', 'read', 'todoread', 'edit',
'memory_write', 'bash', 'webfetch', 'glob', 'multiedit', 'memory_read', 'write', 'question'} model_id: vllm-small@hosted_vllm/chat:latest
Hello! How can I help you today?
2.0s
If you see this error, then you need to ensure your CODER_CONFIG_FILE environment variable is set to the correct file:
LLM error: litellm.AuthenticationError: AuthenticationError: Hosted_vllmException - {"error":"Unauthorized"}
Confirm the providers show up as expected:
$ pv
vllm-small (vllm-small): configured
t1 (t1): configured
ow (ow): not configured
Anthropic (anthropic): not configured
OpenAI (openai): not configured
Azure OpenAI (azure): not configured
Google AI (google): not configured
Mistral (mistral): not configured
Groq (groq): not configured
OpenRouter (openrouter): not configured
Together AI (together): not configured
Cohere (cohere): not configured
Ollama (ollama): configured