음원에 나와있는 가사 텍스트 데이터를 통해
가사 텍스트에서 느껴지는 감정 정도를 분석합니다.

논문 출간 : 2022년 한국컴퓨터정보학회 하계학술대회 논문집 제30권 2호
https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE11140455
- 9가지의 감정 라벨로 분류
- 사랑(love)
- 즐거움(fun)
- 열정(enthusiasm)
- 행복(happyness)
- 슬픔(sadness)
- 분노(anger)
- 외로움(lonely)
- 그리움(logging)
- 두려움(fear)
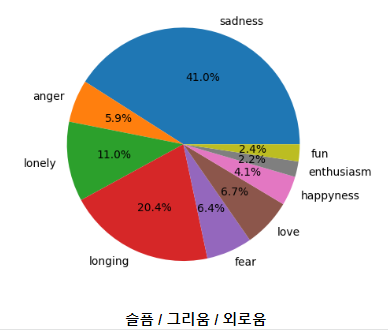
-SG워너비 살다가
'나로 인한 슬픔으로 후련할 때까지', '살아도 사는게 아니래', '사랑해도 말 못 했던 나', '나 잠이 드는 순간조차 그리웠었지', '눈물나니까', '살다가', '나 살다가', '너 없는 하늘에 창없는 암흑같아서', '웃어도 웃는게 아니래', '남김없이 태워도 되', '정 힘들면 단 한번만 기억하겠니', '우린 마지못해 살아가겠지', '내색조차 할 수 없던 나', '후련할 때까지', '태워도 태워도 태워도 남았다면', '울다가 울다가 울다가 너 지칠때', '살다가 살다가 살다가 너 힘들때', '우린 마지못해 웃는거겠지', '초라해 보이고 우는거 같아보인데
- 감정 연구의 대가 'Ekman'이 정의한 인간이 느낄 수 있는 가장 필수적이며 대표적인 감정 6가지를 바탕으로 함.( 행복 , 분노 , 슬픔 , 혐오 , 놀람 , 두려움 )
- 위 6가지 감정에서 텍스트로 표현될 수 없는 단어는 제거
'놀람'의 경우 ,텍스트에서 느껴지는 감정 보다는 표정으로 판단하는 경우가 많고 , 가사에 잘 등장하지 않는 감정 - 비슷한 감정 묶음 ('혐오' , '분노')
- 특정 장르 가사에서 자주 등장하는 감정 추가
'열정'의 경우 랩/힙합 장르에서 자주 등장하는 감정이기 때문에 추가
'그리움','외로움'의 경우 슬픈 발라드 장르에서 자주 등장하는 감정이기 때문에 추가
'즐거움'의 경우 댄스 장르에서 자주 등장하는 감정이기 때문에 추가
가사 문장을 직접 라벨링하면서 등장 빈도를 고려하여 최종 9가지의 감정으로 선정하였다.
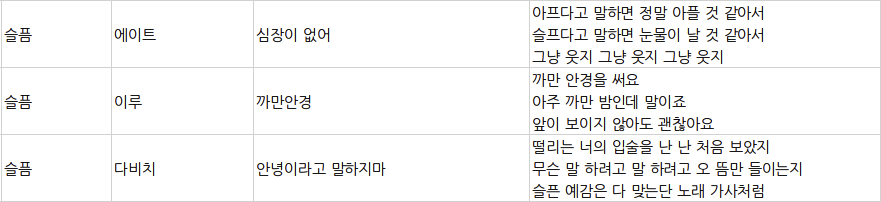
총 15,327개의 소절 단위 가사 라벨링 데이터 셋
(1).가사를 문장 토큰화한 데이터 셋 : 8723 문장
- 문서(가사) -> 문장(소절)
- 문장(소절)에 대한 라벨링 진행 *감정이 느껴지지 않는 소절 제외 ex) 니가 없어서 정말 슬픈걸 : sadness

(2). 가사 전체를 문장화한 데이터 셋 : 180곡 -> 6624 문장
- 가사에 대한 감정 라벨링 -> 문장 토큰화 ex) SG워너비 - 살다가 : 슬픔 ( '살다가'음원에 나온 가사 문장들은 전부 슬픔으로 라벨링 )
뉴스 기사 카테고리 분류 처럼 가사 전체를 가지고 감정 분류를 진행할 수 있다. 하지만 가사 전체를 사용하지 않고 문장(소절)로 나누어서 그 결과를 합산하는 방법을 채택했고 그 이유는 다음과 같다.
- 가사에서 느껴지는 감정은 한 가지가 될 수 없다. (가사에서는 여러가지 감정이 느껴진다.)
- 가사는 뉴스처럼 서로 다른 클래스들과 차이가 크지 않다.(뉴스 기사 보다 특징이 뚜렷하지 않다.)
- 한 가사에 여러라벨을 붙이면 어떤 감정이 가장 크게 느껴지는지에 대한 순위를 알 수 없다.
- 한 가사에 여러라벨이 붙는 다면 학습하기(지도학습)가 매우 어렵다.
- 문장(소절)단위로 쪼개서 합산하는 방법은 오분류률을 낮출 수 있다. *잘못분류해도 가사에는 여러문장이 있어 영향이 크지 않다. ( 가사 당 평균 33개의 문장 )
*실제로 가사 전체로 분류를 시도해보았지만 성능측면에서 문장(소절)으로 나누고 결과를 합산한 모델의 정확도가 더 높았습니다.
한국어 가사 감정 분류 방법론 : https://github.com/alswhddh/lyrics_emotion_analysis/tree/main/korean
- 6가지의 감정 라벨로 분류
- 놀람(Surprise)
- 사랑(love)
- 행복(happyness)
- 슬픔(sadness)
- 분노(anger)
- 두려움(fear)
영어의 경우 직접라벨링 하지 않고 kaggle에 있는 데이터 셋을 가지고 진행하였습니다.
(1). Emotion Detection from Text : 총 40000개의 트위터 감정 데이터
출처:https://www.kaggle.com/pashupatigupta/emotion-detection-from-text
트위터 데이터 셋 감정 라벨
- 총 13가지로 놀람,사랑,재밌는,열정,걱정,무감정,슬픔,화남, 싫은,행복,지루한,편안함,공허함
(2). Emotion dataset for NLP : 총 21000개의 평서문 감정 데이터
출처:https://www.kaggle.com/praveengovi/emotions-dataset-for-nlp
평서문 데이터 셋 감정 라벨
- 총 6가지로 놀람 , 사랑 , 즐거움 , 슬픔 , 화남, 두려움
장점:
- 직접 영어 가사 라벨링을 하지않고 많은 양의 데이터를 확보할 수 있음.
단점 :
- 두 가지 데이터 셋 모두 한국어 처럼 가사도메인 데이터가 아님.
- 데이터 불균형이 심함
- 두 가지가 동일한 라벨을 가지고 있지 않음.
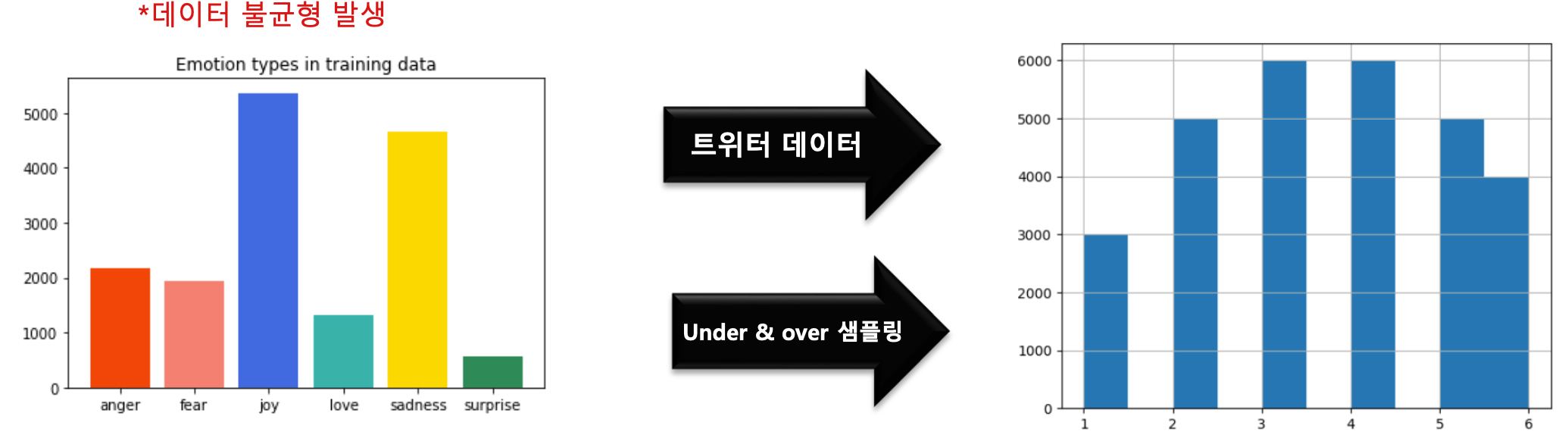
평서문 데이터 셋에 트위터 데이터 셋에 데이터를 추가하여 불균형 문제를 완화하고 라벨을 6가지로 고정함.
영어 가사 감정 분류 방법론 : https://github.com/alswhddh/lyrics_emotion_analysis/tree/main/english
감정 분류 방법에는 크게 두 가지로 나뉩니다.
여기서 각각의 자세한 방법론에 대한 설명은 하지 않습니다. *밑에 블로그 자료 참고
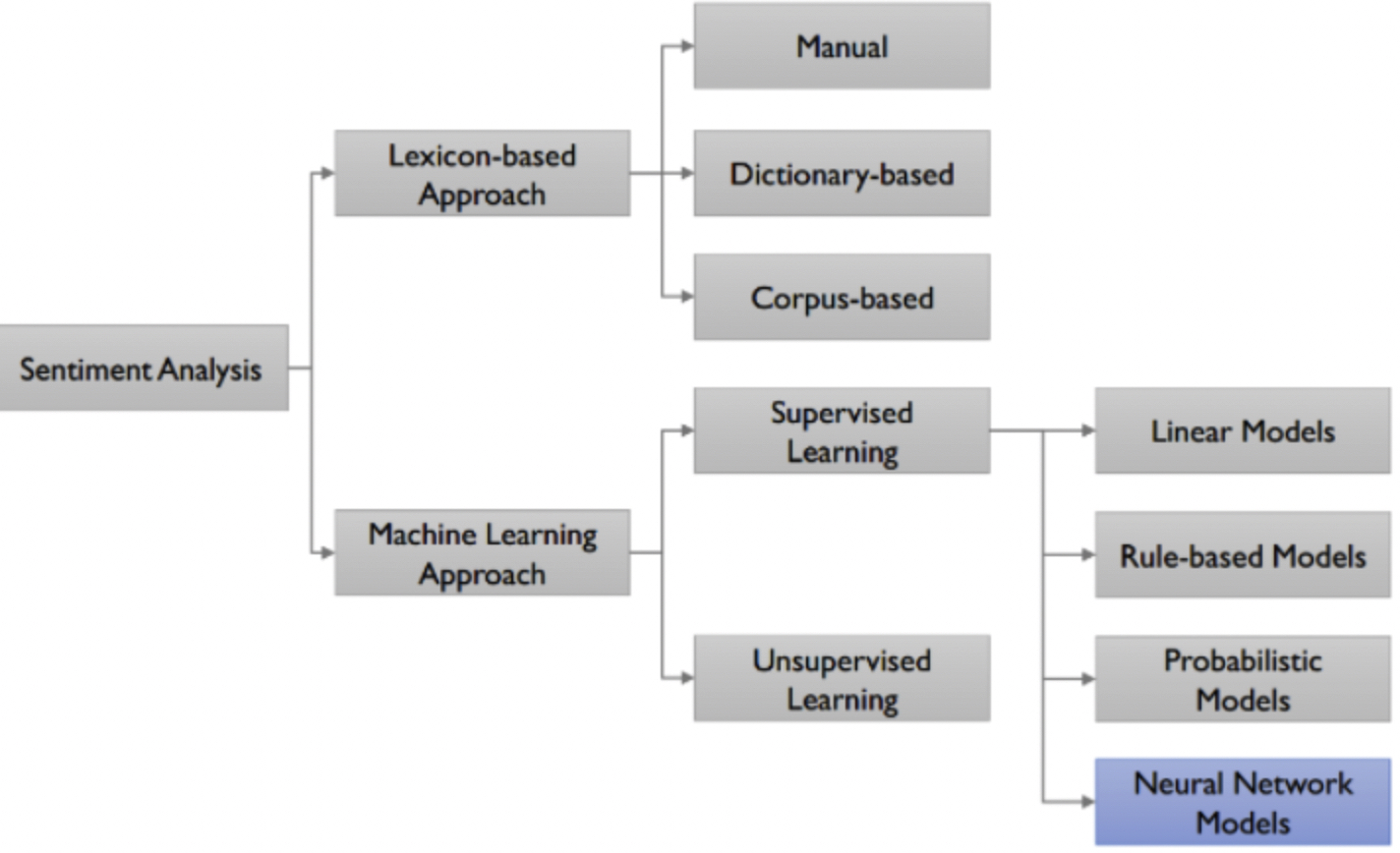
Corpus-based ( 말뭉치 기반 감정 사전 구축 방법 )
- 말뭉치에 맞는 적절한 감성 어휘를 재구축하는 말뭉치 기반 접근 방법
- 도메인 의존성을 극복할 수 있다.
- 좋은 사전 구축을 위해서 많은 데이터(거대한 말뭉치)를 필요로 함.
가사(말뭉치)들을 사용하여 가사 도메인에 맞는 감정 단어 사전을 구축하면 감정 분석을 진행할 수 있다.
단점: 등장 단어들을 구축한 사전에 대입시켜서 감정 분석을 진행하는 것이기 때문에 순서와 문맥을 전혀 고려하지 않는다.
예를 들면
'좋아하는 사람과 만날 수 없네요' 라는 문장은 '슬픔'에 대한 가사지만 사전기반으로 분석한다면
'좋아한다' , '사람' , '만나다' , '없다' 이렇게 분석되기 때문에 '사랑'으로 분류할 확률이 높다.
반어법/부정어 에 대해 대처할 방법이 없다.
Neural Network ( 딥러닝 기반 감정 분석 )
- 딥러닝 기반 문장 다중 분류(multi class)학습을 진행하면 문제를 해결 할 수 있음.
- RNN , LSTM , CNN , BERT 와 같은 지도학습 모델들이 이미 존재함.
- 단어의 순서를 고려하고 전체적인 문맥을 고려함.
단점 :특징 찾아내서 분류하기 때문에 비슷한 세부 감정을 분류할 때 정확도가 많이 떨어짐.
머신러닝 모델은 '사랑'과 '슬픔'은 잘 구분하지만 '사랑'과 '즐거움'에 대한 분류 정확도가 많이 떨어짐
*15000개의 문장 데이터로 BERT 다중 분류 학습(9개의 감정 클래스)을 진행했을 때 40%의 정확도를 보였음.