인공지능 모델의 성능의 80%는 데이터의 품질에 달려있다는 말이 과언이 아닐 정도로 모델의 성능에 있어서 데이터는 매우 중요한 역할을 한다. 데이터셋이 부족한 경우 underfitting이나 overfitting과 같은 문제가 발생할 수 있다. 따라서, 이 연구의 목적은 GAN을 사용하여 다양한 데이터를 생성하는 것을 목적으로 한다. 먼저, CycleGAN을 활용한 Data Augmentation 기법을 통해 제한된 도메인의 데이터 셋을 기반으로 다른 도메인 영역의 데이터 셋을 생성하여 인공지능 모델의 성능을 향상시키고 일반화하는 연구를 진행하였다. 또한 다른 X-ray 데이터셋을 이용해 다양한 생성모델을 사용하여 X-ray 데이터를 생성한 후 결과를 분석하였다. 마지막으로, 첫 번째 연구에서 진행한 Snow CycleGAN에 생성을 무효화 시키는 nullifying attack을 적용해보았다.

9000장의 VFP290K와 200장의 눈 데이터인 dawn를 사용해 CycleGAN을 학습시켰다. datasets 폴더에 눈 데이터셋과 VFP290K 데이터셋을 형식에 맞게 넣은 다음 코드를 실행하였다.
python train.py --dataroot ./datasets/snow --name snow_cyclegan --model cycle_gan
학습된 모델을 이용해서 VFP290K의 전체 데이터를 추론하였고, 총 294713장의 데이터가 생성되었다.
원본이미지:

잘 생성된 경우:
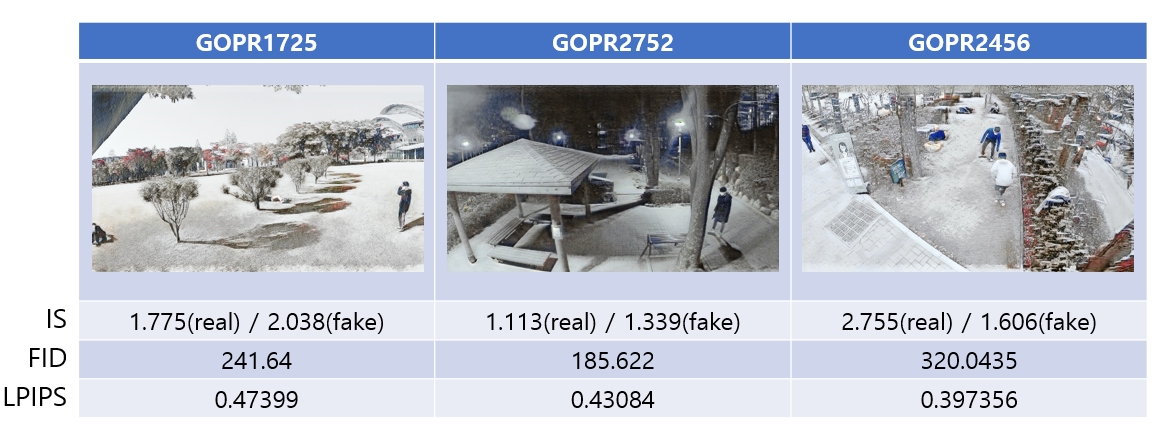
못 생성된 경우:
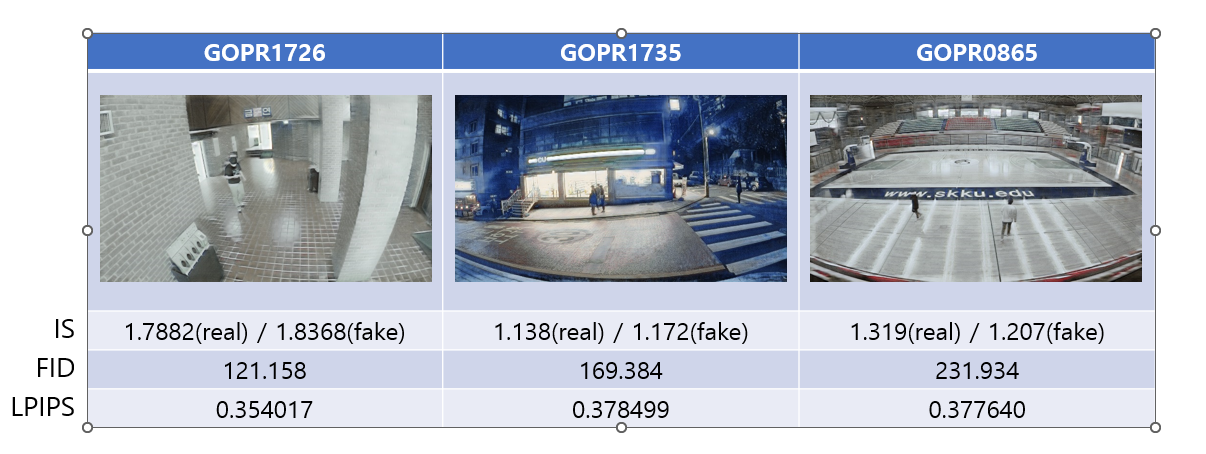
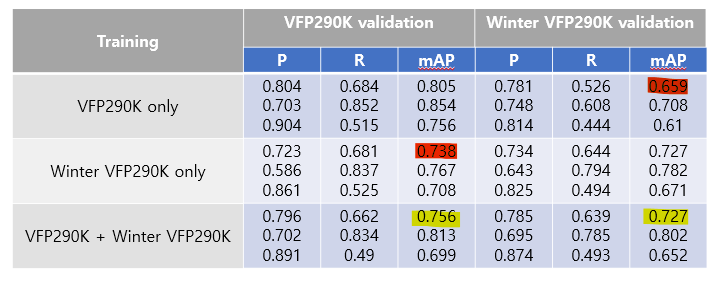
그리고 이렇게 생성된 데이터셋들을 바탕으로 YOLOv5를 학습시켰다. 총 세 가지에 대해서 학습을 시켰는데, vfp290k만 학습시킨 것, winter vfp290k만 학습시킨 것, 그리고 두 종류의 데이터를 섞어서 학습시킨 것이다. 학습시킨 데이터 셋과 다른 데이터를 이용해 성능을 측정했을 때, 성능이 안 좋았지만, 두 데이터를 함께 학습시킨 모델에서 성능향상을 보였다.
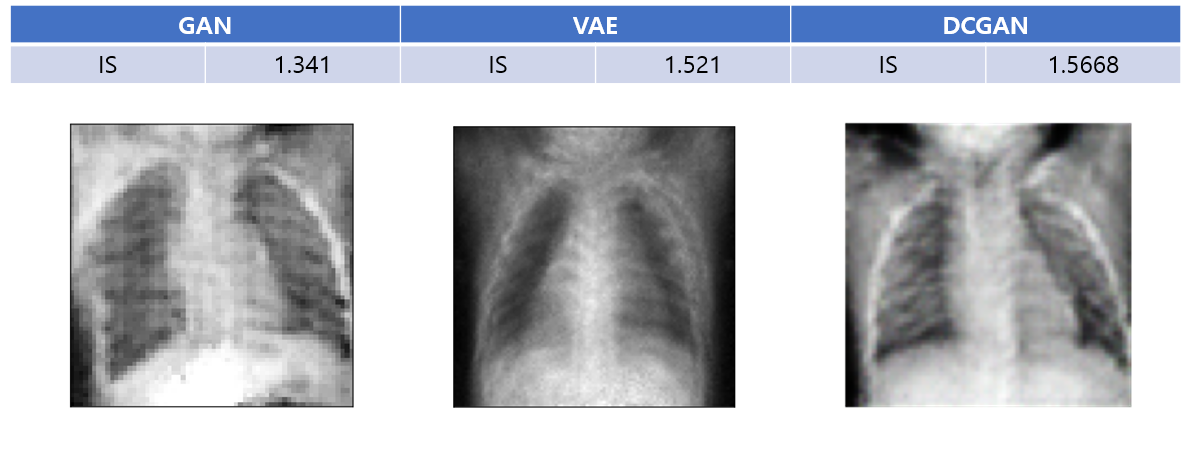
Kaggle에서 제공해주는 데이터셋인 chest X-ray 이미지를 가지고 총 1341장을 사용해 흉부 x선 이미지를 학습시켰다. 모델은 세 가지 생성모델인, GAN, DCGAN, VAE를 사용하였다. 학습 이후 30장의 X-ray 이미지를 생성한 후 IS를 측정해보았다. DCGAN이 성능이 가장 좋았으며 VAE는 아무래도 autoencoder를 사용하다보니 생성된 사진이 흐릿한 경향이 있었다.
- 학습은 각 모델에 따른 jupyter notebook 참고
1번에서 학습한 Snow CycleGAN에 nullifying attack을 적용해 보았다.
python main.py --taskname snow --gid 0
