The goal of this application is to use a generated log file with random sequences of characters as log messages, and processes the file and extract different distributions of the messages. These proccess are run in parellel using the hadoop map reduce framework. The log file is initially split into shards, and is run through 4 map reduce tasks which process the data into different distributions. The map reduce tasks are also run through AWS EMR as well.
IntelliJ IDEA 2022.2.1, Scala 3.2.0, Hadoop 3.3.4, Sbt 1.7.1, JDK 11.0.16.1
-
Note: Make sure all tools are running on administrator mode including command line and Intellij
-
Clone project using Intellij IDEA -> Get from VCS -> URL:
git@github.com:harshalpatel165/LogAnalysis-MapReduce.git-> Directory: directory of your choosing -> Clone -
Using built-in terminal use:
To compile:
sbt clean compileto test:
sbt clean testto build Jar:
sbt clean compile assembly
-
In terminal:
Running task 1:
sbt "run 1 [absolute_path_to_input_folder] [absolute_path_to_output_folder1]"Running task 2:
sbt "run 2 [absolute_path_to_input_folder] [absolute_path_to_temporary_folder] [absolute_path_to_output_folder2]"Running task 3:
sbt "run 3 [absolute_path_to_input_folder] [absolute_path_to_output_folder3]"Running task 4:
sbt "run 4 [absolute_path_to_input_folder] [absolute_path_to_output_folder4]"
Note: The input folder has already been given with a log file that has been generated and split into shards using split data.log -l 1000. It is located in src/main/resources/input
Each time these tasks are run there should not be a output folder or temporary folder created, the framework will create it for you. Make sure to delete any output folders already existing or changing the output path folder to a different name that does not exist. It is recommeneded to put the absolute_path_to_output_folder in the resources folder where the input folder is.
To get the absolute paths of the input folder and output folder, on Intellij on the left hand side, expand src/main/resources/ and right click the input folder -> Copy Path/Reference -> Absolute Path.
The output is given in the output folder in a file named part-r-00000. To convert it to csv run
cat [absolute_path_to_file] > [absolute_path_to_file.csv]
-
On command line go to where hadoop home directory is. Start hadoop using
sbin/start-all.cmd. -
Then make sure you have built the project using the assembly command mentioned above on intellij.
-
In the local project directory under
target/scala-3.2.0There should be a jar file there. Copy and note down the absolute path of that jar file. -
then while hadoop is running on the terminal copy the input folder in the local filesystem to the hadoop file system using
hdfs dfs -copyFromLocal [absolute_path_to_input_folder] /input -
Running
hdfs dfs -ls /should look something like this:
-
Now to run each task use the following commands where the
[absolute_path_to_jar_file]is the path noted in step 3:Running task 1:
hadoop jar [absolute_path_to_jar_file] 1 /input /output/output1"Running task 2:
hadoop jar [absolute_path_to_jar_file] 2 /input /output/tmpoutput /output/output2"Running task 3:
hadoop jar [absolute_path_to_jar_file] 3 /input /output/output3"Running task 4:
hadoop jar [absolute_path_to_jar_file] 4 /input /output/output4" -
After a task has fully finished running, doing
hdfs dfs -ls /output/output[task_number]should look like this:
-
To see output run:
hdfs dfs -cat /output/output[task_number]/part-r-00000 -
and to convert it to csv:
hdfs dfs -cp /output/output[task_number]/part-r-00000 /output/output[task_number]/part-r-00000.csv -
To open the csv the csv file should be copied to the local filesystem first using
hdfs dfs -copyToLocal /output/output[task_number]/part-r-00000.csv [local_path]
- Please follow Youtube tutorial:
-
Task 1: The distribution of the different type of messages(INFO,WARN,DEBUG,ERROR) across predefined time intervals(mentioned below) and injected string instances of the designated regex pattern(mentioned below)
-
Task 2: Time intervals of 1 second sorted in the descending order that contained most log messages of the type ERROR with injected regex pattern string instances
-
Task 3: The distribution of the different type of messages(INFO,WARN,DEBUG,ERROR)
-
Task 4: The number of characters in each log message for each log message type that contain the highest number of characters in the detected instances of the designated regex pattern.
- HelperUtils Package
- CreateLogger.scala: Sets up loggger instance used for debugging
- ObtainConfigReference.scala: Sets up config reference which is used to retrieve predefined variables defined in the
application.conflocated in resources
- MapReduceFuncs Package
-
MapReduce1.scala: Map class maps each log line from input file with the key as the log type with a value of 1 only if the log line falls within specified time interval from the config file and the log message contains the specified regex. The output of the map is then sent to the reduce class. The Reduce class condenses the counts. Output is shown below
-
MapReduce2.scala: Here we are running 2 map reduce jobs. First job takes all log lines within 1 second intervals that are between the specified time intervals and counts the amount of ERROR messages. The Map class of the first job called "Map" simply parses each log line in the input file and removes the millisecond which becomes the key and the value is given a value of 1 only if the log message contains the specified regex and if the the time for that specific log line fits withing the specified time interval.
Output of that map would look something like:
00:47:05 1 00:47:05 1 00:47:05 1 00:47:06 1 00:47:06 1This means 3 messages of type ERROR fall within the specified time interval and contains the specified regex and is happened within the 1 second interval of 00:47:05. 2 of these happened within the 1 second interval of 00:47:06
The Reduce class for the first job called Reduce1 simply condenses it. The second job sorts the distribution by its count. We use a custom comparator class called SortComparator which takes input from a Map class and sorts by key. Therefore we need to swap the key and value from the first job since the count is what we are sorting by. So we have a Map class called Swap which makes the key the count and the value the time. Before that output is run through the reduce, it is run through the comparator which sorts it by descending order and also condenses the values with the key.
So the input to the reduce would look something like this
3 {00:47:05, 00:47:08} 2 {00:47:06, 00:47:09} 1 {00:47:07}The Reduce class called ReSwap, takes this as input and reswaps the key and value and also expand the values
-
MapReduce3.scala: This is simply the same as the first task, but does not have the conditions of the time interval and containing regex. The Mapper simply output a key that is the log type with a count of 1. The Reducer condeneses it.
-
MapReduce4.scala: The Map for this task takes each log line and produces a key of the log type and a value that is the number of characters in the log message. The Reducer determines the maximum message length for each log type. It does a reduce() with a function that pick the maximum of 2 entries.
-
- Application.scala Runs the map reduce jobs based on commmand line input which specifies which task to run and passes in the input/output paths to the task functions.
For Task 1 and 2 we hae specified the time interval to compute the distribution between is {00:47:04.911, 00:48:05.272} and the regex is ".[a-c]." which means the log message must contain any character between 'a' and 'c'. For task for the regex just searches for the letter i.
The time interval is {00:47:04.911, 00:48:05.272} which is actually the entire input file. I did this for simplicities sake, however and time interval can be anything as long as it exists within the input file.
The log file is generated using the program from this repository: https://github.com/0x1DOCD00D/CS441_Fall2022/tree/main/LogFileGenerator The generator uses a configuration that modifies the output of the generator. Some settings that were tweaked:
The message length that is generated is anywhere between 10 and 15 characters. Since for task 2, I chose an interval of 1 second and within each second I needed multiple ERROR messages to result in a meaningful computation for that task, I set DurationMinutes to only 1, but set a TimePeriod for every 5 milliseconds. This means ~200 log lines would be generated every second. For that same reason, I set the probability of logMessageType to be
error = [0, 0.5]
warn = [0.5, 0.6]
debug = [0.6, 0.7]
info = [0.7, 1]
This means there is a 50 percent chance the log message type is ERROR which would give us a more meaningful output for task 2.
Task 2 output has been cutoff here as it is large. Full output can be found here
Task 1:

Task 2:
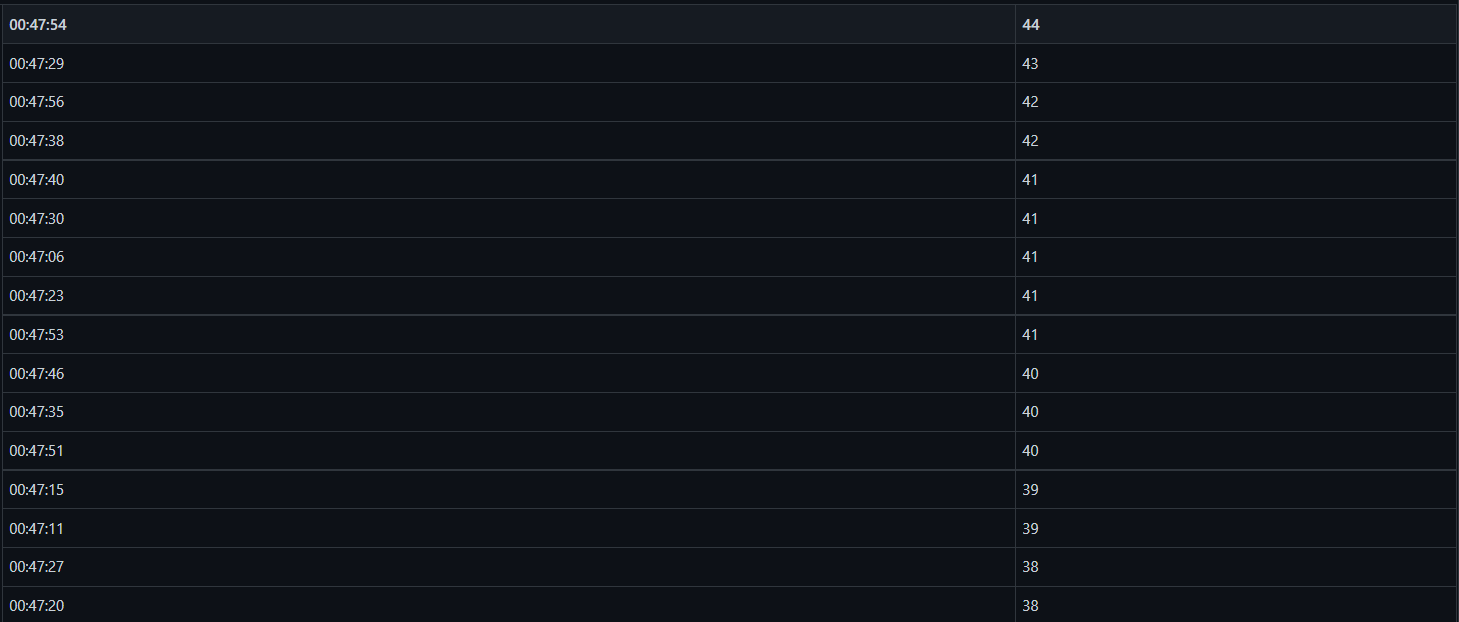
Task 3:

Task 4:

-
The csv file cannot be created on AWS EMR since converting the file to csv requires the unix command cat, which could not be implemented as an extrta step. With hadoop you have to expost it to a local filesystem to be able to open it with excel.
-
Opening the csv file in excel does not seperate keys and values into 2 columns. However if you were to run the tasks and convert using 'cat' without the line
conf1.set("mapreduce.output.textoutputformat.separator", ", ")Then it would, but it would not be a proper csv file. -
The interval was chosen to be 1 second for task 2 however choosing a larger interval would require some additional computation.
-
As mentioned above output folder should not be present when running the tasks.
-
There is no way to run a jar from the directly from the hadoop filesystem since the jar is maintains the project structure and paths. This is why we inputted the local file path of the jar when runnning the jar on hadoop.