![]()
A governed, time-aware fact-retrieval sidecar for RAG. Most retrievers
return whichever passage looks most lexically or semantically relevant,
even when the corpus contains the wrong-era fact (a 2010 passage about
Steve Jobs being returned for a 2024 question about Apple's CEO), the
competing fact (Reuters and Bloomberg disagreeing on the same number),
or the renamed entity (Twitter vs. X). nuggetindex sits next to
whatever retriever you already run and adds a thin governance layer that
catches all three: facts get a validity interval, source disagreements
get marked Contested, and a single CLI command lets a human pick
which source wins when two of them collide.
At ingest, nuggetindex extracts atomic facts from your documents,
attaches a [start, end) validity interval and provenance to each, and
detects when two of your sources commit incompatible objects on the
same (subject, predicate) key. At query time, it filters by the
question's time and surfaces source disagreements to the generator. No
re-indexing of your existing retriever required.
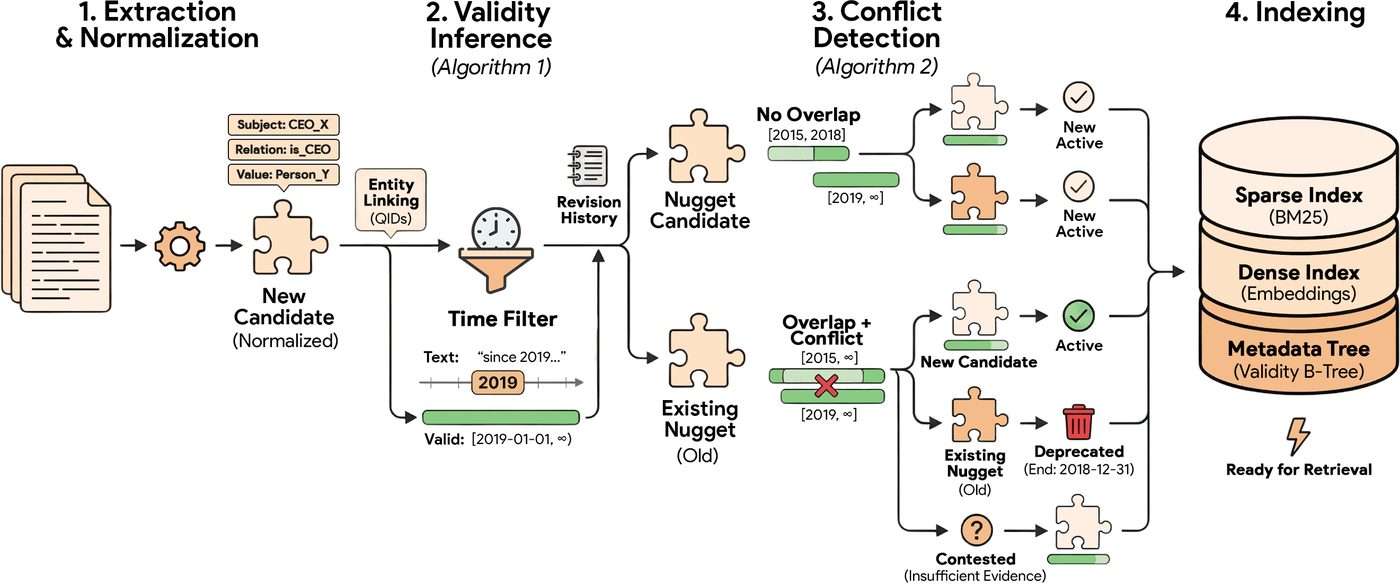
NuggetIndex pipeline. Raw text is normalised into atomic candidates. Algorithm 1 infers validity intervals using temporal expressions and revision history, while Algorithm 2 detects conflicts with the index to determine lifecycle states. Figure from the SIGIR 2026 paper (arXiv:2604.27306).
pip install nuggetindexThe smallest way to try nuggetindex on top of your existing RAG: one call against the passages your retriever already returned. No DB, no ingest, no setup.
from nuggetindex import audit
passages = my_retriever.run("Who is the CEO of Apple?", k=10)
report = audit(
query="Who is the CEO of Apple?",
passages=passages,
query_time="2010-06-01",
)
print(report.summary())
# -> 2 stale passages, 1 cross-source conflictThere are five ways to plug nuggetindex in. They are independent; start with whichever fits, and skip the rest.
Pass the passages your retriever just returned through audit(). You
get back a report of how many of them are stale at the question's
time, how many keys are contested across sources, and how many entity
renames the system spotted. No database is created.
from nuggetindex import audit
passages = my_retriever.run(query, k=10)
report = audit(query=query, passages=passages, query_time="2024-06-01")
print(report.summary())CLI equivalent on a JSONL file of passages:
nuggetindex audit passages.jsonl --query "..." --time 2024-06-01Insert GovernancePostProcessor between your retriever and your
generator. DEPRECATED passages drop out; CONTESTED ones get a
[DISPUTED] prefix that the generator sees in context. Your existing
retriever stays exactly as it is.
pip install "nuggetindex[langchain]" # or [llamaindex] / [haystack]from nuggetindex.integrations.langchain import GovernancePostProcessor
chain = my_retriever | GovernancePostProcessor() | my_prompt | my_llmIngest your documents once, query with a query_time. Hybrid BM25 +
optional dense fusion, validity-aware filtering, sub-millisecond
retrieval on a SQLite-only index.
from datetime import datetime, timezone
from nuggetindex import NuggetStore
from nuggetindex.extractors.clients.base import LLMConfig
from nuggetindex.extractors.llm import LLMExtractor
from nuggetindex.pipeline.constructor import Document
extractor = LLMExtractor(LLMConfig(provider="openai", model="gpt-4o-mini"))
store = NuggetStore(db_path="my_index.db", extractor=extractor)
for doc in my_corpus:
store.ingest(Document(
source_id=doc.id,
text=doc.text,
source_date=doc.published_at,
))
for r in store.retrieve(
"CEO Apple",
view="active_contested",
query_time=datetime(2010, 6, 1, tzinfo=timezone.utc),
):
print(r.nugget.fact.text, "->", r.nugget.epistemic.status)CLI equivalents:
nuggetindex build ./my_corpus_folder --db my_index.db
nuggetindex ingest --db my_index.db --doc some_new_doc.txt
nuggetindex query "CEO Apple" --db my_index.db --time 2010-06-01Once you have a store, five commands keep it honest as your corpus evolves.
| Command | What it does |
|---|---|
nuggetindex resolve --store my_index.db |
Walks every contested key in that store, shows you the rival objects with evidence and sources, and lets you pick which one wins. The chosen nugget becomes Active + Preferred; the losers become Deprecated. |
nuggetindex doctor --index my_index.db --mode fast |
Scorecards the store on temporal drift, conflict surface, and rename events. Fast mode is rule-based; deep mode reuses the full LLM pipeline. |
nuggetindex chain "Twitter Inc." --db my_index.db --kind rename |
Walks a temporal provenance chain (succession, rename, or join) for a subject. |
nuggetindex inspect --db my_index.db |
Dumps store statistics: nugget count by lifecycle state, distinct subjects, contested keys, etc. |
nuggetindex diff --a old.db --b new.db |
Diffs two stores: what was added, deprecated, or newly resolved. |
If your generator lives outside Python, expose the store over HTTP.
pip install "nuggetindex[serve]"
nuggetindex serve --db my_index.db --port 8080You get FastAPI endpoints for retrieval, audit, and the doctor scorecard.
Reach for nuggetindex when at least one of these is true:
- Your corpus has facts that change over time (CEO names, prices, model versions, regulations) and your retriever currently returns the freshest passage instead of the fact valid at the question's time.
- Your corpus has multiple sources that occasionally disagree, and you want the generator to know about the disagreement instead of silently picking one.
- Your stack has accumulated entity-rename drift (Twitter to X, Facebook to Meta) and the same entity now lives under two surface forms in your index.
Skip nuggetindex if your corpus is static and factoid-light, or if you're doing narrative / multi-hop retrieval where stitched context matters more than atomic facts.
Atomic facts are extracted at ingest time by an LLM. nuggetindex talks to OpenAI, Anthropic, Google, any OpenAI-compatible endpoint (vLLM, OpenRouter, ...), and Ollama for fully offline open-weight models. You point the extractor at one of them; the rest of the pipeline is identical.
from nuggetindex.extractors.clients.base import LLMConfig
from nuggetindex.extractors.llm import LLMExtractor
# Commercial (OpenAI)
LLMExtractor(LLMConfig(provider="openai", model="gpt-4o-mini"))
# Fully offline, free (Ollama on your laptop)
LLMExtractor(LLMConfig(provider="ollama", model="qwen3.5:32b"))
# Any OpenAI-compatible endpoint (e.g. self-hosted vLLM)
LLMExtractor(LLMConfig(
provider="openai_compat",
base_url="https://your-cluster/v1",
model="qwen3-next-80b-a3b-instruct",
))Three extractors reported in the SIGIR 2026 paper, on a 100-doc real-web-crawl benchmark:
| Model | Fact recovery | Latency / doc | Cost per 10k docs |
|---|---|---|---|
gpt-4o-mini (commercial) |
100% | 2.9s | ~$4.50 (vendor) |
qwen35-397b (open-weight, dense, reasoning) |
95% | 13.0s | — |
qwen3-next-80b-a3b-instruct (open-weight, MoE / 3B active) |
90% | 1.9s | — |
You do not need a frontier commercial model to run nuggetindex well.
Fact extraction is a strong suit of current open-weight LLMs: the
80B-MoE variant lands within five points of gpt-4o-mini and is
faster per document. And on the commercial side the absolute numbers
are modest — a one-time index build of a 10,000-document corpus with
gpt-4o-mini is around $4–5, and append-only ingest from there is
cheaper still.
A separate question is whether you would be better off hand-curating the facts. Our paper answers this directly: replace every LLM-extracted nugget with a human-annotated one across 500 test queries and downstream retrieval recall lifts by 3.7 percentage points; temporal correctness lifts by 4.5. The LLM extractor is already doing almost all of the work a human curator would.
Before committing to an extractor for your own corpus, preview the cost and wall-time:
nuggetindex estimate-cost my_corpus.jsonl \
--provider openai --model gpt-4o-miniThe full command surface, in alphabetical order. Each example shows a
realistic invocation and what it actually does to your filesystem,
your store, or your terminal. Run any command with --help for the
full option list.
nuggetindex audit passages.jsonl --query "CEO Apple" --time 2024-06-01Reads passages.jsonl (one passage per line, the output your
retriever just produced), runs the audit pipeline against the given
query time, and prints a scorecard: how many of those passages are
stale, how many (subject, predicate) keys are contested across
sources, how many entity-rename hits. No database is created or
modified.
nuggetindex auto --corpus-url https://search.example.com \
--corpus-name my-corpus --db out.dbEnd-to-end facade. Pulls a topic-diverse sample from the corpus
endpoint, runs schema discovery, proposes seed queries, ingests the
sampled documents into out.db, and prints the resulting sidecar
configuration so you can wire it into your retriever. Useful when
you want a one-command path from "I have a search endpoint" to
"I have a sidecar".
nuggetindex build ./my_corpus_folder --db my_index.dbWalks ./my_corpus_folder recursively, treats every .txt file as
a document, and ingests them into a fresh my_index.db. An
existing SQLite at that path is appended to, not overwritten.
nuggetindex chain "Twitter Inc." --db my_index.db --kind renameStarting from "Twitter Inc.", walks the chain of renamedTo /
formerlyKnownAs / corporateName edges in my_index.db and
prints the chain (Twitter Inc. -> X Corp., with dates and source
spans). --kind also accepts succession (CEO chains, etc.) and
join.
nuggetindex diff --a old.db --b new.dbCompares two store snapshots and prints what was added, what got
deprecated, and which keys went from contested to resolved between
them. Handy after a re-ingest or a resolve session to see exactly
what moved.
nuggetindex doctor --index my_index.db --mode fastScorecards my_index.db along four dimensions — temporal drift,
conflict surface, rename events, and validity-known rate — on a
stratified sample. Fast mode (rule-based, no LLM, finishes in
minutes) gives you a Wilson-CI estimate; --mode deep reuses the
full LLM pipeline for a tight bound at the cost of API calls.
nuggetindex estimate-cost my_corpus.jsonl \
--provider openai --model gpt-4o-miniScans my_corpus.jsonl (one document per line), counts tokens,
multiplies by the provider's published per-token rates, and prints
the projected dollar cost and wall-time before you commit to an
ingest run. No LLM calls are made.
nuggetindex eval timeqa --db my_index.db --baseline hybrid_passageRuns the named benchmark (e.g. timeqa, ravine, hotpotqa) twice
— once with your existing baseline retriever, once with the
nuggetindex sidecar in front of it — and prints recall, temporal
correctness, conflict rate, and a paired-bootstrap p-value for each
delta.
nuggetindex ingest --db my_index.db --doc some_new_doc.txtAppend-only. Adds some_new_doc.txt to an existing store without
re-extracting documents already there. Pass --doc multiple times,
or --folder to ingest everything in a directory.
nuggetindex inspect --db my_index.dbPrints a summary of the store: total nuggets, breakdown by lifecycle state (Active / Deprecated / Contested), distinct subjects, distinct predicates, contested keys, and the most recent ingest timestamp. Read-only.
nuggetindex judge-replay ~/.nuggetindex/judge_log.jsonlReads the structured log the conflict detector wrote when it called the LLM judge to break a tie, groups by predicate and decision, and prints a per-bucket summary. Useful for sanity-checking that the judge isn't biased toward one source.
nuggetindex query "CEO Apple" --db my_index.db --time 2010-06-01Hybrid (BM25 + optional dense) retrieval against my_index.db,
filtered to facts whose [start, end) validity contains
2010-06-01. With --time omitted, retrieves with query_time=now.
Prints the top-K nuggets with their lifecycle state and provenance.
nuggetindex resolve --store my_index.dbWalks every (subject, predicate) key in my_index.db that has at
least one Contested member, renders the rival objects with their
evidence + sources + validity intervals, and prompts you to pick a
winner (or skip / leave / suppress-all). The chosen nugget becomes
Active + Preferred; the losers become Deprecated. Decisions are
logged to ~/.nuggetindex/resolve_log.jsonl.
nuggetindex review ~/.nuggetindex/deferred.jsonlThe extractor defers low-confidence triples to a JSONL queue instead of admitting them to the store. This command groups the queue by confidence bucket and predicate so you can decide which ones to accept, edit, or drop in bulk.
nuggetindex schema discover ./my_corpus --out my_schema.yamlReads ./my_corpus, clusters surface-form predicates by frequency
and entity-type co-occurrence, and writes a starter schema YAML
(predicate names, cardinality, expected types) you can edit before
ingest. Good first step when adapting nuggetindex to an unfamiliar
domain.
nuggetindex seeds propose ./my_corpus --top-k 50Greedy facility-location selection over ./my_corpus to surface 50
seed queries that maximally cover the corpus's topic space. Used
to bootstrap an offline build when you don't have a query log to
draw from.
nuggetindex serve --db my_index.db --port 8080Boots a FastAPI server on port 8080 with endpoints for retrieval, audit, doctor scorecards, and (optionally) the resolve workflow. Useful when your generator lives in a non-Python service or when you want a multi-tenant deployment.
https://nuggetindex.searchsim.org/ — a working showcase of how nuggetindex can be built and run on top of your existing RAG system.
@inproceedings{zerhoudi2026nuggetindex,
title = {{NuggetIndex}: Governed Atomic Retrieval for Maintainable {RAG}},
author = {Zerhoudi, Saber and Granitzer, Michael and Mitrovi{\'c}, Jelena},
booktitle = {Proceedings of the 49th International ACM SIGIR Conference
on Research and Development in Information Retrieval (SIGIR '26)},
year = {2026},
doi = {10.48550/arXiv.2604.27306},
url = {https://arxiv.org/abs/2604.27306},
}- Source: https://github.com/searchsim-org/nuggetindex
- Live demo: https://nuggetindex.searchsim.org/
- Paper (arXiv): https://arxiv.org/abs/2604.27306
- Issues: https://github.com/searchsim-org/nuggetindex/issues
MIT. See LICENSE.