
AgentCore is a C++20 graph execution engine with a compact Python API for workflows that need explicit state, persistent subgraphs, structured memory, replay-oriented metadata, MCP interoperability, and OpenTelemetry hooks.



Install · Quick Start · Python Guide · API Reference · Benchmarks · Design Lineage · Docs
AgentCore is designed for graph-shaped agent systems where latency, durability, and state visibility matter at the same time. You describe a workflow as nodes and edges. Nodes return small state patches. The runtime commits those patches, routes to the next node, records trace/checkpoint metadata, and can resume or inspect the run later.
The Python surface is intentionally familiar: define a StateGraph, add nodes and edges, compile it, and invoke it. Underneath that surface, graph metadata, state commits, scheduling, checkpointing, message merging, persistent subgraph sessions, knowledge-graph reads, and supported intelligence/context queries run through the native runtime.
AgentCore is an independent project. It is not affiliated with Amazon Web Services, AWS AgentCore, or any related AWS-branded product or service.
AgentCore is useful when you want:
- a
StateGraph-style API backed by a native execution kernel - explicit state patches instead of hidden mutation of shared workflow state
- persistent child graph sessions for specialist agents, reusable tools, or long-running branches
- stream, trace, checkpoint, and replay metadata from the same execution path
- structured memory through tasks, claims, evidence, decisions, memories, and knowledge triples
- integration points for model adapters, tool adapters, MCP servers, graph stores, and OpenTelemetry
It is not trying to be a full agent application framework. It does not choose prompts, tools, models, vector databases, or UI patterns for you. It gives those pieces a deterministic graph runtime to sit on.
| I want to try it | Install, then follow the quick start or the full Python guide. |
| I have existing graph code | Use the migration guide for builder patterns, reducers, message state, and current compatibility notes. |
| I want the mental model | Read the runtime model for state patches, scheduler behavior, checkpointing, sessions, intelligence records, and knowledge-graph state. |
| I want the ideas behind it | Read design lineage and related work for the systems, retrieval, graph, and observability ideas AgentCore builds on. |
| I need integrations | See MCP, graph stores, OpenTelemetry, and the API reference. |
| I want to validate performance | Use the validation guide and current benchmark notes. |
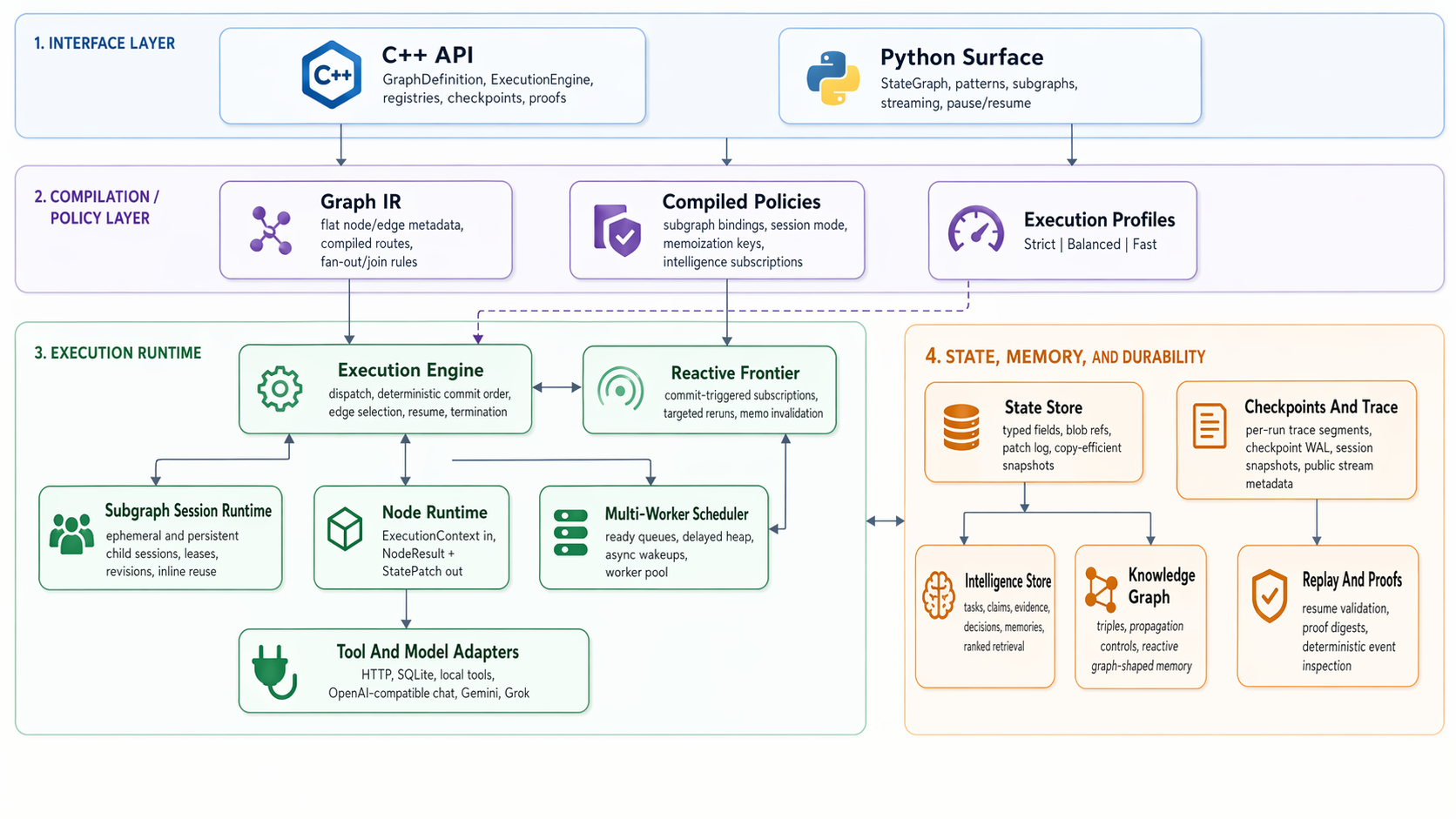
Many agent workflows start simple and then become expensive in the wrong places. Message history grows. Branches join. Tools wait. Specialist subgraphs need memory. A run needs to be streamed, resumed, audited, or replayed. If those concerns are bolted on later, the workflow often becomes hard to reason about.
AgentCore keeps those concerns in one runtime model. The engine is deliberately small: execute a node, apply a patch, choose edges, schedule work, checkpoint, and continue or stop. More specialized behavior lives at the graph, node, adapter, context, and memory layers.
The core design choices are:
- compiled graph metadata instead of ad hoc per-step graph interpretation
- explicit state patches instead of hidden shared mutation
- typed hot state plus blob references for larger payloads
- deterministic commit ordering for branches, joins, checkpoints, and replay
- persistent child sessions for reusable subgraphs without shared mutable child state
- native knowledge-graph and intelligence records for workflows that need structured context
- opt-in observability and durability profiles so metadata does not always dominate the hot path
- lazy public streaming and in-place structured-state ingestion so streamed and knowledge-heavy runs avoid unnecessary copies where possible
The result is a runtime that is easier to inspect than a pile of callbacks, but still small enough to embed in a larger system.
For most Python users:
python3 -m pip install agentcore-graphThe package published to PyPI is agentcore-graph; the Python import package is agentcore.
Optional extras:
python3 -m pip install "agentcore-graph[otel]"
python3 -m pip install "agentcore-graph[neo4j]"The package also installs MCP helper commands that can be used after installation:
agentcore-mcp
agentcore-mcp-server
agentcore-mcp-configCurrent published wheels target Linux x86_64 for CPython 3.9 through 3.12. Source builds remain available from this repository for other environments.
from agentcore.graph import END, START, StateGraph
def step(state, config):
return {"count": int(state.get("count", 0)) + 1}
def route(state, config):
return END if state["count"] >= 3 else "step"
graph = StateGraph(dict, name="counter", worker_count=2)
graph.add_node("step", step)
graph.add_edge(START, "step")
graph.add_conditional_edges("step", route, {END: END, "step": "step"})
compiled = graph.compile()
final_state = compiled.invoke({"count": 0})
print(final_state["count"])The important habit is that nodes return patches:
return {"count": state["count"] + 1}They do not mutate a global state object directly. That is what makes checkpointing, replay, joins, streaming metadata, and persistent sessions easier to reason about.
From the same compiled graph you can also stream events, inspect metadata, pause and resume, register tools and models, mirror MCP tools, emit OpenTelemetry spans, and compose persistent subgraphs.
Useful next reads:
AgentCore currently includes these working surfaces:
- native C++ runtime with Python bindings
StateGraph-style Python builder with conditional edges, joins, subgraphs, streaming, batch execution, and pause/resume- native schema reducers for sequential steps and joins, including list concatenation and ID-aware message history merging
- multi-worker scheduling with async wait handling
- checkpointing, trace events, proof digests, and replay-oriented metadata
- persistent subgraph sessions with isolated child state and deterministic session revisions
- structured intelligence state for tasks, claims, evidence, decisions, and memories
- graph-native context assembly from messages, intelligence records, native knowledge-graph triples, and state fields, with a native context-graph ranking path for intelligence and knowledge selectors
- knowledge-graph-backed state, in-place structured ingestion, indexed matching, and reactive execution hooks
- external graph-store hydration with an in-memory reference backend and optional Neo4j adapter
- deterministic memoization for supported pure nodes
- prompt templates for text, chat, and MCP-rendered prompts
- tool and model registries with built-in HTTP JSON, SQLite-style, local model, OpenAI-compatible, xAI Grok, and Gemini adapters
- MCP over
stdio, including tools, prompts, resources, completions, roots, sampling, elicitation, logging, subscriptions, and installable MCP server launchers - opt-in OpenTelemetry spans and metrics
- native and Python benchmark and smoke-test coverage
The project is still young. The core runtime, Python graph builder, persistent sessions, context/intelligence state, MCP helpers, graph-store interfaces, and benchmark surfaces are implemented, but the surrounding ecosystem is intentionally smaller than mature Python-first agent frameworks. Expect the API to keep getting smoother while preserving the explicit-patch runtime model.
Agent workflows often keep conversation history in a messages field. AgentCore exposes MessagesState and add_messages so message joins can run in the native merge path: messages with matching non-empty id values replace earlier messages in place, while messages without ids append.
from agentcore.graph import MessagesState, StateGraph
class AgentState(MessagesState, total=False):
summary: str
graph = StateGraph(AgentState, name="agent", worker_count=4)See the Python quickstart and API reference.
Persistent subgraph sessions let the same child graph run across many session_id values with isolated child state, checkpoints, task journal, knowledge graph, and stream metadata. This is useful for specialist agents, per-user memory, repeated tool workflows, or any child graph that should remember its own local state without sharing mutable state with other sessions.
Distinct sessions can run concurrently. Concurrent reuse of the same session is rejected deterministically instead of being merged implicitly.
See the runtime model and Python quickstart.
Nodes can declare a ContextSpec and then call runtime.context.view() to assemble a deterministic context view from message history, intelligence records, native knowledge-graph triples, selected state fields, and optional graph-shaped state carried by the workflow.
For intelligence and knowledge selectors, AgentCore compiles the request into a native context-graph query plan, ranks connected task/claim/evidence/decision/memory/triple records with deterministic activation scoring, and returns a kind-balanced top-k. The Python context graph remains as a compatibility fallback and as the final merge layer when a view also includes message or arbitrary state selectors.
The returned ContextView includes citations, provenance, budget stats, conflict metadata, prompt/message rendering helpers, and a stable digest that is surfaced through invoke_with_metadata(...).
from agentcore.graph import ContextSpec
graph.add_node(
"answer",
answer,
context=ContextSpec(
goal_key="question",
include=["messages.recent", "claims.supported", "evidence.relevant"],
budget_tokens=2400,
require_citations=True,
),
)
def answer(state, config, runtime):
context = runtime.context.view()
prompt = context.to_prompt(system="Answer using cited evidence.")
result = runtime.invoke_model("default", prompt, decode="text")
return {"answer": result, "context_digest": context.digest}See the Python quickstart and runtime model.
The intelligence layer stores operational records inside runtime state. It is meant for workflow-relevant structure that should be inspectable and replayable:
- tasks
- claims
- evidence
- decisions
- memories
Python nodes use runtime.intelligence to write and query those records. The records participate in normal patch commits, checkpoints, replay, and persistent subgraph sessions, so they can be used as durable context rather than side-channel memory.
def analyze(state, config, runtime):
runtime.intelligence.upsert_task(
"triage",
title="Triage incoming request",
owner="planner",
status="in_progress",
priority=5,
)
runtime.intelligence.upsert_claim(
"needs-followup",
subject="request",
relation="requires",
object="followup",
confidence=0.72,
)
next_task = runtime.intelligence.next_task(owner="planner")
return {"next_task": None if next_task is None else next_task["key"]}See the runtime model and Python guide.
Native knowledge-graph state is useful during execution because it participates in patches, checkpoints, context assembly, and replay. When the source of truth lives elsewhere, AgentCore lets a node explicitly hydrate runtime knowledge from a registered graph store, then optionally sync selected runtime triples back out.
from agentcore.graph import END, START, StateGraph
def retrieve(state, config, runtime):
loaded = runtime.knowledge.load_neighborhood(
"Incident",
store="ops_graph",
depth=2,
limit=20,
)
return {"loaded_triples": len(loaded["triples"])}
graph = StateGraph(dict, name="ops_graph_demo")
graph.add_node("retrieve", retrieve)
graph.add_edge(START, "retrieve")
graph.add_edge("retrieve", END)
compiled = graph.compile()
compiled.graph_stores.register_memory(
"ops_graph",
triples=[("Incident", "affects", "checkout API")],
)The first shipped backends are InMemoryGraphStore and Neo4jGraphStore. The connector contract is intentionally entity/triple/neighborhood based so other graph databases can implement the same surface without changing the runtime or graph API.
The Neo4j adapter has an optional live Docker validation path in addition to the default dependency-free graph-store smoke test. That path exercises batch writes, neighborhood reads, filtered queries, runtime hydration, context assembly, and sync-back persistence against a real Neo4j process.
See the graph-store integration guide, Python guide, and runtime model.
AgentCore can consume MCP servers and expose AgentCore-owned tools, prompts, resources, and graph surfaces through MCP. This is useful when you want the runtime to sit inside an existing tool ecosystem instead of forcing everything through one adapter style.
compiled.tools.register_mcp_stdio(
["python3", "./my_mcp_server.py"],
prefix="remote",
)Installed helper commands can also produce client configuration snippets for common MCP clients:
agentcore-mcp-config claude --name local-agentcore --target ./server.py:build_server
agentcore-mcp-config codex --name local-agentcore --target ./server.py:build_server
agentcore-mcp-config gemini --name local-agentcore --target ./server.py:build_serverSee the MCP integration guide.
Telemetry is opt-in. Passing telemetry=True or an OpenTelemetryObserver emits run spans, optional node spans, and run/node metrics using the Python OpenTelemetry API.
from agentcore.observability import OpenTelemetryObserver
observer = OpenTelemetryObserver()
details = compiled.invoke_with_metadata({"count": 0}, telemetry=observer)See the OpenTelemetry guide.
AgentCore's performance work is focused on places where graph runtimes often pay recurring overhead: graph dispatch, branch/join bookkeeping, persistent subgraph sessions, resume behavior, context retrieval, public streaming, and structured state operations.
The public head-to-head snapshot in this repository was refreshed on April 29, 2026 from a release-perf build. On that machine and workload set, AgentCore's compatibility surface was about 18.44x to 28.43x faster on the same-code builder path, while native persistent-session workloads were about 21.75x to 25.43x faster with lower measured memory use. Treat those as workload-specific measurements, not universal claims.
AgentCore-native regression benchmarks are tracked separately from head-to-head framework comparisons. Those cover native context-graph ranking, deterministic memoization, recorded effects, persistent-session replay, stream read cost, and knowledge ingestion through knowledge_ingest_* counters. This keeps feature-specific performance work tied to structural invariants such as equal final state, expected session counts, replay/proof checks, and exact knowledge lookup after ingest.
The exact commands and environment details live in the comparison document and validation guide. For local validation, start with:
ctest --test-dir build --output-on-failure
AGENTCORE_BUILD_PYTHON_ROOT=./build/release-perf/python python3 python/benchmarks/langgraph_head_to_head.pySee the validation guide for release, sanitizer, replay, and benchmark commands.
AgentCore is an implementation project, not a research paper. Its design is influenced by graph processing, dataflow systems, event-sourced state, retrieval-augmented generation, graph-shaped retrieval, context graphs, agent memory work, reactive pattern matching, and observability standards.
The short version is:
- graph execution and durable progress draw from systems such as Pregel, Beam/Dataflow, and event-sourced state
- reducer and join semantics draw from associative reduction patterns common in dataflow and batch-processing systems
- agent loops and structured memory are informed by ReAct-style reasoning/action flows and Reflexion-style feedback-memory work
- context assembly and knowledge ingestion are informed by RAG, GraphRAG, context-graph thinking, and older spreading-activation ideas over semantic networks
- reactive scheduling, memoization, and context caching borrow from compiled matching and incremental-computation traditions
See Design Lineage And Related Work for links and a more careful mapping between those ideas and what AgentCore actually implements.
For a normal local build, use CMake directly:
cmake -S . -B build
cmake --build build -j
ctest --test-dir build --output-on-failureFor optimized validation and benchmarks, use the release-perf preset:
cmake --preset release-perf
cmake --build --preset release-perf -j
ctest --preset release-perf
./build/release-perf/agentcore_runtime_benchmark
./build/release-perf/agentcore_persistent_subgraph_session_benchmarkThe repository also includes relwithdebinfo-perf, asan, ubsan, and tsan presets.
The main docs index is docs/README.md. If you are new, start with the Python guide or runtime model first; the reference pages are better once you already know the basic shape.
| Area | Document |
|---|---|
| Python workflow authoring | docs/quickstarts/python.md |
| Native C++ embedding | docs/quickstarts/cpp.md |
| Runtime semantics | docs/concepts/runtime-model.md |
| Design lineage and related work | docs/concepts/design-lineage.md |
| Python and C++ API surface | docs/reference/api.md |
| MCP integration | docs/integrations/mcp.md |
| Graph stores | docs/integrations/graph-stores.md |
| OpenTelemetry | docs/integrations/opentelemetry.md |
| Migration notes | docs/migration/langgraph-to-agentcore.md |
| Validation and benchmarks | docs/operations/validation.md |
| Head-to-head benchmark notes | docs/comparisons/langgraph-head-to-head.md |
agentcore/includeandagentcore/src: native runtimeagentcore/adapters: built-in tool and model adaptersagentcore/testsandagentcore/benchmarks: native tests and benchmark entry pointspython/agentcore: Python package layered over the native modulepython/testsandpython/benchmarks: Python smoke tests and benchmark entry pointsdocs: guides, concepts, reference material, migration notes, and validation docsassets: README and documentation images
AgentCore is independent and is not affiliated with or endorsed by LangChain Inc.
I am grateful to the projects, standards, and research communities that helped clarify the design space for graph-oriented agent runtimes:
- LangGraph and its documentation for making graph-based agent orchestration concrete and accessible
- NetworkX for graph-first modeling vocabulary
- Model Context Protocol for a practical interoperability layer for tools, prompts, and resources
- OpenTelemetry for the standard observability vocabulary AgentCore plugs into
The related systems and research references behind AgentCore's execution, retrieval, context, and observability choices are listed in Design Lineage And Related Work.
This repository is licensed under the MIT License. See LICENSE and NOTICE.