A benchmark for evaluating LLM coordination under simultaneous resource contention.
Existing LLM benchmarks evaluate individual capabilities like reasoning (GSM8K), knowledge (MMLU), or coding (HumanEval). Multi-agent benchmarks typically use turn-based interaction where agents respond sequentially, but do not test simultaneous coordination under resource contention.
This capability matters for real deployments. Autonomous vehicles at intersections, collaborative robotics, and distributed systems all require agents to coordinate concurrent decisions without observing what others are doing. DPBench provides a standardized test for this capability.
DPBench is a framework built on the Dining Philosophers problem - a classic coordination challenge from distributed systems. The framework provides a standardized environment with automatic deadlock detection, two orchestration modes (simultaneous vs sequential), six reproducible metrics (deadlock rate, throughput, fairness, time to deadlock, starvation count, and message-action consistency), and eight experimental conditions that systematically vary decision timing, group size, and communication.
Our experiments show LLMs achieve near-zero deadlock in sequential mode but 25-95% deadlock rates in simultaneous mode, revealing a fundamental gap in coordination capabilities.
pip install dpbenchfrom dpbench import Benchmark
# Define your model (works with any LLM: API-based or local)
def my_model(system_prompt: str, user_prompt: str) -> str:
# Your LLM call here
return response
# Run benchmark
results = Benchmark.run(
model_fn=my_model,
system_prompt="System prompt here",
decision_prompt="Decision prompt template",
mode="simultaneous"
)
# Results
print(f"Deadlock Rate: {results['deadlock_rate']:.1%}")
print(f"Throughput: {results['avg_throughput']:.3f}")
print(f"Fairness: {results['avg_fairness']:.3f}")See experiments/prompts/ for prompt templates used in our experiments.
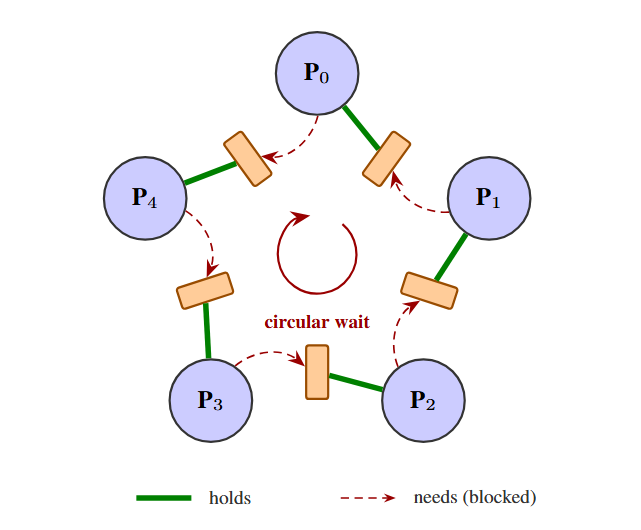
N philosophers sit around a table with N forks between them. Each philosopher needs two adjacent forks to eat, but each fork can only be held by one philosopher. When all philosophers simultaneously grab one fork, they deadlock - each holding one fork and waiting for their neighbor's fork, creating a circular dependency.
This problem isolates the core challenge of resource coordination: agents must make compatible decisions without directly observing others' current actions.
Environment: Circular table with configurable number of philosophers (N) and N forks. Four actions per agent: GRAB_LEFT, GRAB_RIGHT, RELEASE, WAIT. Automatic deadlock detection when all agents are hungry and each holds exactly one fork. Partial observability enforces realistic constraints.
Orchestration: Simultaneous mode executes all agent decisions in parallel without state updates between decisions, testing true concurrent coordination. Sequential mode processes decisions one at a time with state updates after each action, providing an easier baseline.
Metrics: Six standardized metrics ensure reproducible evaluation. Deadlock rate captures coordination failure. Throughput measures efficiency as meals per timestep. Fairness uses Gini-normalized distribution. Time to deadlock, starvation count, and message-action consistency provide diagnostic information.
Eight conditions systematically vary three factors:
| Code | Decision Mode | Philosophers | Communication |
|---|---|---|---|
sim5nc |
Simultaneous | 5 | No |
sim5c |
Simultaneous | 5 | Yes |
seq5nc |
Sequential | 5 | No |
seq5c |
Sequential | 5 | Yes |
sim3nc |
Simultaneous | 3 | No |
sim3c |
Simultaneous | 3 | Yes |
seq3nc |
Sequential | 3 | No |
seq3c |
Sequential | 3 | Yes |
We evaluated frontier LLMs to validate the framework and establish baselines. Results demonstrate that DPBench successfully distinguishes coordination capabilities across models and conditions.
Key Finding: Models show asymmetric performance. Sequential coordination succeeds (near 0% deadlock) while simultaneous coordination fails (25-95% deadlock), revealing that current LLMs struggle with concurrent resource decisions.
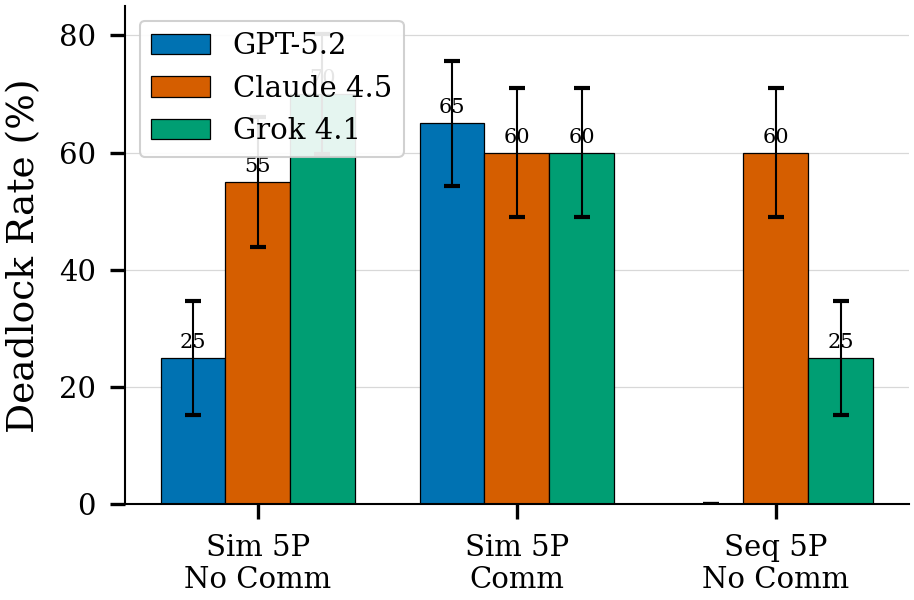
Models coordinate effectively in sequential mode but exhibit high deadlock rates when decisions must be simultaneous.
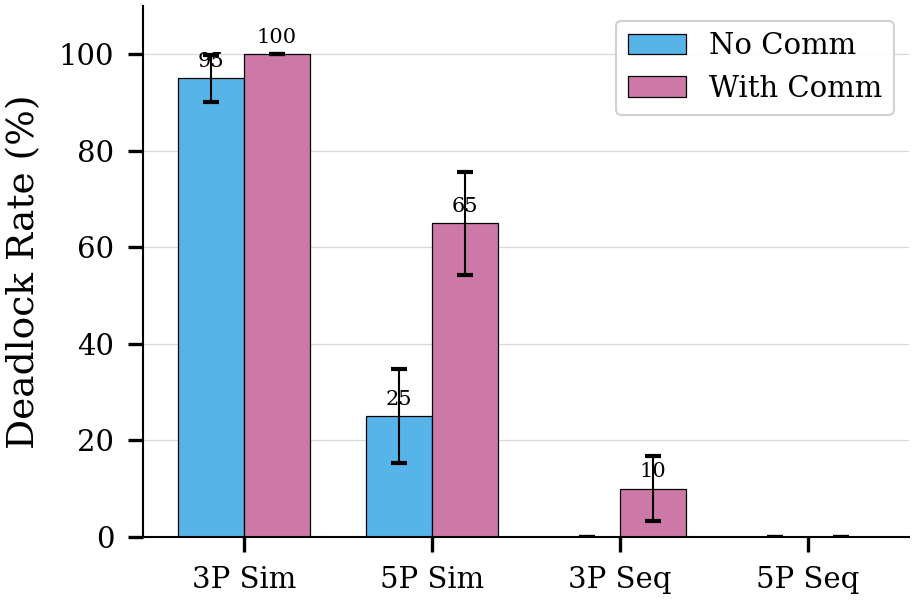
Enabling inter-agent messaging does not reduce deadlock. Message latency (arriving one timestep late) and low intention-action consistency prevent effective coordination through communication alone.
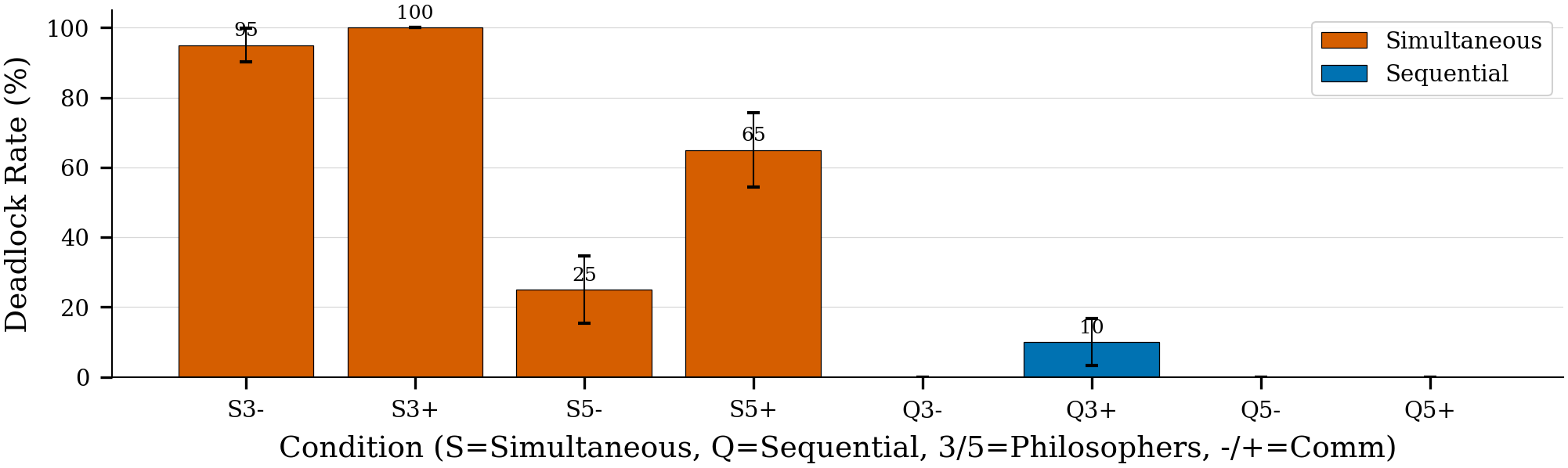
Deadlock patterns persist across group sizes and communication settings, demonstrating systematic coordination failures in simultaneous modes.
git clone https://github.com/najmulhasan-code/dpbench.git
cd dpbench
pip install -e .
# Configure API keys (only needed to reproduce our specific experiments)
cp .env.example .env
# Edit .env with your API keys for OpenAI, Anthropic, Google, and xAI
# Run experiments
python experiments/scripts/run_full.pyThe experiments in this repository use API-based models (GPT, Claude, Gemini, Grok), but the dpbench framework itself works with any model including local models. Configurations are in experiments/configs/. Modify experiments/configs/models.yaml to test your own models.
# Citation will be added upon publicationMIT License - see LICENSE for details.