![]()
Mingde Yao1,5 Zhiyuan You1 King-Man Tam4 Menglu Wang3 Tianfan Xue1,2,5
1CUHK MMLab 2Shanghai AI Lab 3USTC 4Institute of Science Tokyo 5CPII InnoHK

One goal, one click, autonomous enhancement. PhotoAgent turns photos into professionally edited results through exploratory visual aesthetic planning — no step-by-step prompts required.
Traditional photo editing demands expertise, endless parameter tuning, and exhausting trial-and-error. PhotoAgent replaces this fragile human-in-the-loop pipeline with an autonomous agent-in-the-loop system — one that perceives, plans, executes, and evaluates like a seasoned professional.
| Feature | Description | |
|---|---|---|
| 🔄 | Closed-loop Planning | Perceive–plan–execute–evaluate cycle with action memory and visual feedback. No open-loop, single-shot edits. |
| 🌳 | MCTS-based Aesthetic Planner | Monte Carlo Tree Search explores editing trajectories, avoids short-sighted or irreversible decisions. |
| 🧠 | Action Memory & History | Full editing history prevents redundant operations, enables context-aware decisions and faster convergence. |
| 🎯 | Scene-Aware Classification | Fine-grained scene classification (portrait, landscape, urban, food, low-light, indoor) with scene-specific strategies. |
| 🛠 | Rich Toolset | Orchestrates GPT-Image-1, Flux.1 Kontext, Step1X-Edit, Nano Banana, ZImage, and more. |
| 📐 | UGC-Oriented Evaluation | UGC-Edit dataset (~7,000 photos) and reward model trained via GRPO on Qwen2.5-VL. |
PhotoAgent formulates autonomous image editing as a long-horizon decision-making problem with four core components in a closed-loop system:
┌──────────────────────────────────────────────────────────────┐
│ │
│ ┌───────────┐ ┌──────────┐ ┌──────────┐ ┌─────────────┐
│ │ Perceiver │───▶│ Planner │───▶│ Executor │───▶│ Evaluator │
│ │ (VLM) │ │ (MCTS) │ │ (Tools) │ │ (Metrics) │
│ └───────────┘ └──────────┘ └──────────┘ └──────┬──────┘
│ ▲ │
│ └──────────── memory + feedback ───────────────────┘
│ │
└──────────────────────────────────────────────────────────────┘
| Step | Component | What it does |
|---|---|---|
| 1 | Perceiver | VLM (Qwen3-VL) interprets the image and proposes K diverse, atomic editing actions |
| 2 | Planner | MCTS explores candidate actions via selection, expansion, simulation, and backpropagation |
| 3 | Executor | Runs selected actions with traditional or generative tools; retains the highest-scoring result |
| 4 | Evaluator | Ensemble of no-reference metrics, CLIP scores, and UGC reward model; drives re-planning when needed |
State-of-the-art on instruction adherence and visual quality; preferred in user studies.
| Input | Output | Input | Output |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
More results and interactive comparisons on the project page.
PhotoAgent refines images over multiple iterations, with each round building on the previous result:
 Original |
→ |  Iter 1: Color & tone |
→ |  Iter 2: Atmosphere |
→ |  Iter 3: Final polish |
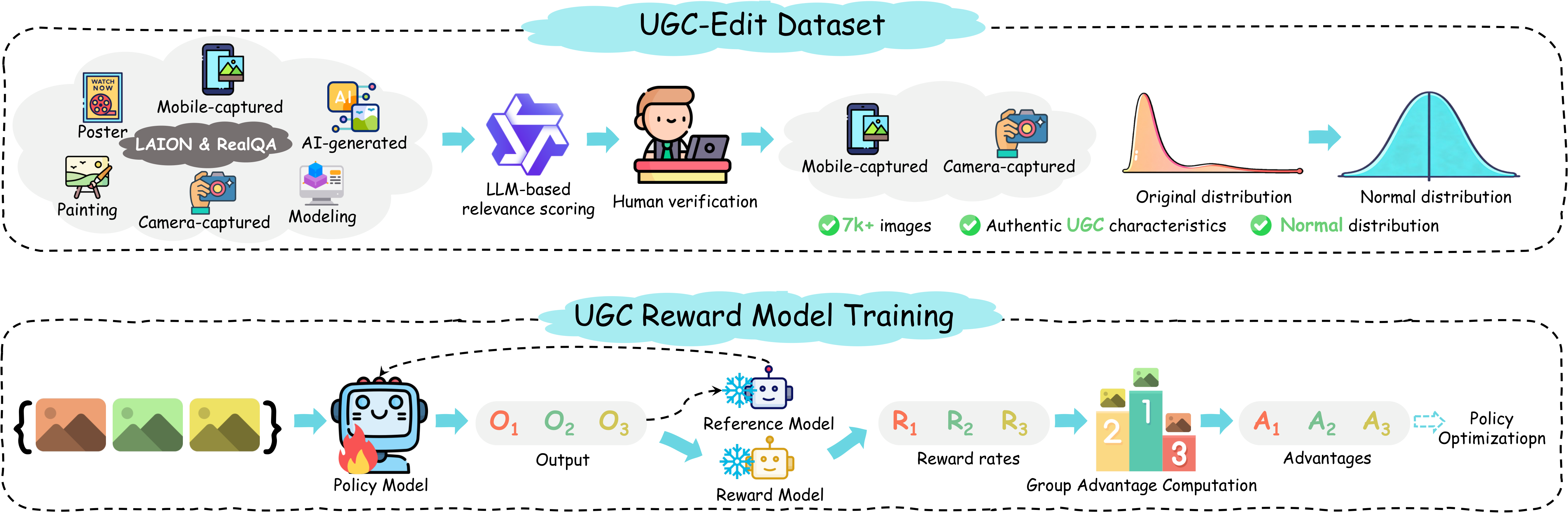
| Component | Details |
|---|---|
| UGC-Edit Dataset | ~7,000 authentic user-generated photos from LAION Aesthetic & RealQA, with human aesthetic scores (1–5 scale) |
| UGC Reward Model | Qwen2.5-VL fine-tuned with GRPO; learns from relative rankings for robust aesthetic scoring |
| Editing Benchmark | 1,017 real-world photos covering portraits, landscapes, urban scenes, food, low-light, and more |
Coming soon! Code, pretrained models, and demo will be released here. Star the repo to stay updated.
@article{yao2025photoagent,
title = {PhotoAgent: Agentic Photo Editing with Exploratory Visual Aesthetic Planning},
author = {Yao, Mingde and You, Zhiyuan and Tam, King-Man and Wang, Menglu and Xue, Tianfan},
year = {2025}
}This project is released under the MIT License.