대화형 챗봇을 활용하여 사용자가 작성한 대화 문장을 분석해 사용자의 MBTI를 판별합니다.
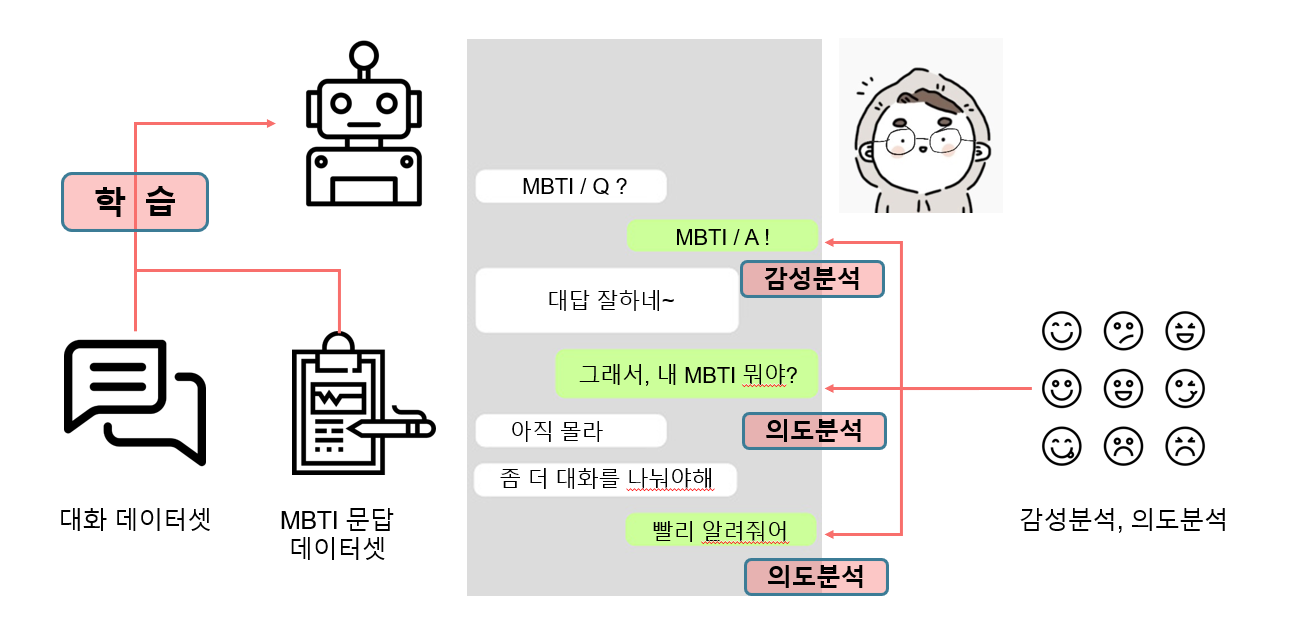
대화 데이터셋과 MBTI문답 데이터 셋으로 챗봇의 대화를 구성하고 사용자의 문장은 감성분석과 의도분석모델로 예측을 한다. 여기서 감성분석은 MBTI의 질문대한 대답이므로 좋고 싫음 / 옳고 그름 / 동의 비동의 기준의 감성분석 모델이 필요하다. 그리고 의도분석 모델을 통해 사용자의 대화 의도의 분포와 빈도로 성격유형을 예측하는데 사용한다.
■■■■■ DL 학습은 google colab에서 GPU를 사용하여 진행했습니다 ■■■■■
AI hub에서 제공하는 '주제별 텍스트 일상 대화 데이터'를 사용했습니다. 제공받은 말뭉치 안에는 2,3명의 사람이 주고받은 대화 내용이 들어있습니다.

위 그림과 같은 원천데이터와 원천데이터를 json파일로 정리한 라벨링데이터로 구분되어있습니다.
라벨링데이터에는 대화의 상세 정보와 문장 정보가 들어있고, 그 안에 각 문장의 의도가 포함되어 있습니다. 라벨링데이터 부분내용과 의도분류리스트는 다음과 같습니다.


먼저는 제공받은 라벨링데이터를 한 폴더에 압축을 푼 후 json 라이브러리를 사용해 불러옵니다.
"makedataset/data_collection.ipynb"
import os, json, copy
import pandas as pd
from tqdm import tqdm
path_2 = '주제별 텍스트 일상 대화 데이터/'
file_list_2 = os.listdir(path_2)
li = []
for i in tqdm(range(len(file_list_2))):
folder = file_list_2[i]
path_1 = '주제별 텍스트 일상 대화 데이터/'+folder+'/'
file_list_1 = os.listdir(path_1)
for n in range(len(file_list_1)):
with open(path_1+file_list_1[n], 'r', encoding='utf-8') as file:
temp_data = json.load(file)
li.append(temp_data)예시 원천데이터처럼 문장에 id가 매칭되지 않은 경우 그 앞 문장과 합쳐주는 함수를 만들었습니다.
def preprocessing_list(dial_list):
temp_list = []; cnt = 0
temp_list = copy.deepcopy(dial_list)
for i in range(len(dial_list)):
i -= cnt
if temp_list[i][0] not in ['1','2','3','4','5'] :
temp_list[i-1] += temp_list[i].lstrip()
temp_list.pop(i); cnt += 1
return temp_list이제 대화데이터셋을 추출합니다.
앞에 만든 함수를 사용하여 원천데이터를 정제하고, 각각 사용자가 발화 한 후 다시 본인의 발화가 나올때까지의 발화를 모두 선발화와 대답으로 쌍을 이루게 했습니다.
그리고 예기치 못한 에러를 방지하기 위해 for문 안에 try/except 문을 사용하여 대화데이터셋을 추출하였습니다.
dialog = pd.DataFrame(columns=['Q','Q_intent', 'A', 'A_intent'])
for i in tqdm(range(len(li))):
sen = preprocessing_list(li[i])
intent = li[i]['info'][0]['annotations']['lines']
for j in range(len(sen)):
if len(sen) != len(intent):
print(f"len(sen) != len(intent) : {li[i]['dataset']['name']}")
break
else :
for k in range(1,6):
if j+k >= len(sen)-1:
break
elif sen[j][0] == sen[j+k][0]:
break
if intent[j]['speechAct'] != intent[j+k]['speechAct']:
# dialog = pd.concat([dialog,pd.DataFrame({'Q' : [sen[j].split(':')[-1].lstrip()], 'Q_intent' : intent[j]['speechAct'], 'A' : [sen[j+k].split(':')[-1].lstrip()], 'A_intent' : intent[j+k]['speechAct']})],ignore_index=True)
try:
dialog = pd.concat([dialog,pd.DataFrame({'Q' : [sen[j].split(':')[-1].lstrip()],
'Q_intent' : intent[j]['speechAct'],
'A' : [sen[j+k].split(':')[-1].lstrip()],
'A_intent' : intent[j+k]['speechAct']})], ignore_index=True)
except :
print(li[i]['dataset']['name'])
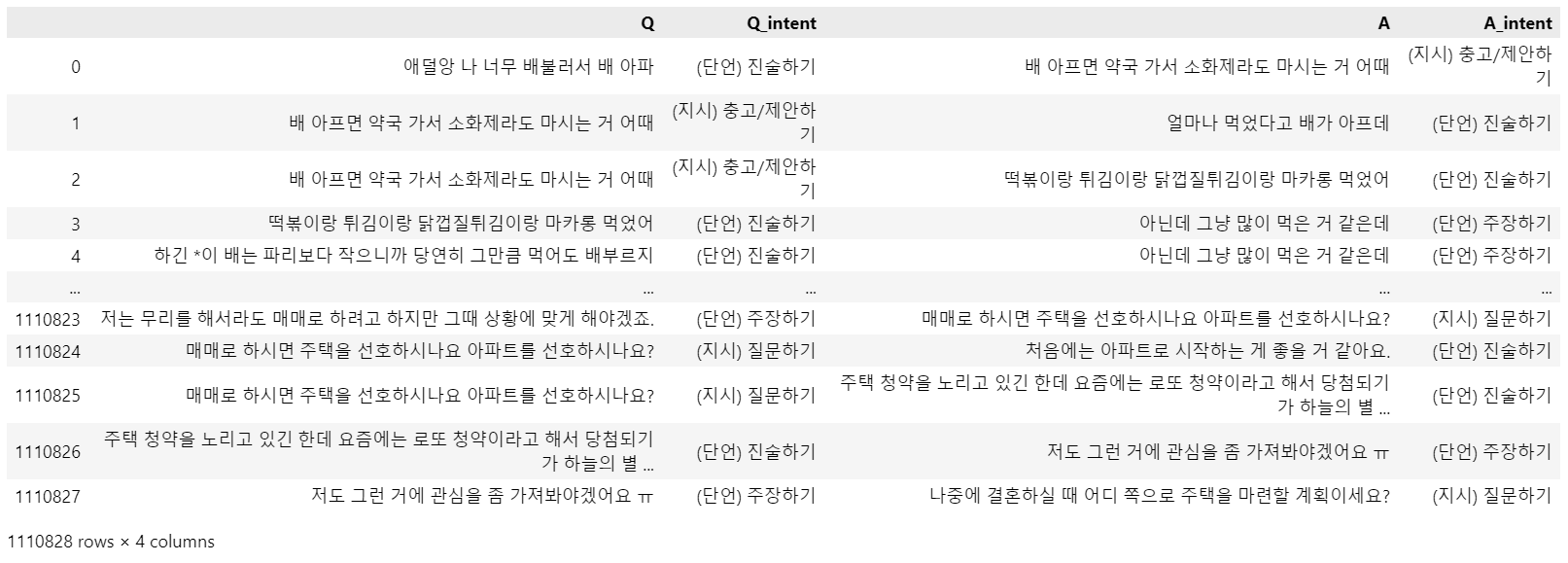
print(f'대화번호i:{i} / 문장번호j:{j} / 쌍번호k:{k}')위 코드를 통해 만들어진 대화데이터셋은 다음과 같습니다.
다음으로 의도분류와 감성분류를 위한 데이터셋을 추출합니다.
dialog = pd.read_csv('dataset/dialog_chatbot.csv')
intent_model = pd.DataFrame(columns=['sentence','intent'])
Q_temp_sen = pd.DataFrame()
Q_temp_int = pd.DataFrame()
Q_temp_sen['sentence'] = dialog['Q']
Q_temp_int['intent'] = dialog['Q_intent']
Q_temp = pd.concat([Q_temp_sen,Q_temp_int], axis=1)
A_temp_sen = pd.DataFrame()
A_temp_int = pd.DataFrame()
A_temp_sen['sentence'] = dialog['A']
A_temp_int['intent'] = dialog['A_intent']
A_temp = pd.concat([A_temp_sen,A_temp_int], axis=1)
intent_model = pd.concat([Q_temp,A_temp], ignore_index=True)
intent_model.drop(intent_model.loc[intent_model['intent']=='N/A'].index, axis=0, inplace=True)
intent_model
intent_model.drop(['Unnamed: 0'], axis=1, inplace=True) # 불필요 column 제거
intent_model.dropna(inplace=True) # 결측치 제거
intent_model.drop(intent_model[intent_model.duplicated()].index, axis=0, inplace=True) # 중복값 제거
intent_model.drop(intent_model[intent_model['intent'] == '(언약) 위협하기'].index, axis=0, inplace=True) # 불필요 label 제거
intent_model.reset_index(drop=True, inplace=True) # 인덱스 초기화
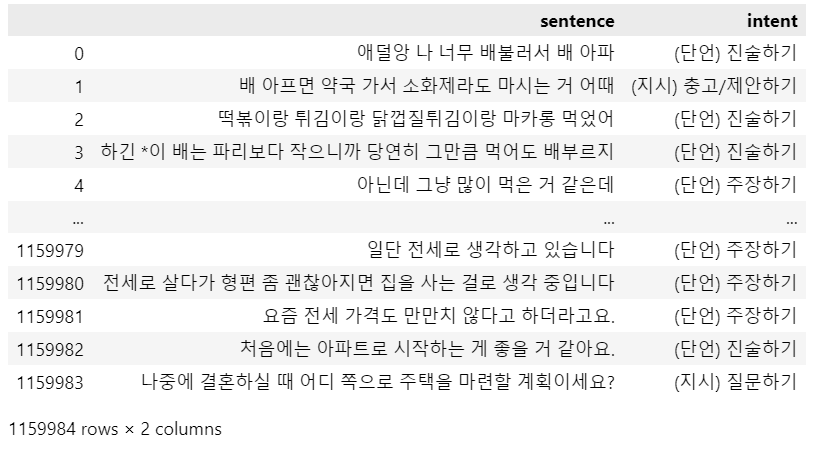
intent_model.to_csv('intent_model_dataset.csv')위 코드를 통해 만들어진 의도/감성분류 데이터셋은 다음과 같습니다.
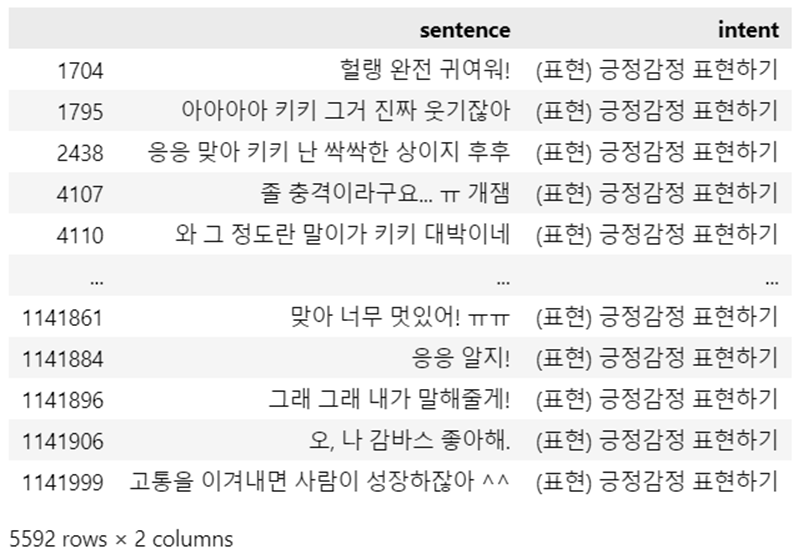
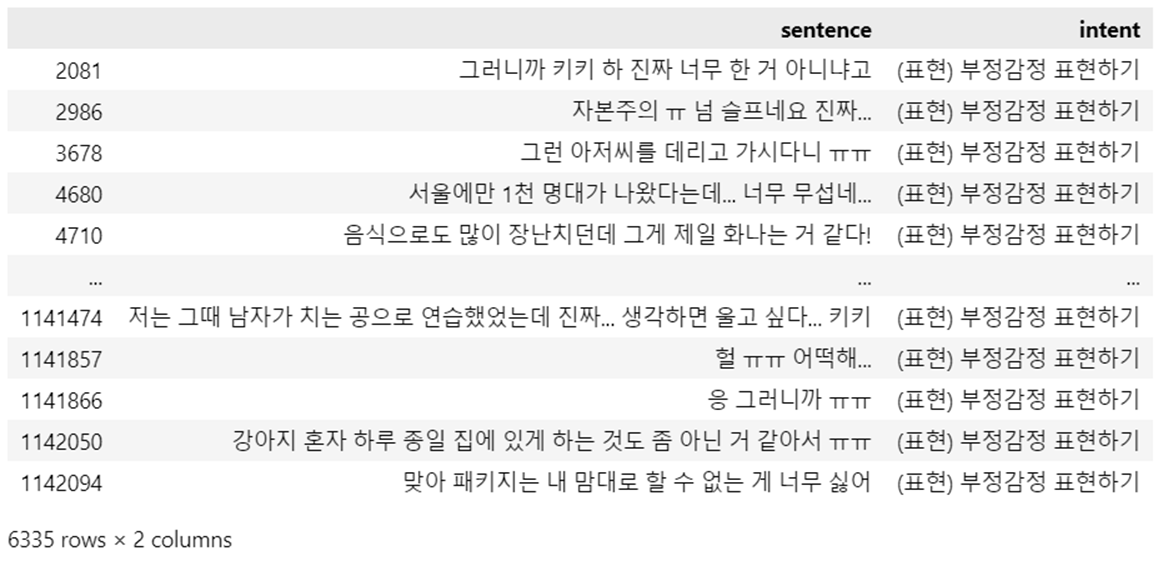
제공받은 라벨링 데이터의 긍정/부정 기준은 기분좋은/나쁜 느낌이 있는 문장을 기준으로 하고있어서
의도했던 좋고 싫음 / 옳고 그름 / 동의 비동의 기준과 다릅니다.
때문에 기준에 맞는 새로운 라벨링이 필요했습니다.
함께 사용되었을때 긍정/부정 문장임을 알 수 있는 단어와 문장의 앞머리에 왔을 때 긍정/부정을 결정지을 수 있는 키워드들을 선정하고,
키워드를 기반으로 의도한 기준에 맞는 문장을 추출하는 명령어를 입력합니다.
"NP_model_make.ipynb"
origin_df = pd.read_csv('C:/Users/Lee_Hyo_Jae/Desktop/new_project/dataset/intent_model_dataset.csv')
df = copy.deepcopy(origin_df)
df.drop(['Unnamed: 0'], axis=1, inplace=True) # 불필요 column 제거
df.drop(df.loc[df['sentence'].str.contains('\*')].index, axis=0, inplace=True) # 이름, 주소 같은 개인정보는 ***처리 되어있으므로 '*' 포함문장 제거
df = df.loc[df['sentence'].str.len() <= 100] # 문장 총 길이 100이상 제거
df.reset_index(inplace=True, drop=True) # 인덱스
df.loc[(df['sentence'].str.contains('응') & df['sentence'].str.contains('좋아')), 'intent'] = '긍정'
df.loc[(df['sentence'].str.contains('응') & df['sentence'].str.contains('맞아')), 'intent'] = '긍정'
df.loc[(df['sentence'].str.contains('아니') & df['sentence'].str.contains('싫어')), 'intent'] = '부정'
fst_P_key = ['맞어','맞아','마자','마쟈','마저','맞지','응 ','응!','응응 ','웅 ','웅웅 ','웅!','좋아 ','좋다']
fst_N_key = ['아뇨','아니','아닌데','아녀','아니여','아냐','싫어 ','싫어,','싫어!','시러','싫은데','안돼','안되지','안된','별로야']
for i in fst_P_key:
df.loc[(df['sentence'].str.startswith(i)), 'intent'] = '긍정'
for i in fst_N_key:
df.loc[(df['sentence'].str.startswith(i)), 'intent'] = '부정'사전학습된 KLUE/BERT-base모델의 토크나이즈를 불러옵니다. 그리고 토크나이즈를 사용하여 긍정과 부정, 그리고 그 외의 중립 문장에서 많이 사용된 ( 총문장의 1/10만큼 사용된 ) 토큰을 각각 추출합니다.
tokenizer = BertTokenizer.from_pretrained("klue/bert-base")
# 부정 토큰 추출
# token 바구니
N_count = []
# 필요 문장 추출
N_intent = ['(표현) 부정감정 표현하기', '(단언) 반박하기', '(언약) 거절하기', '부정']
# 필요 문장 구성하는 모든 token 바구니에 넣기
for intent in N_intent :
for i in df.loc[(df['intent'] == intent), 'sentence']:
N_count += tokenizer.encode(i)
# token 고유값과 개수 / N_uni[0] = 고유값 리스트 / N_uni[1] = 고유값 개수 리스트
N_uni = np.unique(N_count, return_counts=True)
# 고유값 개수 내림차순 정렬
N_cnt = sorted(list(set(N_uni[1])),reverse=True)
# N_many = N_uni[0]에서 검색할 index값 / N_token = 사용 횟수가 많은 token
N_many = []
N_token = []
for i in N_cnt:
if i > 2700 :
N_many.append(list(N_uni[1]).index(i))
for j in range(len(N_many)) :
N_token.append(N_uni[0][N_many[j]])
print(N_many)
print(tokenizer.decode(N_token))
# 긍정 토큰 추출
# token 바구니
P_count = []
# 필요 문장 추출
P_intent = ['(표현) 긍정감정 표현하기', '(표현) 감사하기', '긍정']
# 필요 문장 구성하는 모든 token 바구니에 넣기
for intent in P_intent :
for i in df.loc[(df['intent'] == intent), 'sentence']:
P_count += tokenizer.encode(i)
# token 고유값과 개수 / N_uni[0] = 고유값 리스트 / N_uni[1] = 고유값 개수 리스트
P_uni = np.unique(P_count, return_counts=True)
# 고유값 개수 내림차순 정렬
P_cnt = sorted(list(set(P_uni[1])),reverse=True)
# N_many = N_uni[0]에서 검색할 index값 / N_token = 사용 횟수가 많은 token
P_many = []
P_token = []
for i in P_cnt:
if i > 7700 :
P_many.append(list(P_uni[1]).index(i))
for j in range(len(P_many)) :
P_token.append(P_uni[0][P_many[j]])
print(P_many)
print(tokenizer.decode(P_token))
# 중립 토큰 추출
# token 바구니
M_count = []
# 필요 문장 추출
M_intent = ['(단언) 진술하기', '(지시) 충고/제안하기', '(단언) 주장하기', '(지시) 질문하기', '(지시) 부탁하기',
'(표현) 사과하기', '(지시) 명령/요구하기', '턴토크 사인(관습적 반응)',
'(언약) 약속하기(제3자와)/(개인적 수준)', '(표현) 인사하기', '(선언/위임하기)']
# 필요 문장 구성하는 모든 token 바구니에 넣기
for intenti in range(len(M_intent)):
if df.loc[(df['intent'] == intent), 'sentence'].count() > 1000:
for i in (df.loc[(df['intent'] == intent), 'sentence']):
M_count += tokenizer.encode(i)
else:
for i in (df.loc[(df['intent'] == intent), 'sentence']):
M_count += tokenizer.encode(i)
# token 고유값과 개수 / N_uni[0] = 고유값 리스트 / N_uni[1] = 고유값 개수 리스트
M_uni = np.unique(M_count, return_counts=True)
# 고유값 개수 내림차순 정렬
M_cnt = sorted(list(set(M_uni[1])),reverse=True)
# M_many = N_uni[0]에서 검색할 index값 / M_token = 사용 횟수가 많은 token
M_many = []
M_token = []
for i in M_cnt:
if i > 100000 :
M_many.append(list(M_uni[1]).index(i))
for j in range(len(M_many)) :
M_token.append(M_uni[0][M_many[j]])
print(M_many)
print(tokenizer.decode(M_token))그리고 긍정토큰 안에 있는 부정,중립토큰 / 부정토큰 안에 있는 긍정,중립토큰를 제외하여 정제된 토큰를 추출한 뒤, 앞서 선정한 키워드와 토큰을 기반으로 긍정,부정키워드를 결정했습니다.
# 중복값 제거
print(tokenizer.decode((set(N_token).difference(set(P_token))).difference(set(M_token))))
print(tokenizer.decode((set(P_token).difference(set(N_token))).difference(set(M_token))))
N_keyword = ['싫어\.\.', '아니']
P_keyword = ['맞아', '응응', '응\.', '응,']필요한만큼의 문장을 추출한 뒤
부정 키워드를 담은 긍정문장 / 긍정키워드 토큰를 담은 부정문장 / 긍정,부정키워드를 담은 중립문장을 제거합니다.
# 부정키워드 포함 긍정문장 제거
for intent in P_intent:
for key in N_keyword:
df.drop(df.loc[(df['intent'] ==intent)&df['sentence'].str.contains(key)].index, axis=0, inplace=True)
# 긍정키워드 포함 부정문장 제거
for intent in N_intent:
for key in P_keyword:
df.drop(df.loc[(df['intent'] ==intent)&df['sentence'].str.contains(key)].index, axis=0, inplace=True)
# 필요한 데이터를 추출하기 위한 DataFrame 생성
temp_df = pd.DataFrame()
df_ = copy.deepcopy(df)
# 기존 데이터에서 긍정, 부정 문장 제거
for intent in (N_intent+P_intent):
df_.drop(df_[df_['intent'] == intent].index, axis=0, inplace=True)
# 남은 중립문장 중 필요한만큼 문장 추출
temp_df = pd.concat([temp_df,df_.sample(n=13000)], ignore_index=True)
# 중립문장 중 긍정/부정 키워드 포함한 문장 제거
for key in (N_keyword+P_keyword):
temp_df.drop(temp_df.loc[temp_df['sentence'].str.contains(key)].index, axis=0, inplace=True)
# 필요한만큼 긍정/부정문장 추출
for intent in (N_intent+P_intent):
if df.loc[df['intent']==intent, 'intent'].count() > 10000:
temp = pd.concat([temp,df[df['intent'] == intent].sample(n=10000)], ignore_index=True)
elif df.loc[df['intent']==intent, 'intent'].count() > 1000:
temp = pd.concat([temp,df[df['intent'] == intent].sample(n=1000)], ignore_index=True)
else :
temp = pd.concat([temp,df[df['intent'] == intent]], ignore_index=True)
temp.loc[(temp['intent'] == '(표현) 부정감정 표현하기')|(temp['intent'] == '(언약) 거절하기')|
(temp['intent'] == '(단언) 반박하기'), 'intent'] = '부정'
temp.loc[(temp['intent'] == '(표현) 긍정감정 표현하기')|(temp['intent'] == '(표현) 감사하기'), 'intent'] = '긍정'
temp.loc[(temp['intent'] != '부정')&(temp['intent'] != '긍정'), 'intent'] = '중립'
df = copy.deepcopy(temp)
temp = list(df['intent'].unique())
for i in temp :
print(i,df.loc[df['intent']==i,'intent'].count())
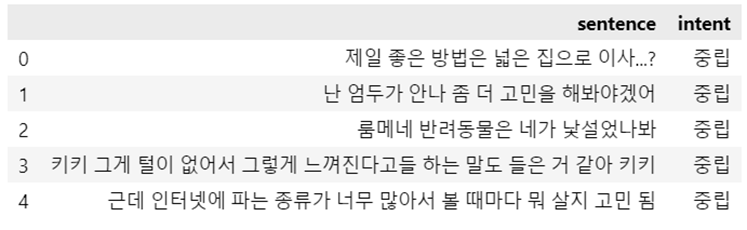
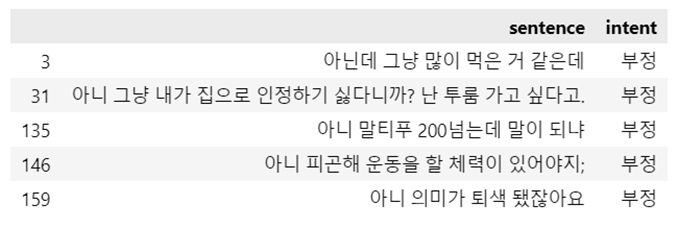
# 클래수 개수
lable_num = len(df['intent'].unique())
lable_num
# str -> int 라벨변경
label_dict = {0: '긍정', 1: '부정', 2: '중립'}
for idx, intent_lab in label_dict.items() :
df.loc[df['intent'] == intent_lab, 'intent'] = idx
df = df.sample(frac=1).reset_index(drop=True)8:2 비율로 train데이터와 test데이터를 나눠줍니다.
train_data = pd.DataFrame()
len_ = df['intent'].count()
train_data = pd.concat([train_data,df.loc[:(len_*8)/10]],ignore_index=True)
test_data = pd.DataFrame()
len_ = df['intent'].count()
test_data = pd.concat([test_data,df.loc[(len_*8)/10:]],ignore_index=True)정제된 데이터가 Bert모델에 사용수 있도록 정수인코딩, 어텐션인코딩, 세그먼트인코딩을 진행하고 학습에 맞는 형태를 갖을 수 있도록 함수를 만듭니다. 그리고 데이터를 함수에 적용시킵니다.
def convert_examples_to_features(examples, labels, max_seq_len, tokenizer):
input_ids, attention_masks, token_type_ids, data_labels = [], [], [], []
for example, label in tqdm(zip(examples, labels), total=len(examples)):
# input_id는 워드임베딩을 위한 문장의 정수인코딩
input_id = tokenizer.encode(example, max_length=max_seq_len, pad_to_max_length=True)
# attention_mask는 실제단어가 위치하면 1, 패딩의 위치에는 0인 시퀀스.
padding_count = input_id.count(tokenizer.pad_token_id)
attention_mask = [1] * (max_seq_len - padding_count) + [0] * padding_count
# token_type_id은 세그먼트인코딩
token_type_id = [0] * max_seq_len
assert len(input_id) == max_seq_len, "Error with input length {} vs {}".format(len(input_id), max_seq_len)
assert len(attention_mask) == max_seq_len, "Error with attention masklength {} vs {}".format(len(attention_mask), max_seq_len)
assert len(token_type_id) == max_seq_len, "Error with token type length{} vs {}".format(len(token_type_id), max_seq_len)
input_ids.append(input_id)
attention_masks.append(attention_mask)
token_type_ids.append(token_type_id)
data_labels.append(label)
input_ids = np.array(input_ids, dtype=int)
attention_masks = np.array(attention_masks, dtype=int)
token_type_ids = np.array(token_type_ids, dtype=int)
data_labels = np.asarray(data_labels, dtype=np.int32)
return (input_ids, attention_masks, token_type_ids), data_labels
train_X, train_y = convert_examples_to_features(train_data['sentence'], train_data['intent'],
max_seq_len=max_seq_len, tokenizer=tokenizer)
test_X, test_y = convert_examples_to_features(test_data['sentence'], test_data['intent'],
max_seq_len=max_seq_len, tokenizer=tokenizer)이제 사전학습된 KLUE/BERT-base 모델의 다중분류모델을 불러와 준비된 데이터를 사용하여 학습시킵니다.
optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
model = TFBertForSequenceClassification.from_pretrained("klue/bert-base", num_labels=lable_num, from_pt=True)
model.compile(optimizer=optimizer, loss=model.hf_compute_loss, metrics=['accuracy'])
model.fit(train_X, train_y, epochs=8, batch_size=128, validation_split=0.2)학습된 모델로 문장의 감성을 분류합니다.
def sentiment_predict(new_sentence):
input_id = tokenizer.encode(new_sentence, max_length=max_seq_len, pad_to_max_length=True)
padding_count = input_id.count(tokenizer.pad_token_id)
attention_mask = [1] * (max_seq_len - padding_count) + [0] * padding_count
token_type_id = [0] * max_seq_len
input_ids = np.array([input_id])
attention_masks = np.array([attention_mask])
token_type_ids = np.array([token_type_id])
encoded_input = [input_ids, attention_masks, token_type_ids]
score = np.argmax(model.predict(encoded_input)[0])
print('sentence :',new_sentence)
print(label_dict[score])
new_sentence = input('sentence > ')
sentiment_predict(new_sentence)
의도분류 모델은 기존 제공받은 라벨링데이터에서 ['(언약) 위협하기', (표현) 부정감정 표현하기, (표현) 긍정감정 표현하기, (선언/위임하기)]
4가지를 제거한 13가지 의도로 클래스를 구성하여 모델을 구축했습니다.
origin_df = pd.read_csv('C:/Users/Lee_Hyo_Jae/Desktop/new_project/dataset/intent_model_dataset.csv')
df = copy.deepcopy(origin_df)
df.drop(['Unnamed: 0'], axis=1, inplace=True) # 불필요 column 제거
df.dropna(inplace=True) # 결측치 제거
df.drop(df[df.duplicated()].index, axis=0, inplace=True) # 중복값 제거
df.drop(df[df['intent'] == '(언약) 위협하기'].index, axis=0, inplace=True) # 불필요 label 제거
df.drop(df[df['intent'] == '(표현) 부정감정 표현하기'].index, axis=0, inplace=True) # 불필요 label 제거
df.drop(df[df['intent'] == '(표현) 긍정감정 표현하기'].index, axis=0, inplace=True) # 불필요 label 제거
df.drop(df[df['intent'] == '(선언/위임하기)'].index, axis=0, inplace=True) # 불필요 label 제거
df.drop(df.loc[df['sentence'].str.contains('\*')].index, axis=0, inplace=True)
df = df.loc[df['sentence'].str.len() <= 100]
df.reset_index(drop=True, inplace=True)클래스 개수 선언, # str -> int 라벨변경
# 클래스 개수
lable_num = len(df['intent'].unique())
lable_num
# str -> int 라벨변경
intet_label = list(df['intent'].unique())
label_dict = {}
for idx, intent_lab in enumerate(intet_label) :
df.loc[df['intent'] == intent_lab, 'intent'] = idx
label_dict[idx] = intent_lab8:2 비율로 train데이터와 test데이터를 나눠줍니다.
train_data = pd.DataFrame()
test_data = pd.DataFrame()
print(train_data)
print(test_data)
for k,v in label_dict.items():
len_ = df.loc[df['intent'] == k,'intent'].count()
if len_ > 20000 :
temp = df.loc[df['intent'] == k].sample(n=20000).reset_index(drop=True)
train_data = pd.concat([train_data,temp.loc[:16000]],ignore_index=True)
test_data = pd.concat([test_data,temp.loc[16000:]],ignore_index=True)
else :
temp = df.loc[df['intent'] == k].reset_index(drop=True)
train_data = pd.concat([train_data,temp.loc[:(len_*8)/10]],ignore_index=True)
test_data = pd.concat([test_data,temp.loc[(len_*8)/10:]],ignore_index=True)
train_data = train_data.sample(frac=1).reset_index(drop=True)
test_data = test_data.sample(frac=1).reset_index(drop=True)데이터 추출, 전처리를 제외한 모델 학습은 감성분류와 동일합니다.

데이터셋은 10만개 이상의 대화쌍을 확보했으나 성능과 시간의 문제로 데이터 개수를 줄여 fine-tune 하였습니다. 이름이나 주소같은 개인정보를 대체한 * 을 포함한 문장, 문장 길이가 50자 이상되는 문장을 제거하였습니다.
df = pd.read_csv('dialog_chatbot.csv')
df.drop(['Unnamed: 0'], axis=1, inplace=True)
df.drop(df.loc[df['Q'].str.contains('\*')].index, axis=0, inplace=True)
df.drop(df.loc[df['A'].str.contains('\*')].index, axis=0, inplace=True)
df.drop(df.loc[df['Q'].str.len() >= 50].index, axis=0, inplace=True)
df.drop(df.loc[df['A'].str.len() >= 50].index, axis=0, inplace=True)그리고 의도별로 다양한 문장을 학습시키기 위해 조건문을 활용하여 문장을 추출하였습니다.
intet_label = list(df['Q_intent'].unique())
label_dict = {}
for idx, intent_lab in enumerate(intet_label) :
label_dict[idx] = intent_lab
Q_int_li = list(set(df['Q_intent'].unique()))
train_data = pd.DataFrame()
for v,k in label_dict.items():
len_ = df.loc[df['Q_intent'] == k,'Q_intent'].count()
if len_ > 10000 :
train_data = pd.concat([train_data,df.loc[df['Q_intent'] == k].sample(n=10000)],ignore_index=True)
else :
train_data = pd.concat([train_data,df.loc[df['Q_intent'] == k]],ignore_index=True)
for v,k in label_dict.items():
len_ = df.loc[df['A_intent'] == k,'A_intent'].count()
if len_ > 10000 :
train_data = pd.concat([train_data,df.loc[df['A_intent'] == k].sample(n=10000)],ignore_index=True)
else :
train_data = pd.concat([train_data,df.loc[df['A_intent'] == k]],ignore_index=True)
train_data.drop(train_data[train_data.duplicated()].index, axis=0, inplace=True)
train_data = train_data.sample(frac=1).reset_index(drop=True)해당 추출 결과 다음과 같은 데이터셋으로 학습을 진행하게 되었습니다.
이제 generater 함수를 사용해 Dataset객체를 생성하고 padded_batch 함수를 사용해 batch로 나누어줍니다.
def get_chat_data():
for question, answer in zip(train_data.Q.to_list(), train_data.A.to_list()):
bos_token = [tokenizer.bos_token_id]
eos_token = [tokenizer.eos_token_id]
sent = tokenizer.encode('<usr>' + question + '<sys>' + answer)
yield bos_token + sent + eos_token
dataset = tf.data.Dataset.from_generator(get_chat_data, output_types=tf.int32)
batch_size = 128
dataset = dataset.padded_batch(batch_size=batch_size, padded_shapes=(None,), padding_values=tokenizer.pad_token_id)만들어진 데이터셋을 사용해 학습을 진행합니다.
adam = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08)
if len(train_data) % batch_size == 0:
steps = len(train_data) // batch_size
else :
steps = len(train_data) // batch_size + 1
EPOCHS = 5
for epoch in range(EPOCHS):
epoch_loss = 0
for batch in tqdm.notebook.tqdm(dataset, total=steps):
with tf.GradientTape() as tape:
result = model(batch, labels=batch)
loss = result[0]
batch_loss = tf.reduce_mean(loss)
grads = tape.gradient(batch_loss, model.trainable_variables)
adam.apply_gradients(zip(grads, model.trainable_variables))
epoch_loss += batch_loss / steps
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, epoch_loss))