Develop uft8 ver2#798
Conversation
… and mess up the database. Note: We do not need decode from thaw because as sequences of bytes nothing changes. (I think.)
…ch/webwork2 into locbug Conflicts: courses.dist/modelCourse/course.conf
… suggested by goehle
added [qw(Encode::Encoding)] to ${pg}{modules}) in defaults.config as…
…lop_uft8_ver2 # Conflicts: # lib/WeBWorK/ContentGenerator/Instructor/SendMail.pm # lib/WeBWorK/Utils.pm
|
Here are the changes I've made and the observations on how the question above works for me. changes made to develop to add localizationcreating develop_utf8_ver2
behaviorSome bulgarian characters
One other thing I noticed is that running the string through PG_restricted_eval(...) guarantees that it will print correctly, e.g. TEXT(PG_restricted_eval(...)); If anyone has insights into the PGML failure please respond. |
|
Bug squished!!!!! Adding use utf8; to WWSafe.pm fixed the behavior. Now to figure out exactly what it is I squished. It almost certainly involves $safe->reval(). Does anyone else who has been using characters beyond the ASCII character set have any insights or experiences to add with getting WeBWorK to work with an extended character set? |
|
Does this mean it now works with PGML properly, or do I have to look into that yet? |
|
It now works with PGML properly so you can take this off your agenda. I'm still puzzled as to why only PGML failed -- and why TEXT() succeeds before PGML is run but not afterward. It's partially related to the fact that PGML doesn't use PG_restricted_eval(). I'm going to test the configuration I have here more extensively and then I may try to figure out which extra "use utf8" pragmas were not needed. |
|
OK, sounds good. Thanks for figuring it out! |
|
I have merged this pull request on my develop branch and there is still some characters that are not showing correctly. I suspect a problem with mysql table. The charset was latin1_sweedish_ci on all the tables, but I changed some to utf8_general_ci for the course I was testing and restarted everything, and still, it's not showing correctly. This is the userList page : (the name is suppose to be Stéphane) This is the CourseTitle : (Portail d'aide étudiant) |

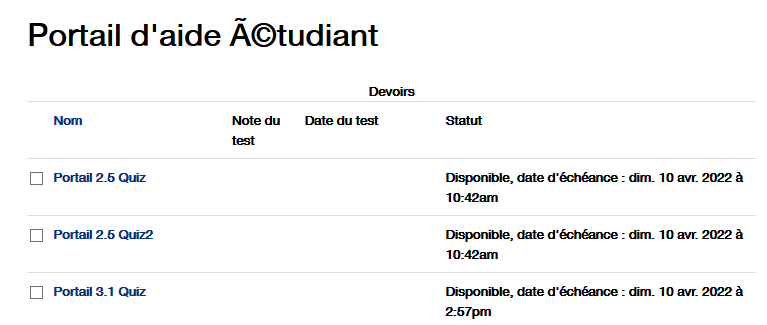
|
I still experience an encoding problem when the translation of the string |
|
@jutrembBDEB When I use utf8 for the MySQL tables, then titles of newly created courses and names of newly added students display correctly. I would suspect a conversion issue from latin1_sweedish_ci to utf8. |
|
I'm up against my deadline for packing for vacation so I'll be out of the loop for the next few weeks.
Keep reporting anomalies like that and we'll tackle them one by one. Jason Aubrey should be back from vacation soon. He can help pull suggested merges into develop. He can also give you access to the Transifex account if that is helpful. I'll be back around August 22. -- Mike |
|
Everything seems to work fine now when I create a new course. As Mike said, it's the existing courses that is the problem. I found another anomalie though. I added a extra library button in localOverrides file, it's call "Banque de problèmes libres". the characters doesn't show correctly in the SetMaker page. |
|
@mgage: Adding "use utf8;" at the top of the Authen.pm does not solve the problem I reported. |
|
@jutrembBDEB --I'll work on it when I get back if you guys haven't fixed it already Keep a list of things you find. There may be some things in your previous PR (which you have since withdrawn) that didn't get fixed in this current pull request -- please add them back in. @heiderich or @jutrembBDEB feel free to create to clone this branch on my site (mgage:develop_utf8_ver2 and create a ver3 with more fixes. We can review it together |
|
@heiderich : I found a solution to your problem : To the lib/WeBWorK/ContentGenerator/Login.pm file, at the begining of the file, you add and arround line 188, under the line you add this new line : It worked for me! |
|
Thank you @jutrembBDEB. This indeed fixes the problem. |
|
As proposed by @mgage I created a new pull request #800. I already added the fix proposed by @jutrembBDEB. |
|
There's seem to happen an extra conversion in utf8 with the commands addmessage and maketext. In the file ContentGenerator/Instructor/PGProblemEditor2.pm, some text that are called with a addgoodmessage or addmessage command have an "?" instead of an accent character : I tested this action called by the line 1833 : Here's what happened :
|

|
I found a solution for my previous problem with the question mark character. It was a problem with the escape handler call in the file PGProblemEditor2.pm. We have to replace all the I know that the file PGProblemEditor3.pm calls the uri_escape, but I don't know if there is other files and if we need to change everything to But for now, it solved my problem. |
|
I replaced uri_escape by uri_escape_utf8 in all of these files expect the first one, because I am not sure how it is used and if I understand it correctly, uri_escape is only applied to a base64 string there, which should not contain any non-ASCII characters. Or am I mistaken? I added a commit to my pull request #800 with these changes. |
|
I had an UTF8 problem with the simple.conf file that is saved when we modify the Config of a course. I have translated all the permission role in french and "nobody" is translated as "aucun rôle". So when I modified some options in the config that use "nobody", it's written in the simple.conf file. The problem happened when I changed the langage from french to english in the Config, the simple.conf that was saved didn't recognize the "ô" character. So, in the file lib/WeBWorK/ContentGenerator/Instructor/Config.pm, I changed the 490 line: There was also something else happening when I changed the langage from french to english. All the permission that was set to "aucun rôle", was modify as "guest" instead of "nobody". I found in the Config file the line responsible for that where there was missing a maketext call. Here's the section of the code I modified (line 248 to 251) I created a pull request on Heiderich develop_uft8_ver3 branch with these modifications. |
|
This pull request has been replaced by pull request PR #800 This still has good discussion of the issues. |
|
Closing this in favor of PR #800 |
This is experimental -- do not merge it yet. This is a summary of the the utf8 related changes I have made to get international characters to work. It has been successful to some extent and no longer fails on PGML material. The companion request for pg is #319.
It may well fail other test cases in which case I encourage you to report them to this pull request.
Here is a pg problem that can be used for initial testing. All of the bulgarian characters should
now appear properly.