The main aim of this program and device is to be an assistant for finding the emotions of people in different situations to figure out the best ways to handle problems or getting wise decisions like in shops or in public areas since the emotions of people represents their way of thinking about a case. This program is able to identify different human emotions in situations where there is more than 1 person in the camera field of view with different backgrounds.
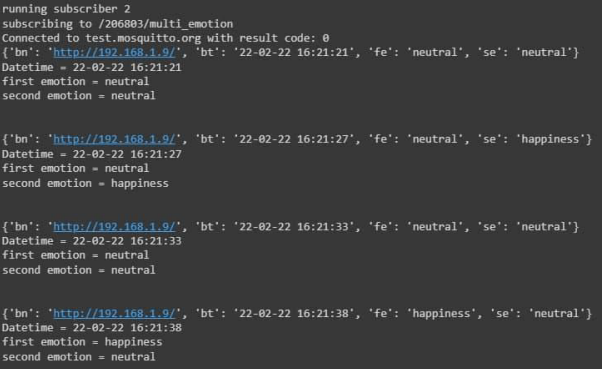
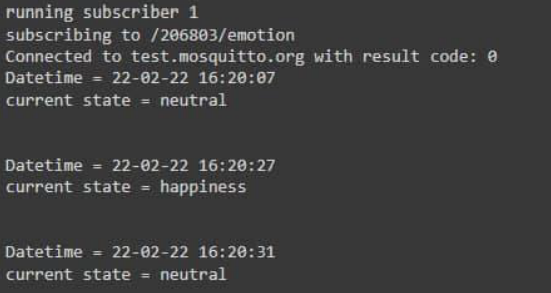
We used a publisher on the raspberry side to transfer the emotions from model to the client, there would be a subscriber for receiving the emotions for multiple users. We have 2 subscriber 1 for detecting 1 face and another for detectiong multiple faces, The reason we chose MQTT was regarding sending multiple messages at high speed at the same time.
The Viola-Jones Object Detection Framework (2001) combines the concepts of Haar-like Features, Integral Images, the AdaBoost Algorithm, and the Cascade Classifier to create a system for object detection which is fast and accurate
Emotion Detection Mode 1. Deep Convolutional Neural Network (DCNN)
For generalization purpose We used dropouts in regular intervals. We used ELU as the activation because it avoids dying relu problem but also performed well as compared to LeakyRelu atleast in this case. he_normal kernel initializer is used as it suits ELU. BatchNormalization is also used for better results
2. Mini Xception and Xception architecture
We propose two models which we evaluated by their validation accuracy and number of parameters. Reducing the number of parameters helps us overcome two important problems. First, the use of small CNN's alleviates us from slow performances in hardware-constrained systems, and second the reduction of parameters provides a 6 better generalization under Occam’s razor framework. Our first model relies on the idea of eliminating the fully connected layers. The second architecture combines the deletion of the fully connected layer and the inclusion of the combined depth-wise separable convolutions and residual modules. Both architectures were trained with the ADAM optimizer. This was achieved by having in the last convolutional layer the same number of feature maps as number of classes, and applying a softmax activation function to each reduced feature map. Our initial proposed architecture is a standard fully-convolutional neural network composed of 9 convolution layers, ReLUs, Batch Normalization and Global Average Pooling.
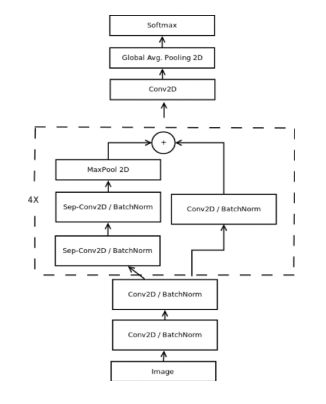
Our second model is inspired by the Xception architecture.This architecture combines the use of residual modules and depth-wise separable convolutions. Residual modules modify the desired mapping between two subsequent layers, so that the learned features become the difference of the original feature map and the desired features.
Experiments
we have tested different situations for our model which include all combinations of faces with or without glasses and hats, also we have tested for different angles with different brightness and different backgrounds. In bellowing figure we can see the results which have performed well on testing images.




Results
Improvements to inference speed The first effort, converting the model to TFLite, was not an improvement. It’s more of a necessity for running on an embedded device. This is a slightly complicated process, but in the end you have an object called an Interpreter which takes the properly formatted tensor as input and returns the prediction tensor. the optimal value for the minimum face size parameter, A smaller minimum can detect people further away, but that also means it has to scan the image more times. In a 1280x720 image, there are 733,401 possible 100x100 boxes, 731,600 possible 101x101 boxes, etc. Viola-Jones does not check all of them, but the point is, there is a huge benefit if you have a tight minimum bound on the face size. I estimated the dimensions of a face to be 0.2x0.25 m based on a rough measurement of my head. This means the bounding box for a head at one meter should be 212x198 pixels. Since the neural net input is a 48x48 pixel image, this is more resolution than needed to get good results. The image can be compressed by a factor of 4 in each dimension before running the cascade classifier which resulted in the increase of our FPS. We tried 3 different models: For the first model where we used custom model we achieved 5,700,000 parameters, 67 percent accuracy, and 2.3-2.4 FPS. For the second one where we used mini-Xception model without pruning, we achieved 58000 parameters, 64.5 accuracy, and 13-15 FPS which is observable. For the third one where used mini-Xception model with pruning we achieved 30000 parameters, 63 accuracy, and 14.5-16 FPS which is observable
Connection
We used a publisher on the raspberry side to transfer the emotions from model to the client, there would be a subscriber for receiving the emotions for multiple users. We have 2 subscriber 1 for detecting 1 face and another for detectiong multiple faces (Fig 10) The reason we chose MQTT was regarding sending multiple messages at high speed at the same time.
Conclusion
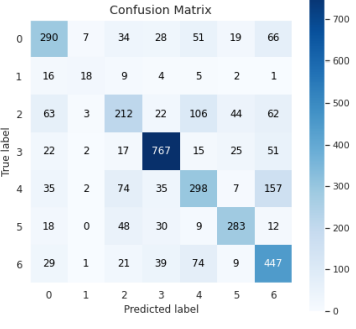
This project demonstrates an embedded device built on Raspberry Pi 4B which can 14 locate a human face in a scene and classify it’s emotional state. All of the inference is done on the device so there is no WiFi requirement or bandwidth limitation. The device, in its current state of optimization, analyzes 13 frames per second and has an average F1 score of 0.645 over 7 classes of emotion.