




Transparent, drop-in compression for Python's pickle — smaller files, same API.
zpickle adds high-performance compression to your serialized Python objects using multiple state-of-the-art algorithms without changing how you work with pickle.
# Replace this:
import pickle
# With this:
import zpickle as pickle
# Everything else stays the same!- Drop-in replacement for the standard
picklemodule - Transparent compression — everything happens automatically
- Multiple algorithms — choose
zstd,brotli,zlib,lzma,bzip2, orlz4(powered bycompress_utils) - Configure once, use everywhere — set global defaults for your entire app
- Smaller data — 2-10× smaller serialized data (depending on content and algorithm)
- Backward compatible — automatically reads both compressed and regular pickle data
- Complete API compatibility — all pickle functions work as expected
pip install zpickleimport zpickle as pickle
# Serializing works exactly like pickle
data = {"complex": ["nested", {"data": "structure"}], "with": "lots of repetition"}
serialized = pickle.dumps(data) # Automatically compressed!
# Deserializing works the same way
restored = pickle.loads(serialized) # Automatically decompressed!
# File operations work too
with open("data.zpkl", "wb") as f:
pickle.dump(data, f)
with open("data.zpkl", "rb") as f:
restored = pickle.load(f)import zpickle
# Configure global settings
zpickle.configure(algorithm='brotli', level=9) # Higher compression
# Or configure for a single operation
data = [1, 2, 3] * 1000
compressed = zpickle.dumps(data, algorithm='zstd', level=6)Compression ratios versus standard pickle (higher is better):
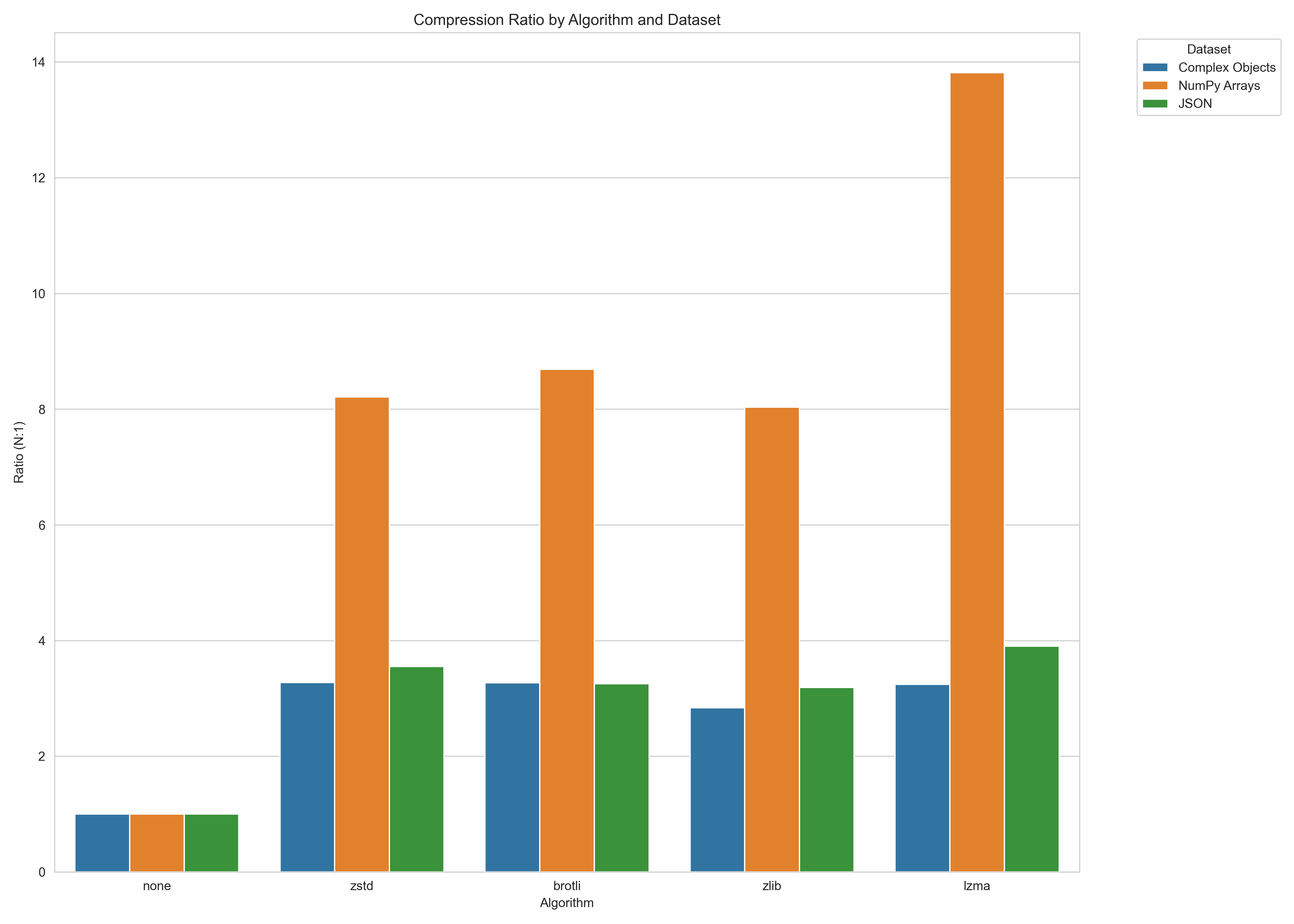
Serialization speed (MB/s, higher is better):
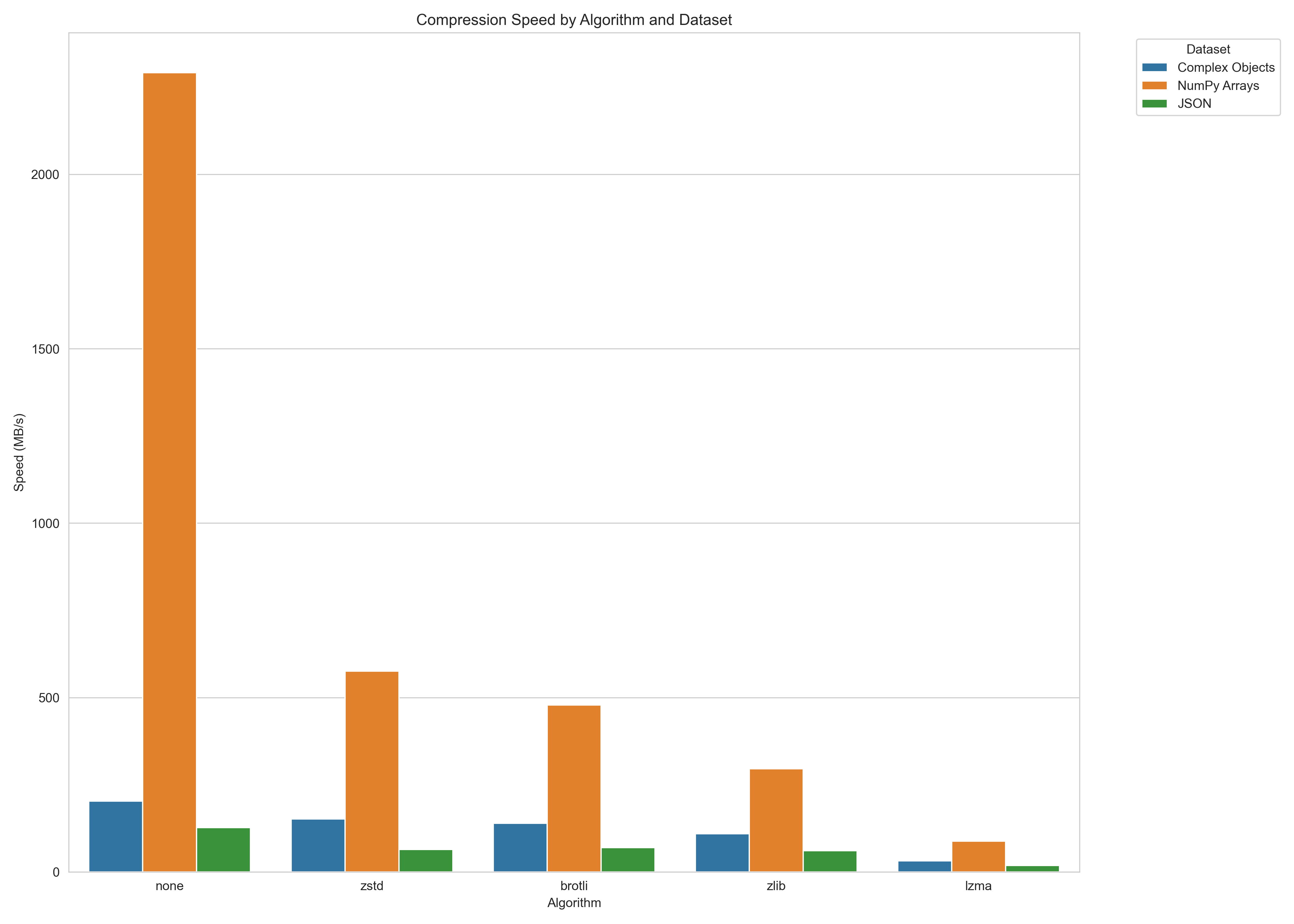
Note: Performance varies by data characteristics. Run benchmarks on your specific data for accurate results.
To run your own benchmarks, you can use:
python -m benchmarks.benchmarkzpickle applies compression with minimal overhead:
- Objects are first serialized using standard pickle
- The pickle data is compressed using the selected algorithm
- A small header (8 bytes) is added to identify the format and algorithm
- When deserializing,
zpickleauto-detects the format and decompresses if needed
zpickle maintains complete API compatibility with the standard pickle module:
dumps(obj, protocol=None, ..., algorithm=None, level=None)- Serialize and compress objectloads(data, ...)- Deserialize and decompress objectdump(obj, file, protocol=None, ..., algorithm=None, level=None)- Serialize to fileload(file, ...)- Deserialize from file
configure(algorithm=None, level=None, min_size=None)- Set global defaultsget_config()- Get current configuration
Pickler(file, ...)- Subclass of pickle.Pickler with compressionUnpickler(file, ...)- Subclass of pickle.Unpickler with decompression
- Standard
pickle: No compression, but native to Python compressed_pickle: Similar concept, but less configurablejoblib: More focused on large NumPy arrays and parallel processingmsgpack,protobuf: Different serialization formats (not pickle-compatible)
This project is distributed under the MIT License. Read more >
- GitHub Repository
- PyPI Package
- Issue Tracker
- compress-utils - The underlying compression library