Concepts
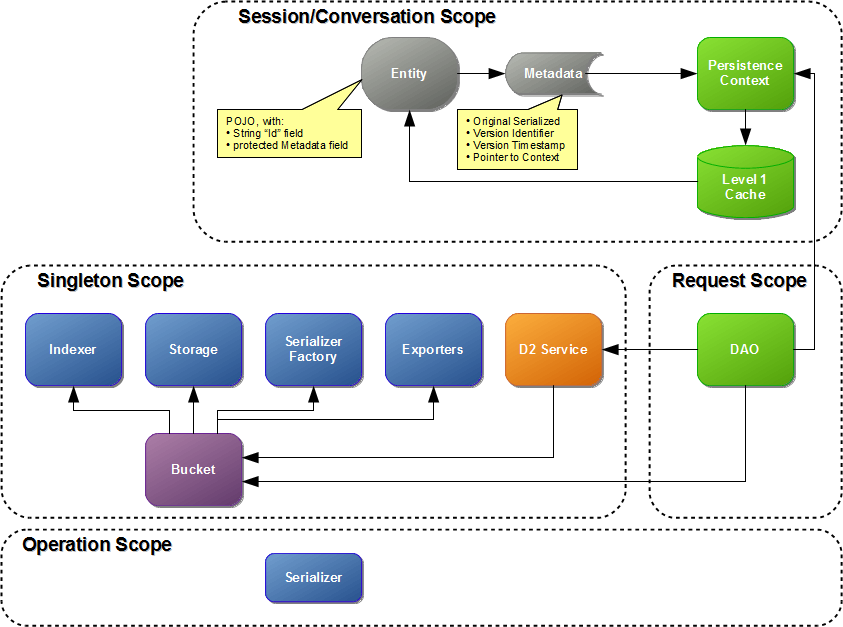
An entity is the smallest granularity of persistence in D2. In contrast with most other persistence systems, an entity does not correspond to a single object instance, but instead a corresponds to all of the data that is considered to be “wholly-owned” by the root object of the entity.
The concept of a “wholly owned” object is closely related to the “cascade delete” feature included in most ORM packages. If you would use “cascade” for a relationship, then it is likely that the relationship would occur within the boundaries of an entity and would not constitute the creation of a new entity.

Conceptually, whether or not a relationship constitutes a boundary between entities depends on whether the related object is “wholly owned” rather than on the multiplicity of the relationship. From the diagram above, you can see that some one-to-one relationships (such as Employee->Position) occur across entity boundaries, while others (such as Job->SalaryRange) occur within an entity. Compare also the one-to-many relationships of Employee->Paycheck and Paycheck->Deduction.
Practically, whether or not a relationship constitutes a boundary between entities depends on the Java class referenced. You will declare certain classes to be entity roots. Every instance of that class (or any subclass) constitutes the root level of an entity, and therefore defines an entity boundary. (In the future it may be possible to define specific relationships as “wholly owned” even if it refers to a class that is defined as an entity root. In the limited use of D2 thus far, we haven't yet needed this feature, so it has not been implemented.)
All entities of a certain type will be stored in a single bucket. The bucket determines the storage mechanism and indexing system that will be used for that entity. One D2 instance will contain multiple buckets, one for each type of entity that it can store. Only root level entities can be queried. All other (wholly-owned) objects are retrieved by first retrieving the associated root-level entity.
A storage mechanism in D2 is basically a key-value map. The object's identifier (unique within the bucket) is the key, and a serialized representation of the object is the value.
The storage mechanism must also support version history for the values of a key.
Optional features include:
- ACID compliance
- Row locking
- Multiple values (columns)
Because the storage mechanism can only find an entity by primary key, a separate indexer is required for querying the data store and locating entities. Although the indexer mechanism is pluggable, it must currently implement a query system very similar to Lucene. NOTE: This query system is subject to change and become more generalized as other indexing systems are added.
Each bucket has its own Storage System instance and its own Indexer instance. However, these separate instances could all refer to a single core instance... it all depends on the implementation and performance optimizations.
Also, although the indexer and storage systems can be completely separate from each other, this does not always need to be the case. One could depend on the other. For example, if Lucene is used as the indexer, you could also use a special storage system that stores the serialized data directly in the Lucene index. Similarly, if Hadoop Hbase is used for storage, an indexer that makes use of Hadoop's Hive processing and query system could theoretically be created.